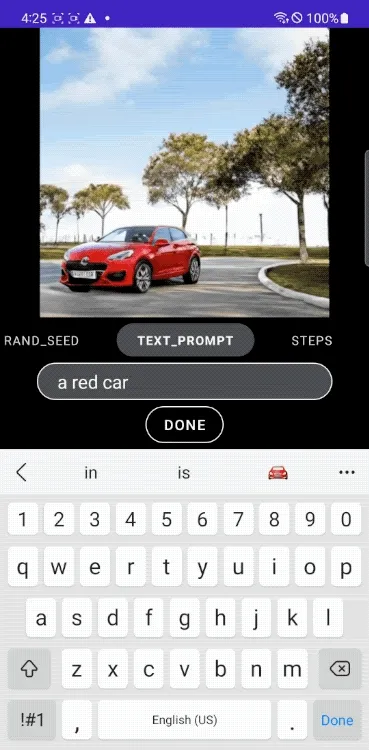
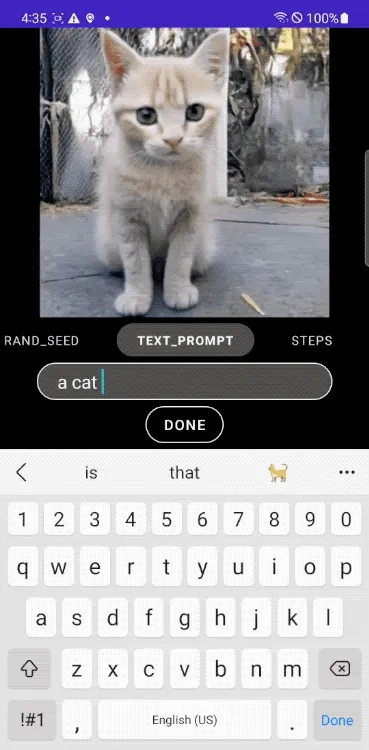
Google開發了可以在流動通訊器材上,以次秒(Subsecond)速度執行文本轉影像的模型MobileDiffusion。MobileDiffusion是一種高效的擴散模型,在iOS和Android高端器材上,能在半秒內生成512x512的高品質影像。MobileDiffusion相較於其他影像生成模型小上許多,只有5.2億參數特別適用於流動應用部署。
當前文本轉影像擴散模型越來越成熟,使用者只要輸入文本提示,模型就可生成高品質影像,但是先進的模移動輒擁有數十億個參數,因此執行成本也非常高昂,需要強大的桌上型電腦或是伺服器才能快速運算。
研究人員指出,造成文本轉影像擴散模型效能低落的主要原因有兩個,第一是擴散模型固有設計需要叠代去噪生成影像,而這需要對模型進行多次評估,第二則是文本轉影像擴散模型網絡架構的高復雜性,通常具有數十億參數導致運算成本高昂。
由於這些效能上的障礙,盡管在流動通訊器材上執行生成式人工智能模型,具有強化使用者體驗、高私密性的好處,但目前研究仍相對較少。當然還是有一些提升文本轉影像擴散模型效率的研究,像是透過數值求解器或是蒸餾技術,減少模型的功能評估數量(Number of Function Evaluations,NFE),希望借由降低評估所帶來的運算負擔。但即便如此,由於模型架構仍然非常復雜,在流動通訊器材上即便是少量的評估步驟,仍然可能執行地很慢。
MobileDiffusion則是研究人員試圖突破流動通訊器材有限運算能力的限制,借由仔細檢視Stable Diffusion中UNet架構每個組成部份和計算操作,設計出高效文本轉影像擴散模型。MobileDiffusion遵循潛在擴散模型的設計,具有文本編碼器、擴散UNet和影像解碼器,研究人員使用適用於流動通訊器材的小模型CLIP-ViT/L14,作為MobileDiffusion文本編碼器,並將改進效率的重點,擺在擴散UNet和影像解碼器上。
擴散UNet是一種深度學習模型架構,用於生成或是轉換影像,本身是一種特殊的摺積神經網絡,其特點是具有對稱的U型結構,有助於模型在進行影像處理時保留細節資訊。研究人員主要使用兩種方法來來提升擴散UNet的效率,第一是在模型瓶頸處,也就是資訊最集中的地方,使用更多的Transformer區塊以降低計算量,第二是使用輕量級可分離摺積。摺積區塊主要用於影像特征截取,但是傳統摺積操作計算量大,因此研究人員透過使用可分離摺積,在不降低模型效能的情況下,減少需要的計算量。
除了擴散UNet,研究人員也著手最佳化影像解碼器,透過訓練變分自編碼器(Variational Autoencoder,VAE)簡化影像表示,使影像資訊能縮小至原圖八分之一,減少儲存和計算需求,並使用簡化版的解碼器明顯提高效能,在降低延遲接近50%的情況下,還可以維持甚至提升影像品質。研究人員還采用了DiffusionGAN混合模型實作一步采樣,這是一種結合擴散模型和生成對抗網絡(GAN)的新技術,能夠一步驟生成影像,相較於傳統的多步驟方法快上不少。
雖然MobileDiffusion只有5.2億個參數,卻可以生成不同領域的高品質影像。由於MobileDiffusion只需要半秒鐘便可以在流動通訊器材上生成512x512影像,因此可以在使用者邊輸入文本提示的同時,迅速生成影像,能套用於流動通訊器材創造各種即時影像生成體驗。