# Molmo的崛起

多模態模型Molmo正在快速崛起。盡管大眾一直在期盼谷歌、OpenAI等資金雄厚的科技巨頭推出全新的Sota模型,卻沒想到,一家名為Ai2的低調創業公司竟然釋出了這樣一款多模態人工智能產品。在一段令人驚艷的影片中,Molmo就宛如鋼鐵俠的助手賈維斯,萬能無比。假如你想出售一輛單車,Molmo只需一張照片,便能大致判斷出單車的顏色、品牌和市場售價,還能為廣告語添磚加瓦,讓你輕松成交。
# 超越期待的實力
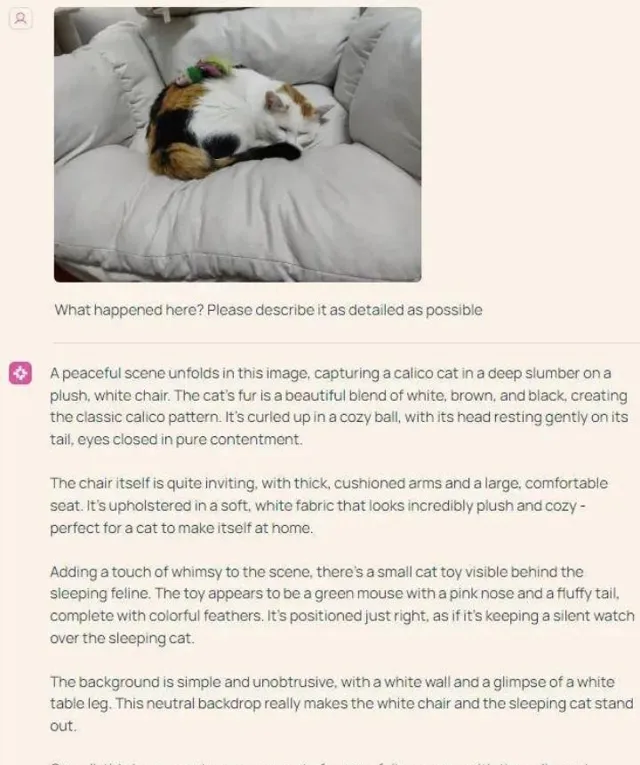
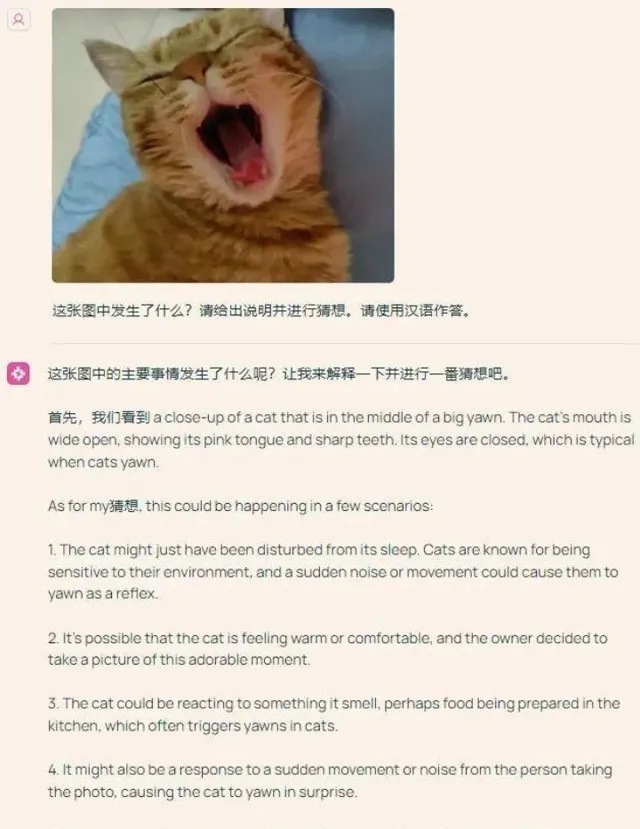
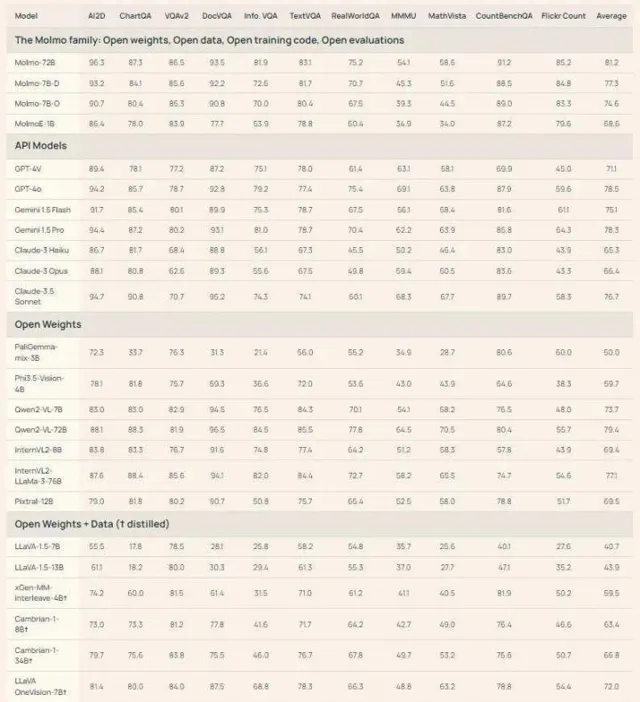
Molmo不僅能解決現實問題,它在虛擬世界中的表現同樣強悍。你只需發出一個指令:「Molmo,幫我點一杯南瓜拿鐵。」接下來的操作全交給它,點單、支付,Molmo通通搞定。你就坐在沙發上,悠然自得地等待美味咖啡的到來。只是,機器之心對他們釋出的Demo模型進行了一次嘗試,發現相比宣傳影片,其功能還略顯不足。我們讓Molmo進行影像描述,它的表現卻著實讓人刮目相看,細致入微的描述甚至包括了一只貓背上小玩具的形態:「玩具的外觀像只綠色的老鼠,粉紅色的鼻子,蓬松的尾巴,羽毛五彩繽紛。」雖說Molmo的漢語能力略顯不足,但數據表明,它在一系列測試中表現驚艷,得分甚至超過了Claude 3.5 Sonnet和GPT4V等頂尖模型,堪比GPT4o之流。
# 小而強大的秘密

Molmo的體積小巧,但卻能在本地運作,完全不需要依賴API、訂閱服務或昂貴的液冷GPU集群。更為關鍵的是,Molmo完全免費開源,從權重到程式碼、數據與評估流程,無一不向公眾開放。Ai2的行政總裁Ali Farhadi提到,Molmo的成功秘訣在於數據的質素和量的平衡。如今,大多數先進的多模態模型往往是閉源的,即便有些開源模型表現不錯,通常也得依賴於專有模型生成的合成數據。而Ai2致力於從零開始構建高效能的VLM,面臨著種種技術挑戰。

# 數據驅動的選擇
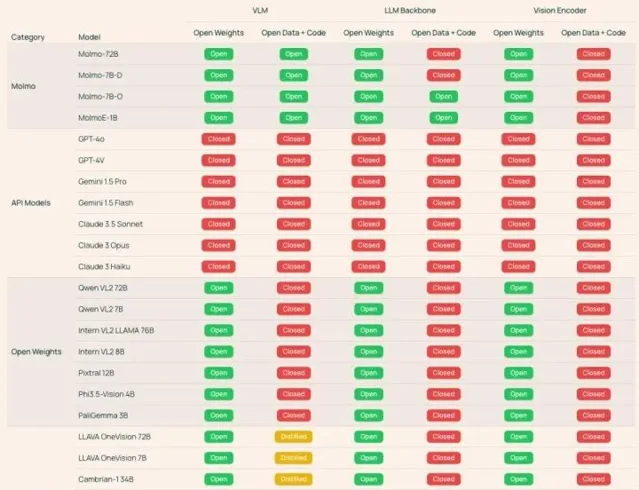
為了解決閉源模型的局限,Ai2選用了語音描述的方法,構建出一個高細節的影像描述數據集。這些數據全由人工標註,並且可以公開獲取。研究團隊認為,提升模型效能的關鍵在於優質數據的選擇。因此,他們從數十億張圖片中精挑細選,整理出60萬張影像,確保了數據集的高質素。為了讓Molmo適應更多工,Ai2還引入了多樣化的數據混合對模型進行進一步的微調,其中包括一項獨特的二維「指向」功能。這個功能使得Molmo能夠以非語言的方式,像指向物體那樣進行回答。

# 創新的數據收集方法
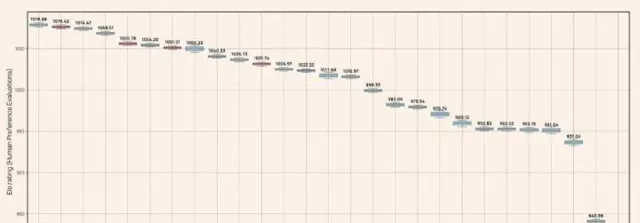
要想訓練一個大型VLM,通常需要海量的影像與文本對數據,而這些數據主要取自於網絡,因此雜訊問題極為嚴重。Ai2團隊采用了創新的方法提升數據質素,發現使用少於一百萬的數據對便足以訓練出強大的模型。這就是構成Molmo系列模型成功的重要要素——PixMo,它包含多種類別的數據,包括用於多模態預訓練的細致描述數據和監督微調的數據。由於人類標註大量數據是一個巨大的挑戰,團隊決定采用簡單有效的語音描述方式。標註者只需用語音描述影像60到90秒,這樣不僅提高了效率,還降低了成本。
# Molmo的未來願景

總的來看,Molmo無疑展現了小型高效的潛力。它的指向功能將成為VLM與智能代理之間的重要交流通道。而Ai2的團隊也計劃在接下來的兩個月內,依次釋出更多的研究成果與模型權重。透過平衡數據量與質素,他們再次證明了「量小而精」的策略。無論AI的發展如何波譎雲詭,Molmo無疑是多模態模型領域的一顆新星,值得我們持續關註和期待。
Molmo讓人們看到了小型模型能夠挑戰大型模型的可能性,這不僅是技術的突破,更是對未來智能科技套用的一次全新探索。











