你对全闪存储是什么印象?
快!贵!容量低!都是土豪在用!
但是,买全闪存的,就都是「土豪」吗?
不不不,其实注重性价比的懂行客户,更钟爱全闪!

为什么呢?
我来先举个大家都能懂的小例子↓
如果你有台旧电脑,性能不好,但只有500块预算,怎么利用有限的银子获得最大化性能提升呢?

答案很简单, 把系统盘从HDD换成SSD。
你会发现,小小一个改变,性能竟然快到飞起
同样的,换到企业级场景也一样的。比如你把服务器换成NVMe盘,给NAS加个SSD缓存,把机械盘阵换混闪,把混闪改全闪…
当然企业级存储,并不是简单地HDD换SSD那么简单,要充分发挥闪存优势,软件架构上也要下足功夫。即便如此,带来的提升,也是立竿见影。
所以,用「全闪存」,竟然是超有性价比的IT基础架构升级方案。
尤其这两年数据爆炸,AI等新兴场景越来越多,传统「热温冷」数据分层存储的理念已经out了。
以前,大家只用全闪存储最热的联机交易型数据,把有限的预算花到刀刃上。
现在越来越多温数据,变成热数据,冷数据也要快速热起来,否则跟不上节奏,耽误了大事。

客户早就厌倦了把数据从不同存储介质之间搬来搬去,他们开始盘算自己的家底:
有没有可能把机械硬盘彻底干掉?有没有可能把全部存储都换成全闪?选哪个乙方厂家来扛活?
一旦这种想法萌芽出来,就一发不可收拾,简直夜不能寐啊。
那么,现有的技术架构,能不能满足客户把「全部数据」都存到「全闪」里面呢?
乍一看,还是颇有些难度的。
虽然SSD这些年的价格一直在降,但是,与机械硬盘的相比,还是有不小的差距。
即便依靠闪存的降价、缓存的堆叠,可以把每IOPS的成本降下来,但是每TB的绝对成本,仍然让客户不得不反复权衡。
想把全部数据「All in 闪存」的目标,看起来还是那么遥远。
那么,到底有没有那种 兼顾性能 与 成本优势 的分布式全闪?满足客户日益迫切的「全全闪」诉求?
最近,我看到一家专业存储厂商,搞出了一套全新的架构,把分布式全闪的体验拉升了一大波。
这家公司,就是「XSKY星辰天合」,国内独立存储厂商中的「最能打」的那一个。
根据IDC的统计数据,自2020年以来,XSKY在中国SDS市场中,始终位列领跑者行列(独立SDS厂商第一,对象存储软件市场第一)。
XSKY经过8年在存储技术领域不断打磨实践,以最新的标准存储协议和网络技术作为基础,推出了「星海架构」。
他们的目标,就是希望通过架构创新,推动全闪普惠,让「全全闪」成为可能。
总体来说,星海架构包括了三大创新点↓
1、Shared-Everything全共享架构,扩展性、灵活性、故障恢复能力大幅提高
在各种分布式存储、数据库系统中,过去非常流行的是「Shared Nothing架构」。
Shared-Nothing的初衷是规避节点间网络带宽不足,每个节点物理资源隔离,独立处理数据,各人自扫门前雪,尽量减少跨网、跨节点处理数据,从而降低延迟。
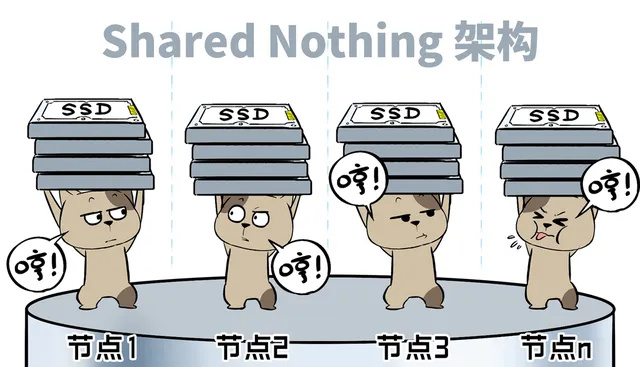
但是,资源的独立性限制了灵活性,所有节点无法统一利用,形成资源不均浪费,无法进行 高效的大比例全局纠删 冗余,数据恢复、后台IO也难以全局优化。
同时,随着节点增多,为了维持分布式事务的一致性,会带来额外的软件复杂性和CPU开销,并导致更严重的「写放大」问题。
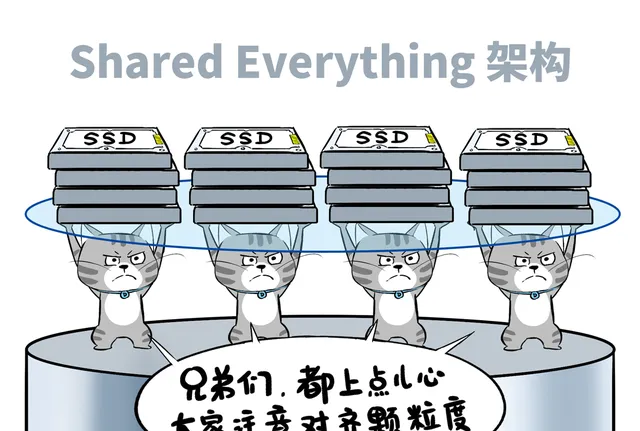
随着NVMe标准成熟和网络带宽提升,跨节点的访问延迟已经不再是主要矛盾,因此, XSKY抛弃了这种业界沿用多年的 Shared-Nothing 架构,大胆采用了 Shared-Everything 架构。
具体来看,每个存储节点上的ChunkServer、FileServer、BlockServer,都以无状态容器化方式运行,大家基于共享内存互通,没有额外网络开销。
而每个存储节点的IO Server将本节点的SSD通过NVMe-oF协议暴露出物理卷,这样任何ChunkServer都可以挂载集群里的所有NVMe卷。
这种架构让分布式存储突破节点局限,任意SSD都可以被全局访问,容量/性能与单个节点的CPU/内存解耦。
也可以更好地进行全局流控,后台任务调度,并根据全局 SSD 的状态进行磨损均衡。
全局SSD可见,也让实施更大比例的EC纠删码成为可能,有效提升得盘率(配合压缩技术,得盘率超过100%)。
横向扩展时,节点间不需要通信,消除了东西流量,可实现线性扩展。
以前,采用Shared-Nothing架构,节点间需要复杂的一致性协商,故障时,恢复时间长达数秒,这种服务级别很难应对当下的关键业务场景。
现在,无论慢盘还是网络亚健康问题,无须等待数据复制或者状态同步,100毫秒内即可快速切换。
至此,星海架构通过Shared-Everything,打通了分布式全闪的「底层逻辑」,扩展性、可靠性、灵活性、得盘率都得到了显著提升。
2、单层闪存介质,专门面向TLC NVMe SSD优化,成本大幅降低
星海架构采用了单层TLC NVMe SSD来构建存储池,简化集群的硬件结构。
TLC SSD具备更高的存储密度和更优的成本。但是传统全闪通常采用分层架构,缓存层需要配备DWPD更高的闪存,造成集群结构复杂且成本高昂。
星海架构专门针对TLC SSD的特点进行优化,采用单一存储层架构,不再设置单独的缓存层,显著降低介质成本20%以上。
针对闪存的「写放大」问题,星海架构采用了Append Only方式来更新数据,最大化减少「写放大」,提升SSD寿命,进一步降低成本。
↓
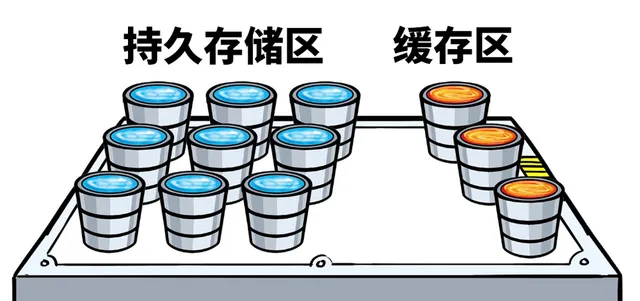
同时,通过精心设计的空间布局,在单个 SSD 上实现缓存和持久存储的双重功能。
保障在没有专用的缓存介质情况下,仍然可以提供足够的性能稳定性。
3、采用端到端NVMe协议,最大化硬件卸载
星海架构不仅在存储访问方面采用了NVMe over Fabrics协议,在存储内部网络中,也全面实施了NVMe-oF。
这意味着所有存储节点都通过NVMe over Fabrics高效访问每个NVMe SSD,避免了存储协议转换所带来的额外开销。
性能决定了存储的上限,可靠性决定了存储的下限。
在不断迭代的NVMe SSD和高速网络加持下,绝对性能跑出个好看的分数不是问题。这方面,XSKY的星海架构已经非常「能打」。
但XSKY并不满足于绝对性能摸高,作为存储老兵,他们深知规模化全闪里面,在支持大规模写入和元数据更新的情况下,长期的尾部延迟才是衡量存储性能服务水平的关键。
一锤子买卖并非真高手,持续稳定输出才是真功夫。
星海架构在三大创新技术的加持之下,整体性能服务水平获得了巨大提升↓
在40%负载情况下,端到端延迟低至 100微秒 ;面对慢盘、亚健康网络时, 100毫秒 内快速切换;通过大比例EC和数据压缩技术,实现超过 100% 的得盘率。
在这样的整体性能服务水平下,成本也获得了极大的优化,让客户不再对全闪的价格望而却步。
全闪普惠时代到来,「All Data on All Flash」终于成为可能。
基于星海架构,XSKY的新一代分布式全闪产品星飞9000也随之横空出世。
作为业界首款采用全共享架构的分布式主存储,星飞9000一体机包含星飞软件和专属硬件,提供全场景存储业务支撑能力,并有信创机型备选*。
从数据库关键业务场景,到互联网高并发场景,再到实时分析场景,星飞用一套存储架构,承载客户全量数据,而无需在不同的介质之间,导来导去。
XSKY的野心是用一套星飞来替代NVMe本地盘、全闪阵列和容量型存储,既然想要「一打三」,就要看看实战的时候,到底行不行。
在实测中,星飞9000果然不负众望,表现相当炸裂。
看罢星飞的实战结果,我们有理由相信,通过架构创新,的确给全闪带来了质变。
低成本、高性能服务水平的分布式全闪,正扑面而来。全「全闪」时代,离我们只有一步之遥。
大家开始换「全全闪」了,你还不抓紧?











