探討了人工智能(AI)的普及給嵌入式設計人員帶來的新挑戰。在建立「邊緣機器學習(ML)」套用時,設計人員必須確保其能有效執行,同時最大限度地降低處理器和儲存開銷,以及物聯網(IoT)器材的功耗。
從監控和存取控制到智能工廠和預測性維護,基於機器學習(ML)模型構建的人工智能(AI)在工業物聯網邊緣處理套用中已變得無處不在。隨著這種普及,支持AI的解決方案的構建已經變得「大眾化」——從數據科學家的專業領域轉為嵌入式系統設計人員也需要了解的領域。這種大眾化帶來的挑戰在於,設計人員並不一定具備定義要解決的問題以及以最恰當方式捕獲和組織數據的能力。此外,與消費類解決方案不同,工業AI實作的現有數據集很少,通常需要使用者從頭開始建立自己的數據集。
融入主流
AI已經融入主流,深度學習和機器學習(DL和ML)是我們現在習以為常的許多套用的背後力量,這些套用包括自然語言處理、電腦視覺、預測性維護和資料探勘。早期的AI實作是基於雲或伺服器的,需要大量的處理能力和儲存空間,以及AI/ML套用與邊緣(終端)之間的高頻寬連線。盡管生成式AI套用(如ChatGPT、DALL-E和Bard)仍然需要此類設定,但近年來已經出現了邊緣處理的AI,即在數據捕獲點即時處理數據。邊緣處理極大減少了對雲的依賴,使整體系統/套用更快、需要更少的功耗並且成本更低。許多人認為安全性得到了提高,但更準確地說,主要的安全重點從保護雲與終端之間的通訊轉移到了使邊緣器材更安全。
邊緣的AI/ML可以在傳統的嵌入式系統上實作,這些系統的設計人員可以使用強大的微處理器、圖形處理單元和豐富的記憶體器件,即類似於PC的資源。然而,越來越多的商業和工業物聯網器材需要在邊緣具備AI/ML功能,這些器材通常硬件資源有限,而且在許多情況下由電池供電。
在資源和功耗受限的硬件上執行的邊緣AI/ML的潛力催生了「TinyML」這一術語。實際用例涵蓋工業(如預測性維護)、樓宇自動化(環境監控)、建築施工(監督人員安全)和安防等領域。
數據流
AI(及其子集ML)需要從數據捕獲/收集到模型部署的工作流程(見圖1)。對於TinyML而言,由於嵌入式系統資源有限,因此每個工作流程階段的最佳化至關重要。
例如,TinyML的資源需求被認為是1 MHz到400 MHz的處理速度、2 KB到512 KB的RAM和32 KB到2 MB的儲存空間(快閃記憶體)。此外,150 µW至23.5 mW的小功耗預算也常常帶來挑戰。

圖1——上圖為簡化的AI工作流程。雖然圖中未顯示,但模型部署本身必須將數據反饋回流程中,甚至可能影響數據的收集。
此外,在將AI嵌入資源有限的嵌入式系統時,還有更重要的考慮因素或權衡。模型是系統行為的關鍵,但設計人員經常發現自己在模型質素/精度(影響系統可靠性/依賴性和效能,主要是執行速度和功耗)之間做出妥協。
另一個關鍵因素是決定使用哪種類別的AI/ML。通常有三種演算法可供使用:監督學習、無監督學習和強化學習。
解決方案
即使是對AI和ML有良好理解的設計人員,可能也會在最佳化AI/ML工作流程的每個階段並在模型精度與系統效能之間找到完美平衡方面遇到困難——那麽缺乏以往經驗的嵌入式設計人員如何應對這些挑戰呢?
首先,重要的是不要忽視一個事實:如果模型小且AI任務僅限於解決簡單問題,那麽部署在資源有限的物聯網器材上的模型將會更有效。
幸運的是,ML(特別是TinyML)進入嵌入式系統領域,帶來了新的(或增強的)整合式開發環境(IDE)、軟件工具、架構和模型——其中許多都是開源的。例如,TensorFlow™ Lite for Microcontrollers(TF Lite Micro)是一個面向ML和AI的免費開源軟件庫,它專為在只有幾KB記憶體的器件上實作ML而設計。此外,程式可以用開源和免費的Python語言編寫。
關於IDE,Microchip的MPLAB® X就是此類環境的一個範例。該IDE可與公司的MPLAB ML一起使用,MPLAB ML是專門開發的MPLAB X外掛程式,用於構建最佳化的AI物聯網傳感器辨識程式碼。MPLAB ML由AutoML提供支持,可將AI ML工作流程的每一步完全自動化,無需重復、繁瑣和耗時的模型構建。特征提取、訓練、驗證和測試確保滿足微控制器和微處理器記憶體限制的最佳化模型,使開發人員能夠快速在基於Microchip Arm® Cortex®的32位元MCU或MPU上建立和部署ML解決方案。
流程最佳化
工作流程最佳化任務可以透過使用現成的數據集和模型來簡化。例如,如果一個支持ML的物聯網器材需要影像辨識,從現有的標記靜態影像和影片片段數據集開始進行模型訓練(測試和評估)是合理的;需要註意的是,監督學習演算法需要標記數據。
許多影像數據集已經存在於電腦視覺套用中。然而,由於它們是為基於PC、伺服器或雲的套用設計的,通常都很大。例如,ImageNet包含超過1400萬張標註影像。
根據ML套用的不同,可能只需要少量子集;例如,有很多人但只有少量靜物的影像。例如,如果在建築工地使用支持ML的網絡攝影機,當有不戴安全帽的人進入其視野時,它們可以立即發出報警。ML模型需要訓練,但可能只需要少量戴或不戴安全帽的人的影像。然而,對於帽子類別型,可能需要更大的數據集和足夠的數據集範圍,以考慮不同的光照條件等各種因素。
圖1中第1步到第3步的內容分別是獲得正確的即時(數據)輸入和數據集、準備數據和訓練模型。模型最佳化(第4步)通常是壓縮,這有助於減少記憶體需求(處理期間的RAM和用於儲存的NVM)和處理延遲。
在處理方面,許多AI演算法(如摺積神經網絡(CNN))在處理復雜模型時會遇到困難。一種流行的壓縮技術是剪枝(見圖2),剪枝有四種類別:權重剪枝、單元/神經元剪枝和叠代剪枝。

圖2——剪枝減少了神經網絡的密度。上圖中,某些神經元之間的連線權重被設為零。但有時神經元也可以被剪掉(圖中未顯示)。
量化是另一種流行的壓縮技術。量化是將高精度格式(如32位元浮點(FP32))的數據轉換為低精度格式(如8位元整數(INT8))的過程。量化模型(見圖3)的使用可以透過以下兩種方式之一納入機器訓練。
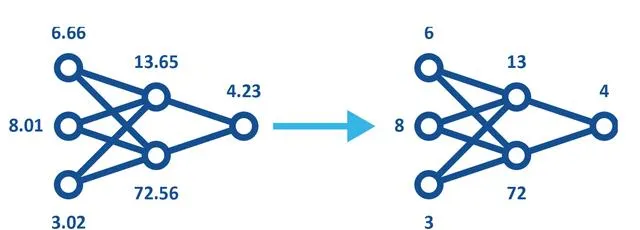
圖3——量化模型使用低精度,從而減少記憶體和儲存需求並提高能源效率,同時仍保留相同的形狀。
雖然量化很有用,但不應過度使用,因為它類似於透過使用較少的位表示顏色和/或使用較少的像素來壓縮數碼影像——即,會存在一個影像變得難以解釋的點。
總結
正如我們在開頭所提到的,AI現在已經深深融入嵌入式系統領域。然而,這種大眾化意味著以前不需要了解AI和ML的設計工程師正面臨將AI解決方案實作到其設計中的挑戰。
盡管建立ML套用並充分利用有限硬件資源的挑戰可能令人望而卻步,但這對經驗豐富的嵌入式系統設計人員來說並不是一個新挑戰。好訊息是,工程社區內有豐富的資訊(和培訓),以及像MPLAB X這樣的IDE、MPLAB ML這樣的模型構建工具以及各種開源數據集和模型。這種生態系可幫助不同理解水平的工程師快速完成現在可以在16位元甚至8位元微控制器上實作的AL和ML解決方案。原文連結:https://www.eeworld.com.cn/ayXL48C











