引言:探索大型语言模型中低秩适应的新方法
在自然语言处理领域,大语言模型(LLMs)的迅猛发展带来了前所未有的性能提升。然而,随之而来的是模型参数数量的激增,这不仅导致了调优成本的线性增长,也给在常规硬件上进行微调带来了挑战。为了解决这一问题,研究者们提出了一系列 参数高效的调优方法 ,如LoRA,它们通过只调整模型中一小部分参数来实现与全参数微调相当的性能。尽管这些方法能够降低约30%的GPU内存需求,但仍需要计算梯度和进行反向传播,这对于大语言模型的使用和部署提出了挑战。
近期,研究者们开始探索 无导数优化(derivative-free optimization, DFO)方法 ,以避免梯度计算,并在少量样本(few-shot)设置中展示出更强的鲁棒性。本文提出了一种新的无导数优化方法,通过在每个自注意力层前置低秩模块,并交替使用两种无导数优化方法来优化这些低秩模块。实验结果表明,与现有的基于梯度的参数高效调优方法和无导数优化方法相比,该新方法在各种任务和语言模型上都取得了显著的改进,并在内存使用和收敛速度方面展现了明显的优势。
论文标题:
Derivative-Free Optimization for Low-Rank Adaptation in Large Language Models
低秩适应(LoRA)的挑战与衍生无导数优化方法的诞生
低秩适应(LoRA)是一种参数高效的调优方法,它通过调整模型参数的一小部分来实现与模型调优相当的性能。然而,这一过程仍然需要 大量的计算资源 ,因为它涉及到计算梯度并在整个模型中进行反向传播。
近年来,研究人员开始尝试使用无导数优化方法来避免计算梯度,并在少量样本设置中展示出更高的鲁棒性。本文的研究者们将低秩模块插入到模型的每个自注意力层,并交替使用两种无导数优化方法来优化这些低秩模块。在各种任务和语言模型上的广泛结果表明,此方法在内存使用和收敛速度方面与现有基于梯度的参数高效调优方法和无导数优化方法相比,都有显著的改进。
目前,利用大语言模型的主流方法是通过上下文学习,将模型视为一项服务。这种方法 只涉及前向计算 ,并且需要设计适当的提示或演示,而不更新模型参数。然而,上下文学习需要精心选择提示和演示,模型的性能完全依赖于所选的提示和演示。
本文研究者考虑到直接使用无导数方法在高维空间中优化每层的所有低秩模块可能会减慢收敛速度,于是采用了分而治之的策略。分别优化每层的低秩模块,并且引入了一个 线性映射矩阵 。该矩阵将无导数优化后获得的参数映射到每层所需的低秩模块。研究者们根据正态分布初始化线性映射矩阵,其标准差与每层的隐藏状态相关。
研究者在 RoBERTa-large、GPT2-large和GPT2-XL 上进行了全面的实验,以评估方法的有效性。结果表明,提出的方法在少量样本设置中平均在七个自然语言理解任务上取得了显著的改进。此外,该方法在GPU内存使用和模型收敛速度方面表现出明显的优势,与现有的无导数优化方法相比性能更优。
方法概述:无导数优化方法与低秩模块的结合
1. 无导数优化方法的基本原理
无导数优化(DFO)算法能够在 不依赖反向传播 的情况下处理复杂问题。通常,这些DFO算法采用采样和更新框架来迭代地增强解决方案。这些算法在各种领域都有广泛的应用,从自动机器学习到强化学习和目标检测等。
代表性的DFO算法包括CMA-ES(协方差矩阵适应进化策略)、Fireworks算法(烟花算法)、遗传算法等。
基于CMA-ES和FWA,研究者提出了两种无导数优化方法用于低秩适应:C-LoRA和F-LoRA。
2. 低秩模块的引入与优化策略
研究者首先将模型设计得接近预训练阶段(例如,保持一致的目标函数),通过将每个输入X转换为包含标记的掩码语言模型(MLM)输入。然后,模型确定用于替换标记的类Y的相应词汇化器。
在低秩适应(LoRA)和黑盒提示调优(BBT)的成功基础上,将低秩矩阵整合到预训练语言模型的每层自注意力模块中。研究者使用无导数优化方法来优化引入的低秩矩阵参数。LoRA模块由两个低秩矩阵组成。在训练过程中,W的参数被冻结,不接收梯度更新,而A和B的参数使用无梯度方法进行更新。
考虑到大语言模型具有低内在维度,研究者进一步使用 两种无梯度优化方法 在低秩空间中优化参数。在语言模型的每层自注意力模块中使用无梯度优化器(例如FWA和CMA-ES)优化向量。然后,这些优化后的向量通过特定的随机投影模块,将其投影到低秩空间。
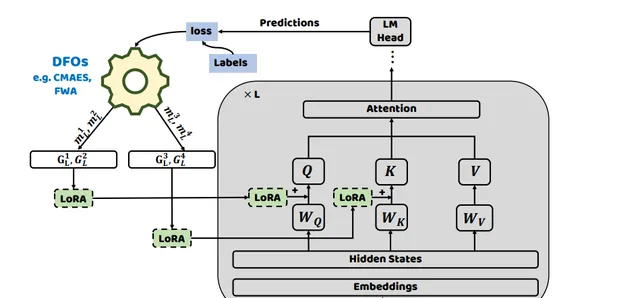
这一过程针对每个模型层分别进行,将优化自注意力层连接的低秩矩阵视为子问题优化过程。受到分而治之方法的启发,研究者采用无梯度优化策略来优化整个模型中引入的参数。
上述模块在模型性能中起着至关重要的作用。研究者分析了 两种不同的初始化方法 :随机初始化与正态分布和使用与BBTv2类似的语言模型每层隐藏状态的分布进行初始化。发现表明,随机初始化与正态分布会导致语言模型性能略有下降,并减慢收敛速度。
因此,研究者使用语言模型每层的隐藏状态分布来对模块进行初始化。这种初始化策略有助于保持模型的性能和收敛速度,从而获得更好的结果。
实验结果:与现有方法的比较
在RoBERTa-large上的实验结果表明,研究者提出的方法在七个自然语言理解任务中的平均表现上取得了显著的改进。与现有的基于梯度的参数高效方法(例如Adapter tuning、LoRA、P-Tuning v2和BitFit)以及无导数优化方法(例如BBT、GAP3和BBTv2)相比,本的方法展现了明显的优势。此外,在 内存使用和模型收敛速度方面 也展现了明显的优势。
讨论:无导数优化方法的优势与局限
1. 内存使用与训练时间的改进
该方法在 单个NVIDIA 3090 GPU上 进行了实验,该GPU具有24GB的内存。实验结果表明,与BBTv2相比,该方法在SST2、AG's News和MRPC上分别提高了8.7分钟、15.4分钟和7.7分钟的收敛速度,这表明该方法具有在大语言模型上应用的潜力,提供了参数高效、内存高效和更快收敛的优势。
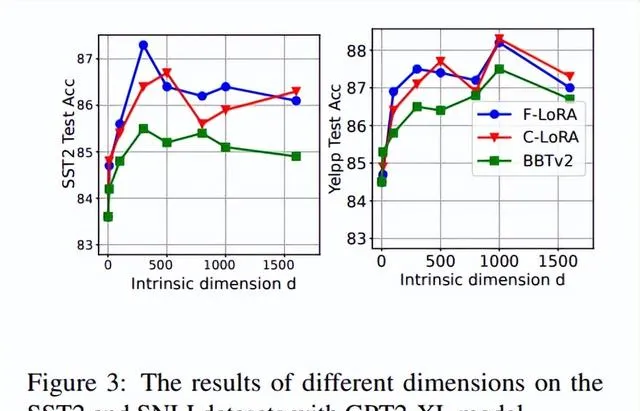
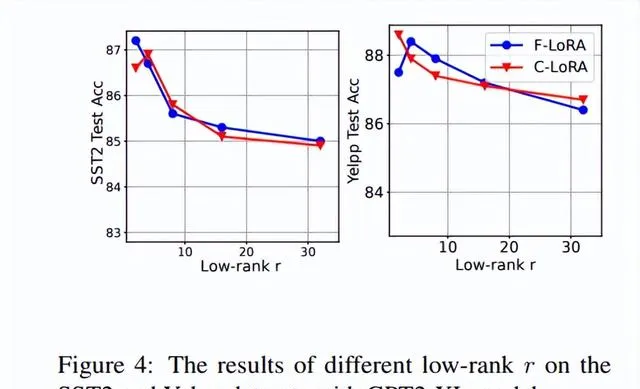
2. 子空间维度与低秩大小对模型性能的影响
在探索子空间维度对方法的影响时,使用GPT2-XL模型在SST2和SNLI数据集上进行了实验。该方法在增加子空间维度时始终优于BBTv2。
在考虑低秩r对提出方法性能的影响时,研究者在GPT2-XL模型上对SST2和Yelpp数据集进行了实验。在使用无导数方法优化时,模型不需要在高维度上进行优化,只需要在低秩r上进行优化即可取得良好的结果。实验中,研究者选择r=2或r=4,允许模型通过引入非常少的参数来实现良好的结果。
结论与未来工作方向
1. 本研究的贡献与意义
本研究的意义在于,它为如何在不计算梯度的情况下有效利用大型语言模型提供了一个有前景的方向。不仅提高了模型的稳定性和收敛速度,而且在GPU内存使用上也更为高效,这使得它在资源受限的环境中尤为有价值。
2. 对未来大型语言模型优化方法的展望
未来的研究可以在多个方向上进一步扩展本研究的工作。













