运行大型语言模型 (LLM)(如 ChatGPT 和 Claude)通常涉及将数据发送到 OpenAI 和其他 AI 模型提供商管理的服务器。虽然这些服务是安全的,但一些企业更愿意将数据完全离线,以保护更大的隐私。
本文介绍了开发人员可以用来在本地运行和测试 LLM 的六大工具,确保他们的数据永远不会离开他们的设备,类似于端到端加密保护隐私的方式。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
0、为什么要使用本地 LLM?
当用户使用 LM Studio 等工具运行本地 LLM 时,它不会收集用户数据或跟踪用户的操作。它允许你的所有聊天数据都保留在本地机器上,而无需与 AI/ML 服务器共享。
根据你的具体用例,可以选择几个离线 LLM 应用程序。其中一些工具完全免费用于个人和商业用途。其他可能需要向他们发送商业用途请求。有几种本地 LLM 工具可用于 Mac、Windows 和 Linux。以下是可以选择的六种最佳工具。
1、LM Studio
LM Studio 可以运行任何格式为 gguf 的模型文件。它支持来自模型提供商(如 Llama 3.1、Phi 3、Mistral 和 Gemma)的 gguf 文件。要使用 LM Studio,请访问上面的链接并为您的机器下载应用程序。启动 LM Studio 后,主页会显示要下载和测试的顶级 LLM。还有一个搜索栏,用于过滤和下载来自不同 AI 提供商的特定模型。
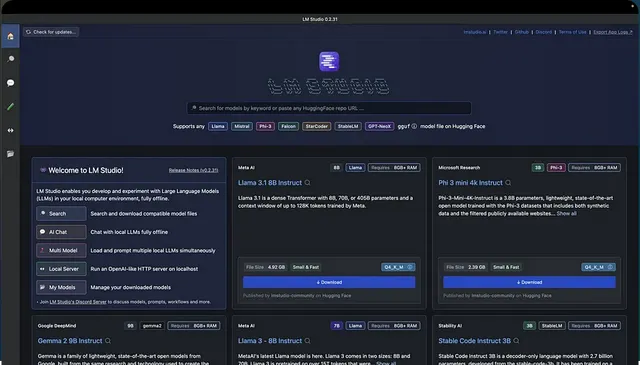
搜索特定公司的模型会显示几种模型,从小到大量化。根据您的机器,LM Studio 使用兼容性猜测来突出显示可在该机器或平台上运行的模型。
1.1 LM Studio 的主要功能
LM Studio 提供与 ChatGPT 类似的功能和特性。它有几个功能。以下重点介绍了 LM Studio 的主要功能。
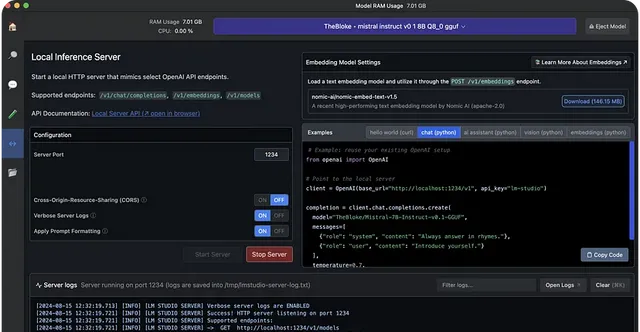
本地服务器提供示例 Curl 和 Python 客户端请求。此功能有助于使用 LM Studio 构建 AI 应用程序以访问特定的 LLM。
# Example: reuse your existing OpenAI setupfrom openai import OpenAI# Point to the local serverclient = OpenAI(base_url="http://localhost:1234/v1", api_key="lm-studio")completion = client.chat.completions.create( model="TheBloke/Mistral-7B-Instruct-v0.1-GGUF", messages=[ {"role": "system", "content": "Always answer in rhymes."}, {"role": "user", "content": "Introduce yourself."} ], temperature=0.7,)print(completion.choices[0].message)
使用上述示例 Python 代码,你可以重复使用现有的 OpenAI 配置并修改基本 URL 以指向你的本地主机。
1.2 使用 LM Studio 的好处
LM Studio可免费供个人使用,它允许开发人员通过应用内聊天 UI 和游乐场运行 LLM。它提供了一个带有过滤器的华丽且易于使用的界面,并支持连接到 OpenAI 的 Python 库,而无需 API 密钥。
公司和企业可以根据要求使用 LM Studio。但是,它需要 M1/M2/M3 Mac 或更高版本,或带有支持 AVX2 处理器的 Windows PC。Intel 和 AMD 用户只能使用 v0.2.31 中的 Vulkan 推理引擎。
2、Jan
Jan 是 ChatGPT 的开源版本,旨在离线运行。它由一个秉承用户所有理念的用户社区构建。Jan 允许你在设备上运行 Mistral 或 Llama 等流行模型,而无需将其连接到互联网。使用 Jan,你可以访问 OpenAI 和 Groq 等远程 API。
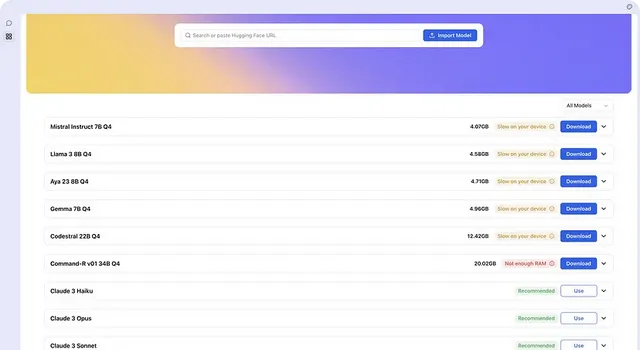
2.1 Jan 的主要功能
Jan 是一款电子应用程序,功能类似于 LM Studio。它通过将消费机器转变为 AI 计算机,使 AI 开放并可供所有人使用。由于它是一个开源项目,开发人员可以为其做出贡献并扩展其功能。
以下细分了 Jan 的主要功能。
2.2 使用 Jan 的好处
Jan 提供了一个干净简单的界面来与 LLM 交互,它将你的所有数据和处理信息保存在本地。它已经安装了 70 多个大型语言模型供你使用。这些现成的模型的可用性使得连接和与 OpenAI 和 Mistral 等远程 API 交互变得容易。Jan 还有一个很棒的 GitHub、Discord 和 Hugging Face 社区可以关注和寻求帮助。
但是,与所有 LLM 工具一样,这些模型在 Apple Silicon Mac 上的运行速度比在 Intel 上更快。
3、Llamafile
Llamafile 由 Mozilla 支持,其目标是通过快速 CPU 推理(无需网络访问)支持开源 AI,并使每个人都能访问开源 AI。它将 LLM 转换为多平台可执行链接格式 (ELF)。它允许你仅使用单个可执行文件运行 LLM,从而提供将 AI 集成到应用程序中的最佳选项之一。
3.1 Llamafile 的工作原理
它旨在将权重转换为多个可执行程序,这些程序无需安装即可在 Windows、MacOS、Linux、Intel、ARM、FreeBSD 等架构上运行。在底层,Llamafile 使用 tinyBLAST 在 Windows 等操作系统上运行,而无需 SDK。
3.2 Llamafile 的主要功能
访问或制作模型:你可以访问 OpenAI、Mistral、Groq 等流行的 LLM。它还支持从头开始创建模型。
3.3 开始使用 Llamafile
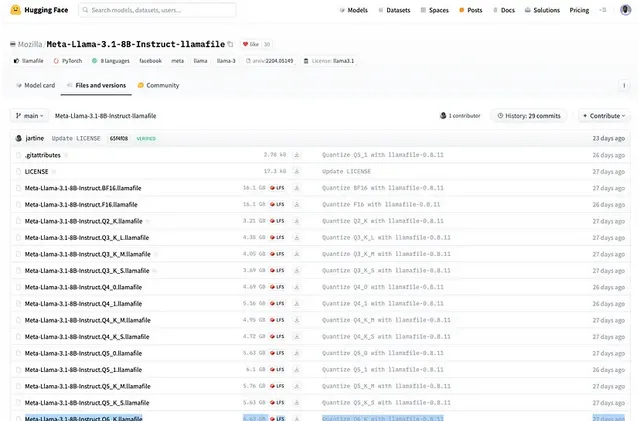
要安装 Llamafile,请前往 Huggingface 网站,从导航中选择「模型」,然后搜索 Llamafile。你也可以从这个 URL 安装你喜欢的量化版本。
注意:量化数越大,响应越好。如上图所示,本文使用 Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile,其中 Q6 代表量化数。
步骤 1:下载 Llamafile
从上面的链接中,单击任意下载按钮以获取你喜欢的版本。如果你的机器上安装了 wget 实用程序,则可以使用以下命令下载 Llamafile。
wget https://huggingface.co/Mozilla/Meta-Llama-3.1-8B-Instruct-llamafile/blob/main/Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile
你应该将 URL 替换为喜欢的版本。
步骤 2:使 Llamafile 可执行
下载特定版本的 Llamafile 后,你应该使用以下命令通过导航到文件的位置使其可执行。
chmod +x Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile
步骤 3:运行 Llamafile
在文件名前面添加句点和斜杠 ./ 以启动 Llamafile。
./Meta-Llama-3.1-8B-Instruct.Q6_K.llamafile
Llamafile 应用程序现在可在 http://127.0.0.1:8080 上运行各种 LLM。
3.4 使用 Llamafile 的好处
Llamafile 通过使 LLM 易于访问消费者 CPU 来帮助实现 AI 和 ML 的民主化。与其他本地 LLM 应用程序(如 Llama.cpp)相比,Llamafile 在游戏电脑上提供最快的即时处理体验和更好的性能。由于它具有更快的性能,因此它是总结长文本和大型文档的绝佳选择。它 100% 离线且私密地运行,因此用户不会将数据共享给任何 AI 服务器或 API。
Hugging Face 等机器学习社区支持 Llamafile 格式,因此可以轻松搜索与 Llamafile 相关的模型。它还有一个很棒的开源社区,可以进一步开发和扩展它。
4、GPT4ALL
GPT4ALL 建立在隐私、安全和无需互联网的原则之上。用户可以在 Mac、Windows 和 Ubuntu 上安装它。与 Jan 或 LM Studio 相比,GPT4ALL 的每月下载量、GitHub Stars 和活跃用户更多。
4.1 GPT4ALL 的主要功能
GPT4All 可以在主要的消费硬件上运行 LLM,例如 Mac M 系列芯片、AMD 和 NVIDIA GPU。以下是其主要功能。
4.2 开始使用 GPT4All
要开始使用 GPT4All 在本地运行 LLM,请下载适用于你的操作系统的所需版本。
4.3 使用 GPT4ALL 的好处
除了 Ollama 之外,GPT4ALL 拥有最多的 GitHub 贡献者,每月活跃用户约为 250000 名(参考nomic数据)。该应用程序收集有关使用情况分析和聊天共享的匿名用户数据。但是,用户可以选择加入或退出。
使用 GPT4ALL,开发人员可以从其庞大的用户群、GitHub 和 Discord 社区中受益。
5、Ollama
使用 Ollama,你可以轻松创建本地聊天机器人,而无需连接到 OpenAI 等 API。由于一切都在本地运行,因此无需支付任何订阅或 API 调用费用。
5.1 Ollama 的主要功能
5.2 开始使用 Ollama
首次使用 Ollama 时,请访问 https://ollama.com 并下载适用于您机器的版本。您可以在 Mac、Linux 或 Windows 上安装它。安装 Ollama 后,您可以使用以下命令在终端中查看其详细信息。
ollama
要运行特定的 LLM,您应该使用以下命令下载它:
ollama pull <modelname>
其中 <modelname> 是你要安装的模型的名称。在 GitHub 上查看 Ollama 以获取一些示例模型以供下载。pull 命令也用于更新模型。一旦使用它,只会获取差异。
下载例如 llama3.1 后,在命令行中运行 ollama run llama3.1 即可启动该模型。
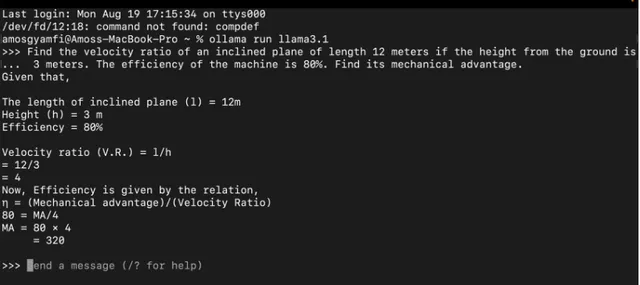
在上面的例子中,我们提示 llama3.1 模型解决物理工作和能量问题。
5.3 使用 Ollama 的好处
Ollama 在 GitHub 上有超过 200 名贡献者,并且积极更新。在上面讨论的其他开源 LLM 工具中,它拥有最多的贡献者,并且可扩展性更强。
6、LLaMa.cpp
LLaMa.cpp 是底层后端技术(推理引擎),为 Ollama 等本地 LLM 工具提供支持。Llama.cpp 支持大量大型语言模型推理,配置最少,在各种硬件上具有出色的本地性能。它也可以在云中运行。

6.1 LLaMa.cpp 的主要功能
6.2 开始使用 LLaMa.cpp
要使用 llama.cpp 运行你的第一个本地大型语言模型,应该使用以下命令安装它:
brew install llama.cpp
接下来,从 Hugging Face 或任何其他来源下载您想要运行的模型。例如,从 Hugging Face 下载Mistral模型并将其保存在你的机器上的某个位置。
使用你喜欢的命令行工具(如终端),进入您刚刚下载的 .gguf 模型文件的位置并运行以下命令:
llama-cli --color \ -m Mistral-7B-Instruct-v0.3.Q4_K_M.ggufb \ -p "Write a short intro about SwiftUI"
总之,您首先调用 LLaMa CLI 工具并设置颜色和其他标志。-m 标志指定您要使用的模型的路径。-p 标志指定您希望用来指示模型的提示。
运行上述命令后,您将在以下预览中看到结果。
7、本地LLM的典型用例
在本地运行 LLM 可以帮助想要了解其性能及其详细工作原理的开发人员。本地 LLM 可以查询私人文档和技术论文,以便有关这些文档的信息不会离开用于查询它们的设备,而流向任何云 AI API。本地 LLM 在没有互联网的地方和网络接收较差的地方很有用。
在远程医疗环境中,由于隐私问题,本地 LLM 可以对患者文档进行排序,而无需将其上传到任何 AI API 提供商。
在本地使用大型语言模型之前了解其性能对于获得所需的响应至关重要。有几种方法可以确定特定 LLM 的性能。以下是几种方法。
要回答上述问题,你可以查看 Hugging Face 和 Arxiv.org 等优秀资源。此外,Open LLm Leaderboard 和 LMSYS Chatbot Arena 为各种 LLM 提供了详细信息和基准。
8、结束语
正如本文所讨论的,选择和本地使用大型语言模型有多种动机。如果你不希望通过互联网将数据集发送给 AI API 提供商,您可以微调模型以在远程医疗应用程序中执行专门的任务。许多开源图形用户界面 (GUI) 本地 LLM 工具(如 LLm Studio 和 Jan)提供了直观的前端 UI,用于配置和试验 LLM,而无需像 OpenAI 或 Claude 这样的基于订阅的服务。您还发现了各种强大的命令行 LLM 应用程序,如 Ollama 和 LLaMa.cpp,它们可帮助您在本地运行和测试模型,而无需互联网连接。查看 Stream 的 AI Chatbot 解决方案,将 AI 聊天集成到您的应用程序中,并访问所有相关链接以了解更多信息。
原文链接:Top 6大模型本地运行工具 - BimAnt











