來源:機器之心Pro
AIxiv專欄是機器之心釋出學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報道了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯系報道。投稿郵箱:liyazhou @jiqizhixin .com;zhaoyunfeng @jiqizhixin .com
團隊介紹:本專案的核心開發團隊主要由上海交通大學 GAIR 研究組的本科三年級、四年級學生以及直博一年級研究生組成。專案得到了來自 NYU 等一線大型語言模型領域頂尖研究科學家的指導。
詳細作者介紹見:https://github.com/GAIR-NLP/O1-Journey#about-the-team。
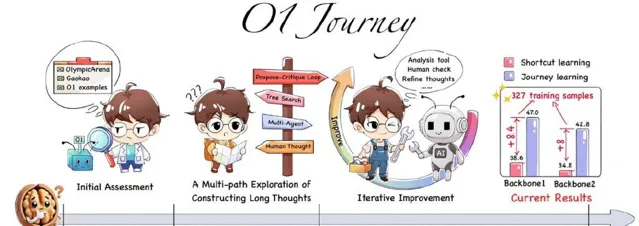
在人工智能領域掀起巨浪的 OpenAI o1 模型釋出三周後,一支由高校年輕研究者組成的團隊今天釋出了題為 "o1 Replication Journey: A Strategic Progress Report (o1 探索之旅:戰略進展報告)" 的研究進展報告。這份報告的獨特之處在於 (1)不僅提出並驗證了 「旅程學習」 的技術的巨大潛力(研究者也認為是 o1 取得成功的關鍵技術):透過 327 條訓練樣本,鼓勵模型學會反思、糾錯、回溯,其在復雜數學題目上 表現 絕對效能就超過了傳統監督學習 8% 以上,相對效能提升超過 20% ;(2)並且,其前所未有的透明度和即時性,不僅詳細記錄了團隊在復現過程中的發現、挑戰、試錯和創新方法,更重要的是,它倡導了一種全新的 AI 研究範式。研究團隊負責人表示:" 我們的主要目標不是達到與 OpenAI 的 o1 相當的效能 —— 考慮到可用資源有限,這是一個極具挑戰性的任務。相反,我們的使命是透明地記錄和分享我們的探索過程,聚焦於我們遇到的根本問題,發現新的科學問題,並辨識導致 o1 的成功的關鍵因素 ,並與更廣泛的 AI 社區分享我們的試錯經驗。 o1 技術無疑會成為全球各大 AI 科技公司爭相復現的目標。如果我們能夠及早分享一些復現過程中的經驗教訓,就能幫助其他公司減少不必要的試錯,從而降低全球範圍內 o1 技術復現的總體成本和時間。這不僅有利於推動技術的快速發展,也能促進整個 AI 行業的共同進步。 」

團隊提出的模型在同一道數學題上,與 OpenAI 的 o1-preview (答對)及 GPT-4o(答錯)的比較例項,證明旅程學習不斷試錯、反思、自我糾正的能力在復雜推理任務場景上非常關鍵。
該報告發現了什麽?從 「"捷徑學習"」 到 「旅程學習」,從 「浮光掠影」 到 「深耕細作」
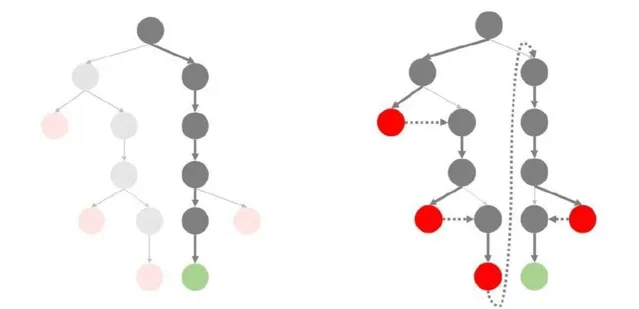
圖:從 "捷徑學習" 到 "旅程學習" 的範式轉變。這是一個用於推理任務的搜尋樹。對於數學問題解決任務,根節點代表初始問題,而葉節點則是最終結論。綠色節點表示正確答案,紅色節點表示錯誤答案。傳統上,學習主要集中在對直接從根到葉的捷徑路徑進行監督訓練。然而,本研究探索了對整個探索路徑進行監督學習,這包括了試錯和糾正的過程。
團隊認為,大多數現有的機器學習或大模型訓練方法(如監督式微調)都可以被歸類為 "捷徑學習" (Shortcut Learning) ,即模型學習到達正確答案的直接路徑。這種傳統範式雖然在特定、明確定義的任務中可能有效,但在面對復雜、動態和開放性問題時顯示出明顯的局限性。捷徑學習具有以下幾個關鍵特征:(1) 註重快速結果:強調在短時間內達到特定的效能指標或完成特定任務。(2) 高度依賴數據:效能改進通常依賴於增加訓練數據量,而非改進學習演算法本身。(3) 泛化能力有限:在訓練數據分布之外的場景中,效能可能會急劇下降。(4) 缺乏自我糾正能力:這些系統通常缺乏辨識和糾正自身錯誤的能力。盡管捷徑學習推動了人工智能的許多進步,但它難以產生真正智能和可靠的人工智能系統,無法應對現實世界挑戰的復雜性。隨著我們追求更高級形式的人工智能甚至超級智能,這種方法的局限性變得越來越明顯。
認識到這些缺點,本文提出了一種名為 "旅程學習"(Journey Learning) 的新範式。旅程學習旨在使人工智能系統能夠透過學習、反思、回溯和適應不斷進步,就像人類一樣,從而展現出更高水平的智能。
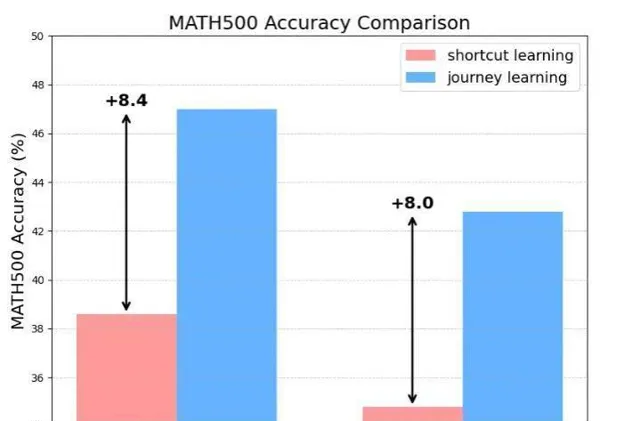
圖:"捷徑學習"(Shortcut Learning) 和 "歷程學習"(Journey Learning) 在 MATp00(Lightman 等人,2024 年)上的表現。
如圖所示,團隊提出了 "旅程學習" 範式,它鼓勵模型不僅學習捷徑,還要學習完整的探索過程,包括試錯、反思和回溯。僅使用 327 個訓練樣本,不借助任何額外訓練技巧, 旅程學習在 MATH 數據集上的表現就超過了傳統監督學習 8% 以上,展示了其極其強大的潛力。作者也認為這是 o1 技術中最關鍵的組成部份 。
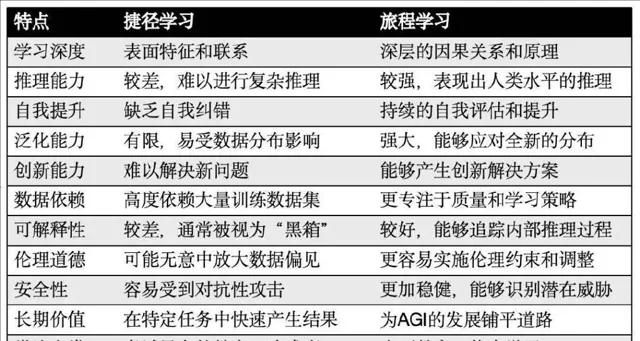
表:捷徑學習和旅程學習的多維度比較
模型生成的例子



技術細節是什麽?o1 技術探索之旅
團隊負責人分享:「 如果我們能夠及早分享一些復現過程中的經驗教訓,就能幫助其他公司減少不必要的試錯,從而降低全球範圍內 o1 技術復現的總體成本和時間。這不僅有利於推動技術的快速發展,也能促進整個 AI 行業的共同進步。 」
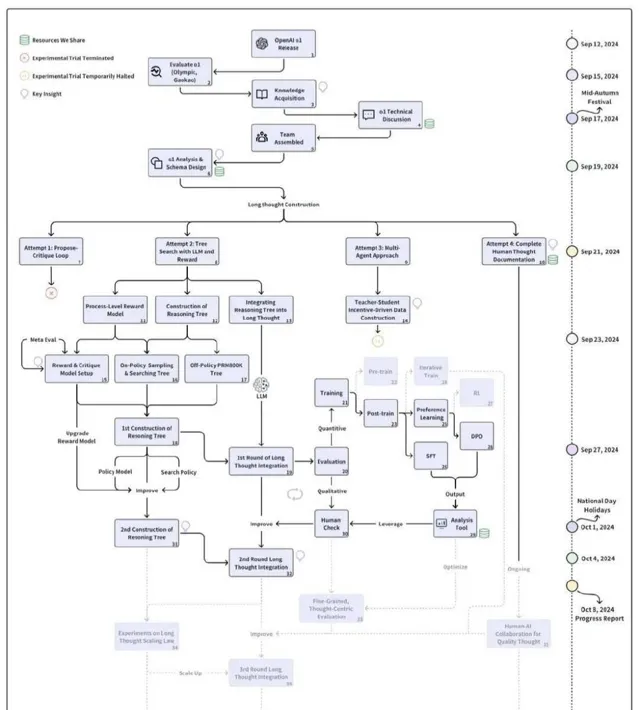
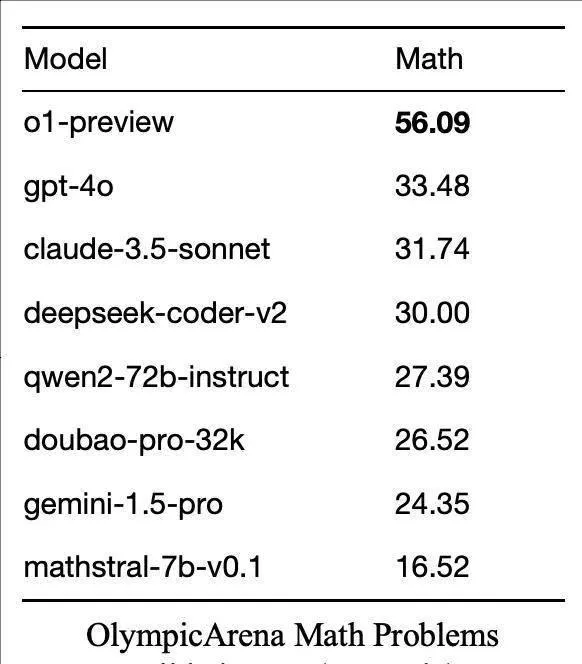
如圖所示,從 OpenAI o1 9 月 12 日釋出的過去三周內,該團隊對 o1 技術已經完成了系統化、多階段的探索。這個過程始於使用 OlympicArena 數據集對 o1 進行初步評估(如下表格),旨在全面了解其在多個學科領域的認知能力。研究的核心集中在 o1 思維結構的分析上,特別關註 "長思維" 這一關鍵概念。整個探索技術涉及多個復雜的步驟,包括獎勵模型的開發、在策略推理樹的構建,以及將這些元素整合為連貫的長思維過程。整個研究過程采用了叠代和並列的方法。進行了多次嘗試,不斷調整和完善技術和方法。評估過程包括定量和定性分析,結合人工檢查和專門的分析工具,以確保研究的準確性和有效性。

團隊強調了探索過程的重要性,而不僅僅關註最終結果。這種重視科研探索過程的思路與團推提出的 "旅程學習" 範式相一致,強調了在復雜、動態環境中不斷試錯、糾錯的持續學習和適應的重要性。透過這個過程,不僅獲得了關於 o1 技術的深入理解,還開發了一套探索未知 AI 技術的系統方法。研究過程涉及決策分析、挑戰辨識以及創新解決方案的開發。最終,這項研究不僅僅是對 o1 技術的探索,更是對先進 AI 系統研究方法的一次實踐和驗證。透過分享研究過程,包括成功和失敗的經驗,旨在為 AI 研究社區提供有價值的見解,促進該領域的集體進步。
這個探索過程展示了開放、協作的 AI 研究在推動技術邊界方面的重要性,為未來更復雜的 AI 系統研究提供了有益的參考和指導。
具體地,團隊凝煉了復現 o1 過程中的幾個關鍵問題,並做了非常細致的探索分享:
Q1: o1 的思維鏈是什麽樣子的?

表:基於對 OpenAI 提供的 o1 思維範例的詳細分析而建立的 其中包括八個用於解決復雜任務的推理步驟或 "思維" 例項。仔細檢查了每個範例,提取了相關特征,如標記數、行數和關鍵詞。
觀測:
為了理解 OpenAI 的 o1 的思維過程,團隊讓兩位博士水平學生仔細審查 OpenAI 的 o1 在解決數學問題時使用的推理過程。透過他們的詳細檢查,他們提取了反映 o1 如何處理和推理復雜方程式的底層思維鏈。這個結構化的思維圖在圖中有所展示。

圖:OpenAI o1 真實推理過程的結構化形式本質是一顆搜尋樹(數學題)

圖:OpenAI o1 真實推理過程的結構化形式本質是一顆搜尋樹(破譯題目)
經過這些探索,團隊確定需要構建的長思維數據應具有以下特征:
Q2: 長思維 (Long thought) 是如何工作的?
這是團隊認為重要的問題。然而,在當前的研究階段,該團隊僅僅提出了猜想。團隊認為還沒有足夠的經驗證據來驗證它們的準確性,這也是未來需要重點展開的工作。
o1 長思維方法的顯著成功可以歸因於在上述中介紹的旅程學習 (Journey Learning) 。與傳統的捷徑學習 (Shortcut Learning) 不同,旅程學習允許模型探索 整個決策軌跡 ,模仿人類的問題解決過程。這種全面的探索使 o1 能夠考慮 多種解決方案路徑,從錯誤中學習,並理解完整的問題解決過程 。透過經歷正確和錯誤的路徑,模型發展出強大的錯誤處理和自我糾正能力,增強了其適應新挑戰的能力。 這種方法培養了對問題領域更深入的理解,不僅僅是知道正確答案,而是理解為什麽以及如何得出答案 。旅程學習過程密切模擬人類的認知過程,包含試錯、反思和調整。這大大增加了模型輸出內容的可解釋性,因為 o1 可以提供詳細的解決步驟並解釋其推理過程,包括如何從錯誤中恢復。因此,基於旅程學習的 o1 長思維過程不僅僅是計算時間的擴充套件,還代表了一種徹底的、人類般的推理探索。這種方法使 o1 能夠處理更復雜的問題,提供更可靠和可解釋的答案,並在面對新挑戰時表現出更大的適應力,從而解釋了它在各種任務中的卓越表現。
Q3: 如何構建長思維?
嘗試 1:基於 LLM 和獎勵的樹搜尋 根據在 Q1 中對長思維的觀察,其最顯著的特征是在推理產生錯誤時或遇到冗余的推理步驟時嘗試反思和回溯。這類似於在推理樹上搜尋問題的解決方案,在錯誤節點處回溯,直到找到正確的解決路徑。為實作這一點,需要構建一棵推理樹,其中根節點代表問題,其他每個節點代表一個推理步驟。從根到任何節點的路徑代表從問題到該結論的推理過程。此外,回溯和反思必須基於錯誤的推理步驟,這需要一個更細粒度的獎勵模型(即過程級)來指示樹中每個節點的正確性。透過在具有過程級獎勵的推理樹上執行搜尋演算法,可以將錯誤步驟整合到思維鏈中,從而構建包含回溯和反思等行為的長思維。
嘗試 2:提議 - 批評迴圈 嘗試 1 透過基於預定義規則在樹上執行搜尋來構建長思維,但這限制了回溯和反思等行為的自由度。因此,團隊嘗試讓模型選擇自己當前的行為。團隊構建了一個提議 - 批評迴圈,其中為模型預定義了一些可能的行為(即繼續、回溯、反思、終止),並讓模型自身選擇行為來構建推理樹。如果樹沒有達到最終答案,可以將這個負面訊號告知模型,引導它反思和糾正其方法。
嘗試 3:多智能體方法 基於推理樹構建長思維存在幾個挑戰,包括存在許多冗余的無效節點,以及存在不依賴於反思行為的推理步驟,從而引起構建的長思維邏輯不一致。為解決這個問題,團隊設計了一個利用多智能體辯論的演算法,其中一個智能體充當策略模型,持續推理,而另一個智能體充當評論模型,指示策略模型是否應該繼續當前推理或執行回溯等行為。兩個智能體進行持續對話,在找到正確答案時自然構建長思維數據集。
嘗試 4:完整的人類思維過程註釋 當人類處理推理問題時,他們通常不會不斷地向前推理直到解決問題或失敗;相反,他們在無法繼續時會反思、回溯和重寫推理。這種行為與長思維的特征高度一致。因此,可以忠實且全面地記錄人類解決推理任務的過程,從而產生高質素的長思維。
Q4: 如何構建獎勵模型?
使用獎勵模型的第一步是定義粒度。團隊的目標不僅僅是關註最終結果,而是專門提高 LLMs 在反思、回溯和相關認知過程方面的能力。因此,團隊將評估粒度定義在步驟層面。具體來說,團隊使用來自 Abel 的微調數據,透過行號使解決方案變得清晰可辨。
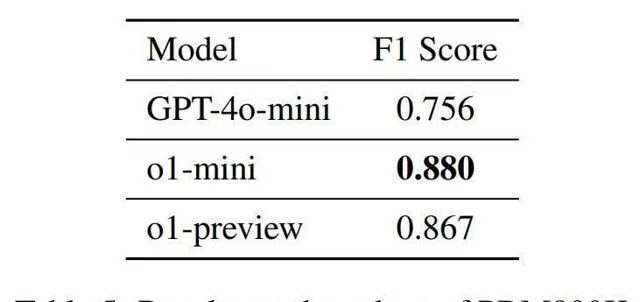
實作獎勵模型的過程可以使用開源模型或是呼叫閉源模型的 api。團隊比較了不同獎勵模型在 PRM800K 和 MR-GSM8K 子集上的元評估表現。如下表格展示了結果,其中,o1-mini 在不同數據集上表現最佳,證明其是一個良好的獎勵模型。

Q5: 如何構建 on-policy 推理樹?
構建推理樹需要一個能夠執行單步推理的策略模型。給定一個問題及其相應的最終答案,策略模型從問題作為根節點開始,不斷向樹中添加新節點。它首先生成 w 個可能的第一步推理步驟作為根節點的子節點。然後,它叠代地進行前向推理,為每個當前節點(如第一步推理)生成 w 個可能的後續推理步驟作為該節點的子節點。這個過程重復進行,直到達到預設的最大深度或所有葉節點達到最終答案。
策略模型和步驟分段 構建推理樹需要清晰定義推理步驟。為此,團隊采用 Abel 提出的數據格式,將數學問題解決方案轉化為具有清晰步驟的形式,將答案分成多行,每行以行號開始,並包含該行內的推理。因此,使用 Abel 數據集對 DeepSeekMath-7B-Base 進行微調,得到 Abel-DSMath,作為策略模型。在這種特定格式數據上微調的模型可以方便地控制單個推理步驟的生成。
獎勵模型和剪枝 上述提出的樹生成演算法計算成本高昂。當設定後續推理步驟數目為 3 和深度為 10 時,最後一次叠代需要生成 3 的 10 次方個推理步驟。因此,使用獎勵模型來剪除錯誤的推理步驟,提高操作效率。具體來說,團隊采用束搜尋,在每次叠代中只選擇少量候選項保留到下一輪。根據使用的獎勵模型,剪枝實作的細節有所不同。團隊嘗試了兩個獎勵模型:math-shepherd 和 o1-mini。
Math-shepherd 為每個步驟提供一個介於 0 和 1 之間的實數,表示當前步驟正確的概率。在樹生成的每次叠代中,對所有推理步驟進行評分,並選擇得分最高的前 K 個進入下一次叠代。這將總生成次數進行剪枝。然而,math-shepherd 在評估困難問題的推理步驟時存在困難,需要一個更強大的獎勵模型,能夠為每個步驟提供高準確度的正確性指示。因此,最終使用 o1-mini 為每個步驟提供獎勵,直接指示每個推理步驟是否正確。此時,在樹生成的每次叠代中,利用來自 o1-mini 的獎勵,選擇最多 K 個正確的推理步驟進入下一次叠代。
Q6: 如何從推理樹中推匯出長思維?
一旦構建了推理樹,目標就變為探索如何從推理樹轉換為包含試錯過程的長思維。在該團隊的框架中,推理樹的每個節點都被獎勵模型標註,指示該步驟是否正確或錯誤。具體的合成步驟如下:
為進一步簡化過程,套用了一個額外的約束:正確路徑上的每個節點最多允許 K 次試錯 —— 一次在錯誤路徑上的試錯和一次在正確路徑上的探索。 這些約束確保 DFS 遍歷專註有意義的試錯探索,同時避免過度探索錯誤路徑。在未來的實驗中,計劃移除或調整這些約束,以研究試錯路徑長度與最終模型效能之間的關系。
Q7: 如何評估我們的嘗試方法?

圖:透過可互動的數據分析平台視覺化構建的搜尋樹
除了使用特定評估指標在基準測試上測試準確率分數外,人工審查實際案例(輸入輸出)是評估數據和模型的關鍵步驟。因此,為了提供一種更直觀的方式來評估模型在特定問題上的表現,團隊構建了一個視覺化數據分析平台。
具體來說,視覺化平台包括合成樹及其對應長思維的視覺化,以及訓練模型的輸出。此外,在視覺化結果時,支持詳細的條件過濾,例如過濾正確或錯誤回答的問題,或輸出是否包含表示反思或猶豫的關鍵詞(如 "wait")。另外,視覺化平台支持不同叠代輪次的合成數據和模型輸出之間的比較,這使得團隊可以非常直觀地驗證新一輪的數據或模型是否有效。
Q8: 如何訓練我們的模型?
團隊實驗使用預訓練語言模型 deepseek-math-7b-base(更多其他模型已經在等待列表中)。訓練過程分為兩個主要階段:監督微調(SFT)和直接偏好學習(DPO)。
第一階段:監督微調(SFT):
SFT 過程包括兩個階段:
第二階段:直接偏好學習(DPO)
在這個階段,使用核采樣(top_p = 0.95 和溫度 T = 0.7)從 MATH Train 數據集為每個問題生成 20 個回復。這 20 個回復根據最終答案的正確性分類為正面和負面響應。從中,隨機選擇 5 個正面響應和 5 個負面響應來建立 5 對偏好對。然後,使用這些偏好對和 DPO 損失來訓練模型,使其能夠從正確和錯誤答案的比較中學習。
Q9: 什麽是人類和 AI 協同標註的有效策略?
團隊開發了一種人類和 AI 協作的數據標註流程,用於生成基於 MATH 數據集的高質素、長文本推理數據。透過這個流程,我們將短短幾行人類標註的解題方案擴充套件為包含數千個 token 的、符合 「旅程學習」 範式的詳細推理過程。在構建流程的過程中,我們發現了下面幾種有效的標註技巧:
遵循以上兩個關鍵要素,人類專家即可完成數據標註,這些數據精簡但準確,非常利於大模型做進一步增強。下一階段,透過設計復雜的提示詞,我們透過大語言模型實作了數據擴充套件和增強。我們的提示詞包含以下關鍵點:
為什麽科學進展報告很重要?
研究團隊表示:傳統發論文方無法適應新的科研範式,人工智能技術的快速發展開創了一個新的研究範式時代,其特點是 長期的、基於團隊的努力 ,通常持續六個月或更長時間。這種轉變雖然有利於突破性創新,但無意中給科學過程帶來了新的挑戰。長期團隊合作的內向性經常 導致向更廣泛科學界資訊流動的減少 。此外,這些專案的長期性質往往導致 研究人員滿足感的延遲,可能在整個研究過程中培養焦慮和動力減弱 。另外,大規模團隊專案的復雜性使得認可個人貢獻變得復雜,可能侵蝕傳統的學術激勵結構。團隊的進展報告方法 旨在透過增強透明度、促進即時反饋和認可,以及鼓勵對長期研究計劃的持續承諾來解決這些新出現的挑戰 。在這樣的背景下,團隊認為 」Scientific Progress Report「 (科研進展報告)是一種比 現在」Scentific Paper「 (科研論文)更有價值的科研產出和成果分享的組織形式。團隊科學探索過程的細致記錄,尤其在 AI 能力快速發展的背景下,具有深遠意義。 透過全面記錄探索過程,包括成功和失敗,團隊正在培育一個獨特而寶貴的數據集。這份全面的記錄對於訓練真正理解科學方法的 AI 模型至關重要。o1 的成功強調了 AI 系統不僅要學習結果,還要學習完整的科學探索過程,包括試錯的重要性 。透過科研進展報告,不僅可以捕捉技術細節,還包括決策理由、靈感來源和思維過程。這些 "人類因素" 對於訓練能夠進行真實科學發現的 AI 模型至關重要。
下一步探索
團隊根據的研究時間線和取得的進展,確定了幾個未來探索和發展的關鍵方向:
透過追求這些途徑,不僅推進我們對 o1 能力的理解和復制,還要推動 AI 研究方法的邊界。
核桃計劃

團隊借本專案正式引出 「核桃計劃」 (https://gair-nlp.github.io/walnut-plan),團隊成員表示:「對 o1 技術路線的探索及復現工作,僅僅是我們核桃計劃的一部份。核桃計劃旨在成為人工智能復雜推理和深度思考能力研究的開放先鋒,致力於推動 AI 從簡單的資訊處理工具演變為具備 "牛頓" 和 "愛因斯坦" 級別深度思考能力的智能系統。我們將著眼於更長遠的研究,最終的偉大願景是讓未來可以呈現 AI 驅動的科研範式,即 AI 完全具備參與人類科研的水準,從而更好地服務人類、改變世界。」











