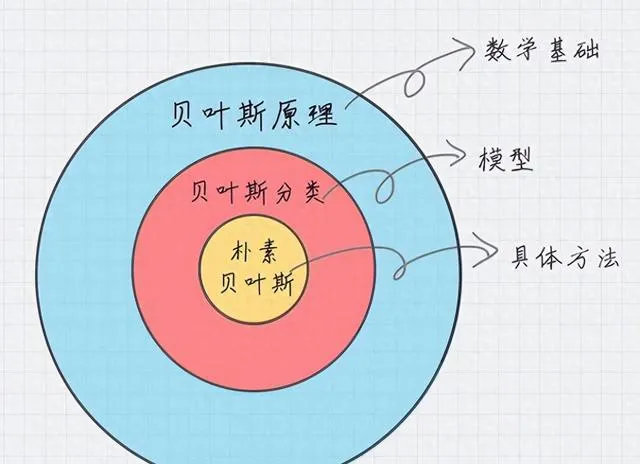
朴素贝叶斯是一种监督式机器学习方法,是概率分类器家族的成员。它使用贝叶斯定理应用了一种朴素的方法。「幼稚」一词的含义是假设每个特征都独立于另一个特征。
条件概率
条件概率是基于另一个事件的发生而发生的事件的概率。
假设调查了我们的同事。谁是IOS的狂热者,谁是热爱Android的替代品?
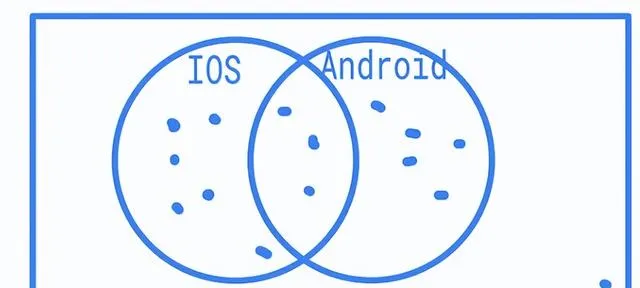
虽然有些人选择了其中任何一个选项,但有两个人优柔寡断,表达了对两者的强烈偏好。与此同时,其他人投了弃权票
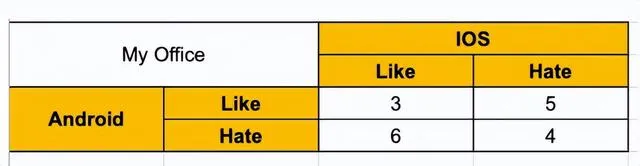
现在让找出喜欢 Android 的人喜欢 IOS 的概率。
在 18 人中,9 人更喜欢 iOS,3 人两者都喜欢。计算条
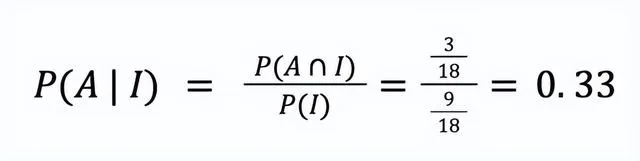
件概率得到的结果为 0.33。
贝叶斯定理
贝叶斯定理以统计学家托马斯·贝叶斯的名字命名。贝叶斯定理的特点是其公式,它有助于根据新信息更新预测或假设。这是通过使用条件概率来实现的。
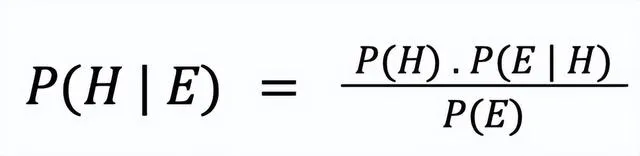
多项式朴素贝叶斯
多项式朴素贝叶斯算法广泛应用于文本分类问题。这种方法使用贝叶斯理论计算每个类别的概率,并返回具有最大概率的类别作为结果。这里的「朴素」一词表示特征间的独立性。也就是说,朴素贝叶斯在评估句子时不考虑单词的顺序。
考虑过滤电子邮件中垃圾邮件的任务。在这种情况下,采用监督学习方法,拥有常规和垃圾邮件的样本。已经计算了这些示例中的单词。例如,在常规电子邮件中,总共有 17 个单词,「亲爱的」这个词出现了 8 次。

计算每个单词的条件概率:
P(Dear|Normal) = 8 / 17 = 0.47
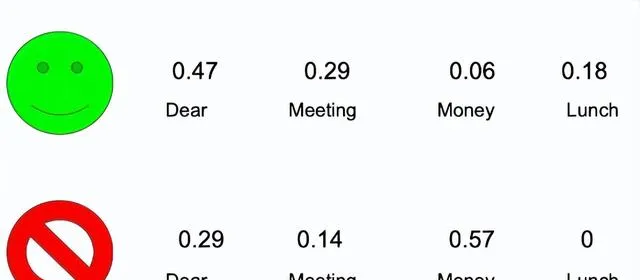
假设我们收到一条新消息,上面写着「午餐会议」:
我们从对这两种情况的初步预测开始。电子邮件正常的概率 P(N) 由正常电子邮件数与训练集中电子邮件总数的比率决定。训练数据中有 8 封普通电子邮件和 4 封垃圾邮件。因此,P(N) = 8 / 12 = 0.67。在这里做出的初步猜测称为先验概率。
P(N) * P(Lunch|N) * P(Meeting|N) = 0.67 * 0.18 * 0.29 = 0.034
可以将 0.034 视为午餐会议在普通邮件中得到的分数。
P(S) * P(Lunch|S)*P(Meeting|S) = 0.33 * 0 * 0.14 = 0
「午餐」一词不会出现在训练数据集中的任何垃圾邮件中。因此,如果电子邮件中存在「午餐」,则无论电子邮件的实际性质如何,其垃圾邮件分数都将自动为零。为了解决这种情况,将一个预定义的数字(表示为 alpha 值)添加到所有样本中。通常,此值设置为 1。

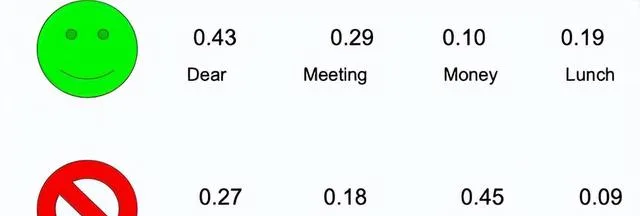
P(N) * P(Lunch|N) * P(Meeting|N) = 0.67 * 0.19 * 0.29 = 0.037
P(S) * P(Lunch|S)*P(Meeting|S) = 0.33 * 0.09 * 0.18 = 0.005
由于普通邮件的分数高于垃圾邮件的分数,因此将邮件归类为正常邮件(0.037 > 0.005)。
高斯朴素贝叶斯
高斯朴素贝叶斯用于连续数据,并利用高斯(正态)分布。
假设有 3 个特征,财富、年龄和每日糖摄入量。试图了解这些人是否喜欢打篮球。我们有每个特征的高斯分布:
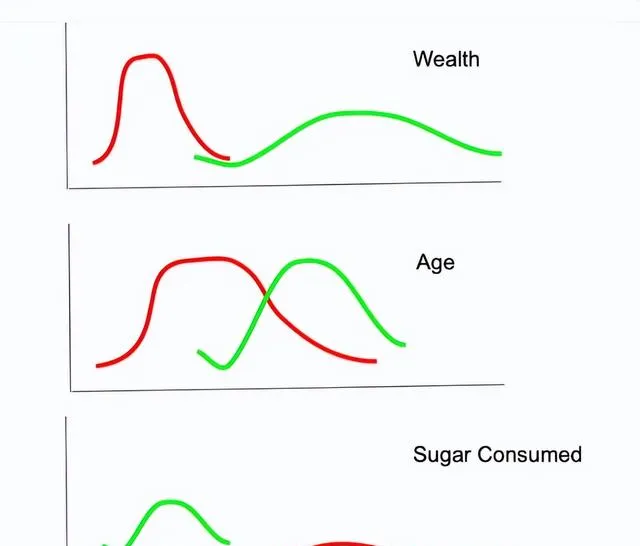
为了做出预测,从最初的猜测开始。我们在训练数据集中有 16 人的数据,其中一半人喜欢打高尔夫球。将预测一个拥有 400 个财富单位、40 个年龄和 25 个糖消费单位的人。(我只是编造了这些数字)。
先验概率:
P(Likes Golf) = 8 / 16 = 0.5
P(~Likes Golf) = 0.5
然后,计算给定人员的每个特征的可能性。
Likes Golf Score = 0.5 * L(Wealth|Likes) * L(Age|Likes)*L(Sugar|Likes)
从高斯正态分布中获得似然值。它是曲线上的 y 轴坐标,对应于 x 轴坐标。
例如,对于Wealth = 400, L(Wealth|Likes) would be 0.06
Likes Golf Score = 0.5 * 0.06 * 0.004 * 0.0…0000000001
为了处理较小的似然值,通常对所有内容进行对数。
ln(Likes Golf Score) = ln(0.5 * 0.06 * 0.004 * 0.0…0000000001)
ln(Likes Golf Score) = ln(0.5) + ln(0.06) + ln(0.004) + ln(0.0…0000000001)
ln(Likes Golf Score) = -124
ln(~(Not)Likes Golf Score) = ln(0.5) + ln(0.0…0000000001) + ln(0.000079) + ln(0.02)
ln(~Likes Golf Score) = -48
鉴于表示不喜欢高尔夫的分数高于喜欢高尔夫的分数,将个人归类为不喜欢打高尔夫球的人。











