编辑:庸庸 乔杨
【新智元导读】谷歌研究人员对200篇关于生成式AI滥用的新闻报道进行了研究,发现生成式AI造成的虚假信息正在互联网上泛滥成灾。但最讽刺的是,谷歌正是这些虚假信息的重要制造商之一。
谷歌研究人员发表了一篇新论文,警告生成式人工智能正在用虚假内容毁掉互联网。
这极具讽刺意味,因为倘若互联网真的在被GenAI所荼毒,谷歌自己也「功不可没」——它是世界上最大的构建、部署和推广GenAI的公司之一。
广为人知的是,其之前在搜索页面推出的AI概述功能,居然出现了「披萨上涂胶水」「吃石头」之类令人啼笑皆非的离谱建议,后来谷歌不得不手动删除这些错误信息。
这篇论文由谷歌人工智能研究实验室DeepMind、安全智囊团Jigsaw和慈善机构Google.org的研究人员共同撰写,他们深入调查了关于生成式人工智能的研究报告,以及约200篇关于生成式人工智能滥用的新闻报道,对生成式AI工具被滥用的不同方式进行了分类。

论文地址:https://arxiv.org/abs/2406.13843
最终得出结论:在现实世界的滥用案例中,篡改人类肖像和伪造证据是最普遍的。这么做的意图也很明确,无非是为了影响公众舆论、诈骗,或牟取利益。
奥特曼和马斯克都曾经警告过AGI可能会带来「生存性风险」,但谷歌这次的研究重点是生成式人工智能。
生成式人工智能的风险虽然还没有上升到「威胁生存」的地步,但是却更加迫近——这是当下正在发生的事情,而且未来可能会变得更糟。
因为这种技术让任何人都可以轻松地生成文本、音频、图像和视频,互联网上充斥着伪造或篡改的人工智能生成的内容,「真实与虚假之间的界限被模糊掉了」。
「虚假信息炮制机」是GenAI的宿命?
研究人员发现,大多数GenAI滥用案例都是对系统的正常使用,并没有「越狱」行为,这类「常规操作」占了9成。
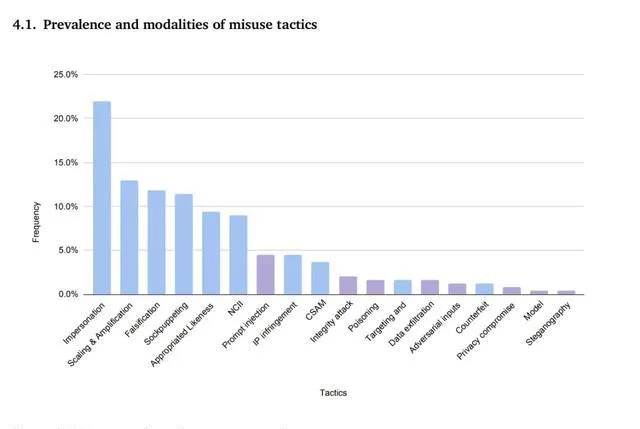
正如研究人员在论文后面所解释的那样,GenAI的广泛可用性、可访问性和超现实性,使得层出不穷的、较低级别的滥用形式成为可能——生成虚假信息的成本实在是太低了!
阅读完这篇论文之后,你可能会情不自禁产生这样的感受:人们并没有滥用GenAI,只不过是按照其产品设计正常使用而已。
人们使用生成式人工智能来制作大量虚假内容,是因为它本来就非常擅长完成这项任务。
很多虚假内容往往既没有明显的恶意,也没有明确违反这些工具的内容政策或服务条款,但其潜在的危害是巨大的。
这一观察结果与404 Media之前的报道不谋而合。
那些利用人工智能冒充他人、扩大不良内容的规模和传播范围,或制作未经同意的私密图片(nonconsensual intimate images,NCII)的人,大多并没有入侵或操纵他们正在使用的人工智能生成工具,他们是在允许的范围内使用这些工具。
很简单就能举出2个例子:
AI工具的「围栏」可以用一些提示巧妙避过,没有什么能阻止用户使用ElevenLabs的人工智能语音克隆工具高度逼真地模仿出同事或明星的声音。
Civitai用户可以创建人工智能生成的名人图像,虽然该平台有禁止NCII的政策,但同样没有什么能阻止用户在自己的机器上使用GitHub上开源的工具(如 Automatic1111 或 ComfyUI)来生成 NCII。
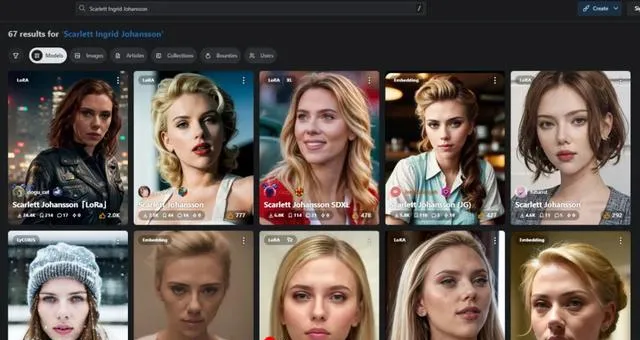
斯嘉丽·约翰逊的头像是DeepFake重灾区
将这些AI生成的内容发到Facebook可能违反了平台的政策,但生成这个行为本身并没有违反他们所使用的人工智能图片生成器的政策。
媒体:GenAI的滥用只是冰山一角
因为谷歌的研究素材大量来自于媒体报道,这就带来了一个问题:这是否会让研究结论带有媒体的偏见?毕竟作为探照灯的媒体,在选题和报道上有自己的偏向。
那些耸人听闻的事件更容易被报道,这可能会导致数据集偏向特定类型的滥用。
404 Media对此做出了回应:虽然媒体确实只能报道它所能证实的事件,但是可以确定的一点是,还有大量的我们尚未意识到的生成式人工智能的滥用没有被报道。
即便是上文提到的用AI生成名人色情图片的情况,被媒体大量揭露,但仍然存在报道不足的问题。
首先是因为这一话题仍是禁忌,有很多出版物不愿报道。
其次是因为媒体只能捕捉到个例,无法始终关注事件的整体和后续,404 Media的一名编辑写道:

在我联系Patreon官方作出回应(之后发言人关闭了他的账户)之前,我写过一篇报道,关于一个用户在Patreon上通过 NCII 盈利,他制作了53190张未经同意的名人图片。那篇报道中还提到了另外两名NCII制作者,之后我又发现了其他人。
泰勒·斯威夫特在推特上疯传的人工智能生成的裸体图片就是在Telegram和4chan社区首次分享的,在一月份那篇报道爆出前后,这些社区都很活跃,从那以后,他们每天都在发布NCII。
我和其他记者不会对每一张图片和创作者都进行报道,因为如果这样做,我们就没有时间做其他事情了。
当虚假信息泛滥,甩锅给AI变得很容易
让我们做一个推演,当互联网上充斥着人工智能生成的内容,会发生什么?
最直接的后果是,互联网上的混乱状况会对人们辨别真假的能力带来巨大的考验,我们将陷入一种经常性的怀疑,「这是真的吗」?
在互联网刚刚出现的时代,流行的一句话是,「你不知道网线那头是人是狗」,现在这种趋势愈演愈烈了,人们被虚假的人工智能生成内容所淹没,越来越疲于应对。
如果不加以解决,人工智能生成的内容对公开数据的污染还可能会阻碍信息检索,扭曲对社会政治现实或科学共识的集体理解。
而且,这可能会成为一些知名人物的「挡箭牌」,在某些情况下,他们能够将对自己不利的证据解释为人工智能生成的,轻巧地将举证的责任转移出去。
对于生成式AI所带来的虚假内容的泛滥,谷歌起到了推波助澜的作用,甚至可以说是「始作俑者」也不为过,多年前射出的子弹,今日终于击中了自己的眉心。
参考资料:
https://arxiv.org/abs/2406.13843
https://futurism.com/the-byte/google-researchers-paper-ai-internet











