存算一体:GPU大型计算系统

1.存算一体技术在GPU领域的落地通道已被产业巨头打通,加速了其应用部署。
2.采用20nm工艺结合HBM-PIM,仅需7nm集群即可实现2.5倍的计算性能提升,大幅超越未使用HBM-PIM的传统HBMGPU。:产业巨头已经打通存算一体技术的落地通道,存算一体技术加快应用部署。与未使用HBM-PIM(HBM-PIMGPU v.s. HBM GPU)相比,仅用20nm工艺就使7nm集群计算性能提升了2.5倍。
三星电子引领数字存内处理新时代,打造高效计算系统。HBM-PIMGPU系统搭载世界上第一个基于数字存内处理的芯片,性能大幅提升。这一革命性创新赋能人工智能、机器学习等领域,带来更强大的计算能力。三星电子在计算技术领域再创辉煌,引领行业发展。12 月12日宣布,他们开发了世界上第一个基于数字存内处理(PIM,也可称存内计算或存算一体)芯片(HBM-PIM)的GPU的大规模计算系统。

三星电子揭示存算一体技术的新进展
在2022人工智能(AI)半导体未来技术大会上,三星电子高等技术研究院人工智能研究中心副主任崔昌圭分享了新计算技术的发展。
他们构建了一个大型计算系统,组合了96个来自AMD的GPU,每个GPU加载一个HBM-PIM芯片,展示了存内处理(PIM)芯片的性能。存算一体技术显著减少数据在CPU和DRAM之间的移动频次,提升性能。
该技术有望在人工智能、高性能计算、边缘计算等领域带来广阔的应用前景。ChoiChang-kyu)在由三星电子主办的2022人工智能(AI)半导体未来技术大会上通过主题演讲披露了新计算技术的发展。他们通过组合来自AMD的96个GPU(MI100)构建了一个大型计算系统,每个GPU都加载了一个HBM-PIM芯片,并成功展示了存内处理(PIM)芯片的性能。这是一种存算一体技术,可以显著减少数据在CPU和DRAM之间移动的频度并提升性能。

存算一体技术超越传统冯诺依曼架构
PIM:内存计算技术的突破
PIM(Processing-In-Memory)将计算单元与随机存取存储器(DRAM)集成在单个芯片上,这项技术有望有助于提高庞大的人工智能(AI)的性能。
三星推出了严格意义上的芯片内数字近存计算,在HBM-PIM芯片的每个存储块中均包含一个内部处理单元,与其他公司HBM实现不同,该技术旨在提升AI计算性能。是指将计算单元与随机存取存储器(DRAM) 集成在单个芯片上。这项技术有望有助于提高庞大的人工智能(AI)的性能。三星使了严格意义上的芯片内数字近存计算来提升AI计算性能。三星HBM-PIM芯片与其他公司HBM实现的不同之处在于,PIM芯片上的每个存储块内都包含一个内部处理单元。
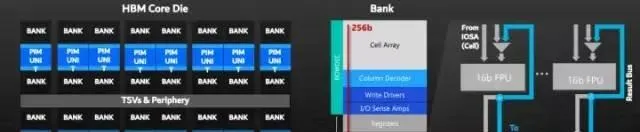
三星HBM-PIM阵列架构
*基于存算一体技术的20nmHBM-PIM(DRAM工艺)大大提升GPU性能。
*与7nmGPU相比,20nmHBM-PIM实现了2.5倍的性能提升。
*这一突破性技术将为高性能计算、人工智能和图形处理等领域带来变革。20nmHBM-PIM(DRAM工艺)使得7nmGPU性能增强2.5倍
三星在去年ISSCC发布的学术文章披露了其HBM-PIM技术,该技术采用三星20nmDRAM工艺,将负责计算的PCU与DRAM阵列集成在同一晶圆平面内。性能提升主要归功于存算一体技术,而非3D堆叠封装。
仅使用20nm工艺的PCU进行简单的逻辑计算,便使7nm工艺GPU集群的性能提升到2.5倍。这意味着,通过将计算和存储集成在同一个芯片上,可以显著提升性能。
此外,这种设计还具有功耗低、面积小的优点,非常适合应用于高性能计算和人工智能领域。
三星的HBM-PIM技术有望成为下一代高性能存储器的主流技术之一。ISSCC发布的学术文章信息披露,该HBM-PIM使用的是三星的20nmDRAM工艺。负责计算的PCU与DRAM阵列在同一个晶圆平面内,显著性能提升主要来自存算一体技术而非3D堆叠封装。仅用20nm工艺的PCU进行简单的逻辑计算(DRAM工艺做逻辑计算其实不划算,外周的逻辑晶体管的实际栅长在32nm附近),就使得7nm工艺GPU集群的性能提升到2.5倍。
三星电子开发了一种名为PIM(Processing-In-Memory)的尖端技术,在提升AI计算性能的同时,大幅降低能耗。
该系统训练语言模型算法T5 时,性能提升了2.5 倍,功耗降低了2.67 倍。配备HBM-PIM 的GPU加速器一年的能耗下降了约2,100GWh,相当于减少960,000吨碳排放。
三星表示,该技术将对能源消耗和环境具有重大影响,可减少集群的年能源使用量,减少碳排放。T5(Text-to-TestTransfer Transformer)时,与未使用PIM时相比,性能提升了2.5倍,功耗降低了2.67倍。与仅配备HBM 的GPU加速器相比,配备HBM-PIM 的GPU加速器一年的能耗下降了约2,100GWh。三星表示,其PIM技术将对能源消耗和环境具有重大影响,可将集群的年能源使用量减少,相当于减少960,000吨碳排放。

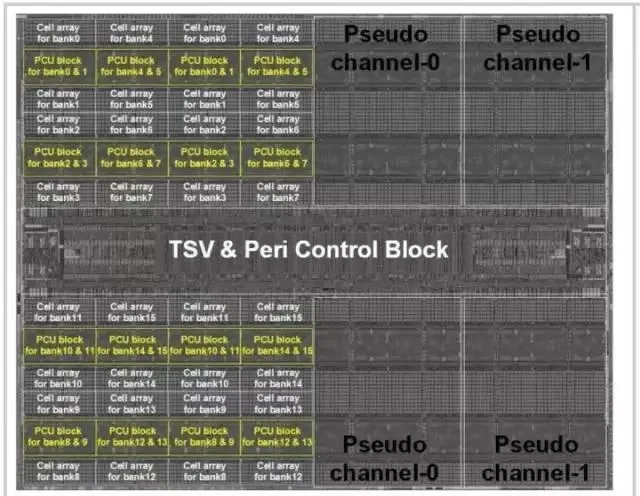
三星HBM-PIM架构图
三星利用CXL开放标准,连接高速处理器与设备或内存,优化处理器与加速器之间的协同作业。该技术提高了处理器与内存的交互效率,从系统层面提升性能,让用户对关键应用的体验更加流畅顺畅。CXL(ComputeExpress Link)开放标准,用于高速处理器到设备和处理器到内存的接口,从而可以更有效地使用与处理器一起使用的内存和加速器。
CXL 与PNM的强强联合,推动内存容量扩展新纪元
CXL的出现为内存容量扩展带来了革命性的改变。它能够与其他技术,例如Processing-near-Memory(PNM) 协同工作,实现内存容量的突破性增长。
CXL与PNM的有机结合,为数据密集型应用提供了强有力的支持,在AI、5G通信、云计算等领域展现出巨大的潜力。
CXL与PNM的联手,不仅提升了计算性能,更使内存容量实现了前所未有的扩展。这将为企业带来更强大、更灵活的IT基础设施,激发创新潜能,开创崭新未来。可以与其他技术结合使用,例如 Processing-near-Memory (PNM),以帮助促进内存容量扩展。
PNM是一种新型的计算架构,它通过使用内存进行数据计算来减少CPU和内存之间的数据移动。与PIM 相比,PNM的计算功能在更靠近内存的位置执行,从而减少了CPU和内存数据传输之间的瓶颈。这使得PNM具有更快的计算速度和更高的能效。PIM一样,它通过使用内存进行数据计算来减少CPU和内存之间的数据移动。在PNM的情况下,计算功能在更靠近内存的地方执行,以减少CPU和内存数据传输之间发生的瓶颈。
三星在AI领域取得重大突破,推出搭载CXL 的PNM技术。该技术可显著提升内存带宽,在推荐系统和内存数据库等应用中,性能提升高达一倍。
三星PNM 技术采用CXL接口,可无缝连接服务器和加速器,实现内存带宽的大幅提升,有效解决AI模型处理中面临的内存瓶颈问题。
在测试中,基于CXL 接口的PNM系统在推荐系统和内存数据库等应用中性能翻倍,展现出强大的处理能力和高效的解决方案。CXL 的PNM技术,用于高容量AI模型处理。在测试中,基于CXL 接口的PNM系统在推荐系统或需要高内存带宽的内存数据库等应用中性能翻倍。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-











