
7月23日,據國外媒體報道,馬斯克在其社交媒體上宣布,旗下AI初創公司xAI已開始在位於田納西州的所謂孟菲斯超級集群(training cluster)上進行訓練,號稱這是「全球最強大的AI訓練集群」。
馬斯克在X平台的宣布截圖華爾街見聞
據馬斯克介紹,這個集群由100,000個液冷p00 GPU組成,這些芯片是輝達去年開始提供的。
馬斯克還表示,該集群在單個RDMA結構(即遠端直接數據存取結構)上執行。據思科介紹,這種結構可以在計算節點之間提供更高效、更低延遲的數據傳輸,而不會給中央處理器(CPU)帶來負擔。
馬斯克今年5月曾透露這一計劃 ,將輝達p00串聯到一台巨型的超級電腦中,並稱其為「算力超級工廠」。
當時,馬斯克匆匆忙忙地開始了Supercluster的工作,需要購買輝達「Hopper」p00 GPU。這似乎表明,當時這位科技大亨沒有耐心等待 p00 芯片推出,更不用說即將推出的基於 Blackwell 的 B100 和 B200 GPU。盡管預計較新的 Nvidia Blackwell 數據中心 GPU 將在 2024 年底之前發貨。

馬斯克新浪科技
xAI的目標是到2024年12月訓練出「按每項指標衡量都是全球最強大的AI」。馬斯克表示,孟菲斯超級集群將為實作這一目標提供「顯著優勢」。
不過,據外媒表示,不要對這一時間節點報太大期望,因為馬斯克以公開提出並錯過許多專案(如全自動駕駛汽車、無人駕駛出租車產品Robotaxi和將人類送往火星)的最後期限而聞名。
馬斯克周一還表示,特斯拉將在明年小規模生產用於內部使用的Optimus機器人,並希望到2026年能大規模生產供其他公司使用。這比他之前承諾的時間表晚了。之前馬斯克宣稱到2024年底將在特斯拉工廠使用Optimus機器人,並在2025年交付給其他公司。
另外,Microsoft正在與OpenAI行政總裁Sam Altman(阿爾特曼)合作開發一個價值1000億美元的AI訓練超級電腦,代號為Stargate。如果這一專案取得成功,xAI的孟菲斯超級集群可能不會長期保持全球最強大的AI訓練集群地位。
心智觀察所研究員潘攻愚認為,馬斯克一直標榜特斯拉是一家人工智能和機器人公司。特斯拉大型工廠三班倒一刻不停地進行數據搜集用於AI訓練,馬斯克需要近10萬塊p00用於特斯拉FSD自動駕駛服務,為下半年推出Robotaxi做準備。不過如此大量的采購有兩個挑戰,一個是能耗。目前p00全年總能耗已經超過了格魯吉亞等小國全年所有的電量;一個是從訓練到推理的跳躍,畢竟p00用於推理的性價比並不高,會造成很多算力的「通貨膨脹」。
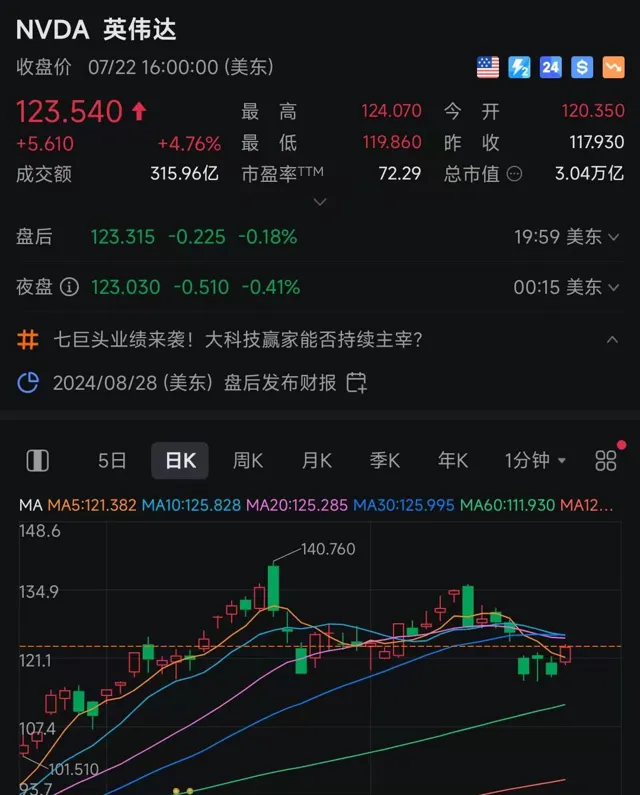
目前,輝達的股價正在走出另一波調整,馬斯克的最新言論為其註入一針強心劑。截至當地時間22日美股收盤,輝達上漲4.76%,特斯拉則上漲5.15%。
心智觀察所研究員呂棟指出,AI既是「暴力美學」,也是工程比拼,需要算力、演算法、數據的深度融合與經驗積累。
一方面,隨著計算量不斷攀升,單卡算力角色弱化,大模型訓練亟需一個超級工廠,即「大且通用」的加速計算平台,以縮短訓練時間,實作模型能力的快速叠代。隨著大模型參數量從千億邁向萬億,模型能力更加泛化,大模型對底層算力的訴求進一步升級,萬卡甚至超萬卡集群已成為競賽入場券。
另一方面,建設萬卡或超萬卡集群並非一萬張GPU卡的簡單堆疊,而是一項高度復雜的系統工程。算力集群不是一個計算GPU,怎麽把它組織成算力網絡,相互之間通訊效率怎麽提高,怎麽實作MFU(算力利用率)達到60%的最優目標,這些都要靠網絡通訊、計算、儲存一起來解決。只有軟硬件結合,把整個集群算力發揮到最高,才能實作1+1>2的效果。
另外值得註意的是,在比拼算力和演算法之外,如何將人工智能基礎設施化,賦能全行業,中國正在做人工智能賦能實體經濟的道路探索。
中國工程院院士、中國科學院計算技術研究所所長孫凝暉認為,算力基礎設施的中國方案需要具備「兩低一高」,即在供給側,大振幅降低算力器件、算力器材、網絡連線、數據獲取、演算法模型呼叫、電力消耗、營運維護、開發部署的總成本,讓廣大中小企業都消費得起高品質的算力服務,有積極性開發算力網套用;在消費側,大振幅降低廣大使用者的算力使用門檻,面向大眾的公共服務必須做到易獲取、易使用,像水電一樣即開即用,像編寫網頁一樣輕松客製算力服務,開發算力網套用。在服務效率側,中國的算力服務要實作低熵高通量,其中高通量是指在實作高並行度服務的同時,端到端服務的響應時間可滿足率高;低熵是指在高並行負載中出現資源無序競爭的情況下,保障系統通量不急劇下降。保障「算得多」對中國尤其重要。
當前,中國也正在掀起建設萬卡集群的熱潮,像華為、中國移動、摩爾執行緒等廠商都在布局萬卡集群。











