随着大型语言模型(LLMs)的快速发展,医学领域的应用也取得了显著进展。但是大多数现有的医学语言模型主要集中在英语语言环境中,限制了其在非英语国家和地区的应用潜力。为了填补这一空白,来自上海交大和上海人工智能实验室的研究团队研发了一个开源的、多语言的医学语言模型,旨在为全球多语言用户提供高质量的医学支持。
这个医学模型的主要贡献包括三个方面。研究团队构建了一个名为MMedC的大规模多语言医学语料库,包含约255亿个标记,涵盖六种主要语言。团队提出了一个名为MMedBench的多语言医学多选问答基准,用于评估不同语言模型在医学领域的表现。最后,团队评估了多种开源大型语言模型,并通过自回归训练进一步提升了这些模型在多语言医学问答任务中的表现,最终模型MMed-Llama 3在多个基准测试中表现优异。
这项研究由上海交通大学和上海人工智能实验室的研究团队共同完成。主要成员包括Pengcheng Qiu, Chaoyi Wu, Xiaoman Zhang , Weixiong Lin, Haicheng Wang, Ya Zhang , Yanfeng Wang,Weidi Xie。研究团队主要致力于人工智能和自然语言处理领域的研究,特别是在多语言模型和医学应用方面有着丰富的经验和显著的贡献。他们通过构建大规模多语言语料库和基准测试,推动了多语言医学语言模型的发展,为全球医学研究和临床实践提供了重要的技术支持。
他们的技术论文于9 月 27 日发表在【自然】期刊Nature communications上,展示了研究团队在多语言医学语言模型构建方面的最新成果。为了促进进一步的研究,团队公开了MMedC数据集和MMedBench基准数据,未受版权保护的部分已存储在Hugging Face上,受版权保护的部分提供了详细列表供研究人员自行获取。此外,源代码和模型权重也在GitHub和Hugging Face上公开发布,方便其他研究人员进行复现和扩展研究。
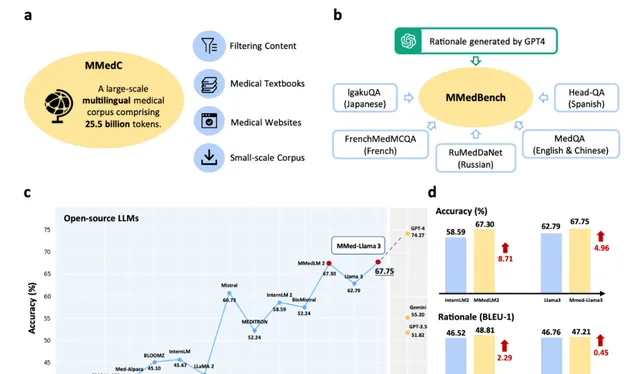
图 1:贡献概述。a图中展示了研究团队提出的大规模多语言医学语料库 (MMedC),包含 255 亿个 token,涵盖六种主要语言,从四个数据源收集。b图中展示了研究团队全面的多语言医学基准 (MMedBench) 的组成,该基准通过汇总不同语言的医学问答案例并提示 GPT-4 提供理由句子而构建。MMedBench 能够在零样本或微调设置下对不同 LLM 的多选择准确率和理由生成能力进行评估。c线图显示了研究团队 MMedBench 上各种 LLM 的最终多选择准确率,其中我们的最终模型 MMed-Llama 3 在所有现有开源 LLM 中表现出色。d比较栏进一步详细说明了 MMedLM 2 与 InternLM 2 或 MMed-Llama 3 与 Llama 3 进行比较时,多项选择准确性和推理生成能力的提升。考虑到研究团队的模型与其基础模型之间的主要区别在于对 MMedC 的自回归训练,这种比较凸显了研究团队所贡献的医学专用多语言语料库的重要性。源数据以源数据文件的形式提供。
数据集构建
MMedC多语言医学语料库是一个包含约255亿个标记的大规模数据集,涵盖了六种主要语言:英语、中文、日语、法语、俄语和西班牙语。数据来源主要包括四个方面:首先,研究团队从通用的大规模多语言语料库中筛选出医学相关内容,这些语料库如CommonCrawl,包含了大量的网页数据。其次,团队收集了大量的医学教科书,这些教科书经过严格的出版流程,确保了内容的质量。第三,团队爬取了一些医学相关的网站,包括医学百科全书、医学咨询平台和医学新闻网站。最后,团队还整合了一些现有的小规模多语言医学语料库,如Wikipedia、百度百科和UFAL医学语料库。
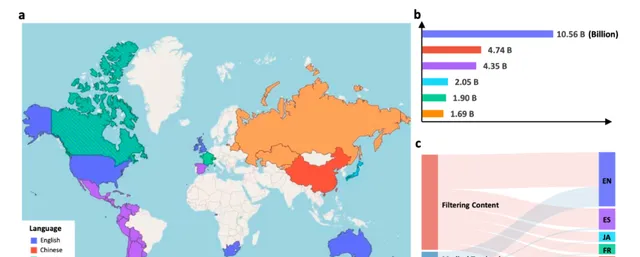
图2:MMedC统计结果。a MMedC 收录语言在世界各地的分布(此地图仅用于演示,与政治无关)。地图显示我们收集的语料库可以覆盖全球大多数主要国家。b每种语言的 Token 分布。条形图显示了不同语言的详细 token 数量。c四个来源对我们 MMedC 的六种语言的贡献。桑基图显示了四个考虑的数据源如何对不同语言做出贡献,即过滤内容、医学教科书、医学网站和小规模语料库。源数据以源数据文件的形式提供。
为了确保数据的质量和相关性,研究团队采用了一系列数据过滤和处理技术。对于从通用语料库中筛选医学相关内容,团队使用了启发式算法,通过关键词匹配和密度计算来确定医学相关文本。具体来说,团队为每种语言选择了200个医学相关术语,通过关键词匹配和密度计算来筛选出医学相关的文本。对于医学教科书,团队使用了光学字符识别(OCR)技术,将书籍内容转换为文本,并排除封面、目录和附录等非必要页面。对于医学网站,团队爬取了医学百科全书、医学咨询平台和医学新闻网站,确保数据的多样性和时效性。
MMedC语料库包含约255亿个标记,覆盖六种主要语言:英语、中文、日语、法语、俄语和西班牙语。具体来说,英语数据约为4B个标记,中文数据约为1.1B个标记,俄语数据约为0.4B个标记,法语数据约为0.3B个标记,日语数据约为0.1B个标记,西班牙语数据约为0.05B个标记。通过多种数据来源和严格的数据处理技术,MMedC语料库为多语言医学语言模型的训练提供了丰富而高质量的数据支持。
MMedBench是一个综合的多语言医学问答基准,旨在评估模型在不同语言医学领域的表现。研究团队首先收集了现有的多语言医学多选问答基准数据集,包括MedQA、IgakuQA、FrenchMedMCQA、RuMedDaNet和Head-QA。这些数据集涵盖了英语、简体中文、日语、法语、俄语和西班牙语。为了增强数据集的多样性和复杂性,团队使用GPT-4生成了每个问题的解释,并进行了严格的人类验证,以确保解释的正确性和逻辑性。
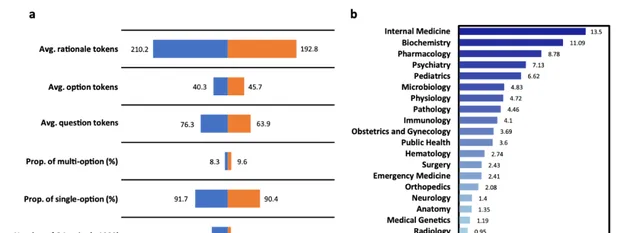
图3:MMedBench的统计结果。a条形图显示了 MMedBench 的训练和测试集上的基础统计数字。术语「平均 tokens」表示其中各种成分中每个样本的平均 token 长度。「Rationale」表示答案中的理由句子。「Option」表示选择列表中的选项描述,「question」表示问题句子。然后术语「Prop. of multi-option」表示问题中有多个正确选项的比例,「Prop. of single-option」表示答案中只有一个选项的比例。最后术语「Number of QA pair」表示训练或测试分割中有多少个 QA 对。b统计直方图显示了 MMedBench 测试分割中的主题分布,涵盖了从普通和专科医学到基础医学等广泛的医学方面。这使 MedQA 能够全面衡量医学模型的性能。源数据以源数据文件的形式提供。
在生成问答对的过程中,研究团队首先收集了现有的多语言医学多选问答数据集,并使用GPT-4生成每个问题的解释。具体来说,团队将问题、选项和正确答案输入GPT-4,指示其生成详细的解释。生成的解释随后经过人工审核,确保其与正确答案一致,并清晰表达逻辑。为了控制人工审核的成本,团队随机选择了每种语言的200个测试样本进行审核,最终生成了1136个人工审核的样本用于解释评估。
MMedBench数据集包含53,566个问答对,涵盖21个医学领域,包括内科、药理学、精神病学、微生物学、生理学、病理学、免疫学、妇产科、公共卫生、血液学、外科、急诊医学、骨科、神经学、解剖学、医学遗传学、放射学、皮肤病学和内分泌学等。数据集分为45,048个训练对和8,518个测试对,提供了丰富的多语言医学问答数据,用于评估和训练多语言医学语言模型。
模型训练与评估
自回归训练方法
在构建多语言医学模型的过程中,自回归训练方法是关键的一环。自回归训练的主要目标是通过预测下一个标记来优化模型,使其能够生成连贯且上下文相关的文本。在具体的训练过程中,研究团队将医学文本视为一系列标记,通过优化每个标记的预测概率来实现训练目标。
为了处理大规模的多语言医学数据,团队采用了分段处理的方法,将文本分割成每段2048个标记的块,并设置512个标记的重叠边界。这种方法不仅提高了训练效率,还确保了上下文信息的连贯性。由于模型参数数量庞大,无法在单个GPU上运行,团队采用了完全分片数据并行(FSDP)策略,将模型分布在多个GPU上进行训练。此外,团队还使用了BF16数据类型和梯度检查点技术,以优化内存使用和计算效率。
在具体的训练设置中,对于InternLM模型,团队设定了全局批量大小为512,学习率为2e-5;对于BLOOM模型,设定了全局批量大小为512,学习率为8e-6。整个训练过程在八个A100 GPU上进行,训练了20,000次迭代,耗时约20天。
微调方法
在自回归训练之后,团队进一步对模型进行了微调,以提升其在特定任务上的表现。微调方法主要分为参数高效微调(PEFT)和全量微调两种。
参数高效微调(PEFT)是一种在低计算资源场景下优化模型性能的方法。团队采用了最具代表性的LoRA方法,仅微调模型的一小部分参数,从而在保持计算资源消耗较低的情况下,显著提升模型性能。在具体的训练设置中,团队使用了默认推荐的rank 16,并采用与全量微调相似的训练设置。
全量微调则是对模型的所有参数进行微调,是一种更常规的做法。在全量微调过程中,团队同样采用了FSDP策略、BF16数据类型和梯度检查点技术,以优化内存使用和计算效率。全局批量大小设定为128,学习率为1e-6。
基准测试与结果分析
在多语言问答任务的评估中,研究团队采用了三种不同的评估设置:零样本评估、参数高效微调评估和全量微调评估。
在零样本评估中,团队直接测试现成的大型语言模型(LLMs),无需进一步训练。这种方法能够快速评估模型在未见过的数据上的表现,特别适用于评估模型的泛化能力。然而,零样本评估的结果显示,尽管一些闭源模型如GPT-4表现出色,但开源模型在多语言医学问答任务中的表现相对较差。
为了更好地评估模型之间的性能差异,团队采用了参数高效微调(PEFT)的方法。通过微调模型的一小部分参数,团队在低计算资源的情况下显著提升了模型性能。LoRA方法在这方面表现尤为突出,使得模型在多语言问答任务中的表现得到了显著提升。
全量微调是对模型的所有参数进行微调,这是一种更常规的做法。通过全量微调,团队能够最大程度地优化模型在特定任务上的表现。结果显示,经过全量微调的模型在多语言问答任务中的表现显著优于零样本和参数高效微调的模型,特别是MMed-Llama 3在多语言和英语基准上的表现尤为突出。
在生成解释能力的评估中,研究团队采用了多种自动化评估指标和人工评分标准,以全面衡量模型的表现。
团队使用了BLEU、ROUGE和BERT-score等经典的文本相似度评估方法。BLEU主要关注n-gram的精确度,ROUGE则结合了召回率和精确度,而BERT-score利用预训练的BERT模型提取高层语义特征,通过余弦相似度计算文本相似度。这些指标能够量化模型生成的解释与参考解释之间的相似度,从而评估模型的解释生成能力。
为了进一步评估模型的解释生成能力,团队还进行了人工评分。评估标准包括准确性、推理能力和内部知识的整合能力。通过对六个代表性模型的50个样本进行评分,结果显示,MMed-Llama 3在人工评分和GPT-4评分中均取得最高分,表现优于其他模型。这表明MMed-Llama 3不仅在多语言问答任务中表现出色,其生成的解释也具有较高的质量和逻辑性。

图4:模型评级的比较分析。a分数条表示不同指标下的排名分数。BLEU 评分表示根据 BLEU 分数排名计算出的评分分数。人工评分是指人工提供的排名,而 GPT-4 评分是指 GPT-4 生成的排名。b拟合线表示人工评分结果与不同自动指标之间的相关性。τ是 Kendall 秩相关系数,而k是拟合线的斜率。源数据以源数据文件的形式提供。
在英语基准测试中,研究团队使用了四个广泛认可的多选问答基准数据集,以评估模型在英语医学领域的表现。
团队选择了MedQA、PubMedQA、MedMCQA和MMLU-Medicine四个数据集。MedQA基于USMLE考试,PubMedQA基于PubMed摘要,MedMCQA包含大量高质量的医学问题,MMLU-Medicine则涵盖多个医学学科。这些数据集提供了丰富的测试样本,用于全面评估模型在英语医学问答任务中的表现。
结果显示,MMed-Llama 3在这些英语基准测试中表现出色,特别是在MedQA、MedMCQA和PubMedQA数据集上取得了显著的性能提升。相比其他开源模型,MMed-Llama 3在多项指标上均表现优异,甚至在某些任务上接近或超过了GPT-4的表现。
研究影响与应用前景
多语言医学语言模型的构建对通用医学人工智能(GMAI)的发展具有重要意义。GMAI致力于开发能够直接应用于广泛医疗场景的多模态人工智能模型,其中大型语言模型(LLMs)常作为人机交互的接口。通过引入多语言支持,医学多语言模型能够充分利用全球范围内的数据源,扩展可用的多模态训练数据,从而提高其他模态的表示质量。这不仅有助于提升模型的整体性能,还能促进医学人工智能在全球范围内的应用和普及。
现有的LLMs在医学领域的一个主要问题是幻觉,即生成的内容可能包含事实错误。为了解决这一问题,检索增强生成技术被提出,通过从外部知识库中检索事实信息,来减少生成内容中的错误。然而,目前大多数检索增强生成技术主要集中在英语语言环境中,限制了其在其他语言中的应用。多语言医学语言模型的开发可以显著改善检索过程,丰富潜在的知识库,从而提高生成内容的准确性和可靠性。这对于医学领域尤为重要,因为准确的医学信息对于诊断和治疗至关重要。
多语言医学语言模型在临床实践中有着广泛的应用前景。首先,它们可以缓解语言障碍。在许多医疗系统中,患者和医疗提供者之间的语言障碍可能导致沟通不畅、误诊和治疗不当。多语言医学语言模型可以实现实时翻译和解释,确保患者能够有效地表达症状并理解诊断和治疗方案,从而提高医疗服务的质量和效率。
此外,多语言医学语言模型还可以减少文化和法律敏感性。不同国家和地区在医疗互动中存在文化和法律差异,理解这些差异可以显著增强对医学语言模型的信任,进而改善健康结果。通过训练模型识别和处理这些文化和法律差异,可以提高模型在不同文化背景下的适用性和可靠性。
多语言医学语言模型在医学教育中也有着重要的应用价值。特别是在医学教育资源匮乏的地区,这些模型可以提供多语言的教育材料和模拟,帮助标准化医学培训,确保全球范围内医疗服务的一致性和质量。通过提供高质量的教育资源,多语言医学语言模型可以帮助培养更多合格的医疗专业人员,提升全球医疗水平。
潜在局限性与未来工作
尽管MMedC多语言医学语料库在数据收集和处理方面进行了严格的筛选和过滤,但由于数据主要来源于网络爬取,难免会存在一些固有的偏见。这些偏见可能会对某些弱势群体产生不利影响,特别是在医学领域,这种偏见可能会导致诊断和治疗建议的不准确。未来的研究需要进一步探索更严格和全面的安全控制措施,以减少数据集中的潜在偏见,确保模型在不同人群中的公平性和可靠性。
虽然研究团队在模型中引入了生成解释的能力,以帮助用户理解模型的决策过程,但目前的解释性仍然存在一定的局限性。现有的解释生成方法主要依赖于模型生成的文本,这些文本可能无法完全反映模型内部的决策逻辑。此外,如何在复杂的医学场景中提供清晰、准确且易于理解的解释,仍然是一个亟待解决的问题。未来的研究需要进一步探索和开发更具解释性的模型架构,如结合卷积块或多层感知器(MLP)的解释性方法,以增强模型的透明度和可解释性。
MMedC语料库涵盖了六种主要语言,但仍然无法覆盖全球所有语言。这限制了模型在某些语言环境中的应用,特别是在一些低资源语言的医学场景中。未来的研究应致力于扩展数据集的语言覆盖面,纳入更多如德语和阿拉伯语等语言。此外,通过定义特定的过滤关键词,可以从通用爬取数据集中高效提取医学相关内容,进一步丰富低资源语言的数据集。
未来的研究可以从以下几个方面进行改进和扩展。
扩展数据集的语言覆盖面:通过引入更多语言的数据,特别是低资源语言的数据,进一步提升模型的多语言能力和适用性。
增强模型的解释性:开发更具解释性的模型架构,结合卷积块或多层感知器(MLP)的解释性方法,以提高模型的透明度和用户信任度。
减少数据集的潜在偏见:探索更严格和全面的安全控制措施,减少数据集中的潜在偏见,确保模型在不同人群中的公平性和可靠性。
结合检索增强生成技术:通过引入检索增强生成技术,利用外部知识库中的事实信息,减少模型生成内容中的错误,提高生成内容的准确性和可靠性。
提升模型的临床应用能力:通过进一步优化模型的训练和微调方法,提升模型在临床实践中的应用能力,特别是在实时翻译、解释和医学教育等方面。
通过这些改进和扩展,未来的多语言医学语言模型将能够更好地服务于全球医疗领域,推动医学人工智能的发展,为全球医疗服务的提升做出更大的贡献。
多语言医学语言模型的构建不仅推动了通用医学人工智能的发展,还改进了检索增强生成技术,并在临床实践和医学教育中展现了广泛的应用前景。这项研究不仅展示了多语言医学语言模型的潜力,也为未来的研究和应用提供了宝贵的经验和参考。(END)
参考资料:https://www.nature.com/articles/s41467-024-52417-z

波动世界(PoppleWorld)是噬元兽数字容器的一款AI应用,是由AI技术驱动的帮助用户进行情绪管理的工具和传递情绪价值的社交产品,基于意识科学和情绪价值的理论基础。波动世界将人的意识和情绪作为研究和应用的对象,探索人的意识机制和特征,培养人的意识技能和习惯,满足人的意识体验和意义,提高人的自我意识、自我管理、自我调节、自我表达和自我实现的能力,让人获得真正的自由快乐和内在的力量。波动世界将建立一个指导我们的情绪和反应的价值体系。这是一款针对普通人的基于人类认知和行为模式的情感管理Dapp应用程序。











