「如果說2023年大家可能都是朝著一個目標,就是去追趕GPT-3.5或者GPT-4的話,未來不同的機構、企業和團隊會朝著不同的方向去發展,更加多樣化。」上海人工智能實驗室領軍科學家林達華表示。
2023年是屬於大模型的一年,OpenAI釋出的GPT-4成為科技界的一個裏程碑,其接近人類的智能讓世界為之矚目,而對於國內的大模型來說,2023年是跟隨並追趕GPT-4的一年,【北京市人工智能行業大模型創新套用白皮書(2023年)】顯示,中國10億參數規模以上的大模型已超過200個,百模大戰之下,企業期待復制「大力出奇跡」。
在交流中行業人士認為,過去一年國內大模型讓人印象深刻的是「追得很快」,與GPT-4的距離有了明顯的縮小,但應謹慎樂觀的點在於OpenAI也在叠代。不過,國內大模型該從追趕GPT-4的目標中走出來了,其能力也到了一定高度,具備了向某些行業滲透的條件。
一方面,會有一些企業、機構繼續尋求基礎技術提升,另一方面,會有更多參與者探索向行業落地,「我相信這些探索能夠將大模型從去年能力的展現,變成真正能變革生產力的一個工具,這兩方面今年都會有巨大的競爭。」林達華說。
展望2024,ChatGPT 核心研發科學家、前 OpenAI 研究員肯尼斯·斯坦利和喬爾·雷曼稍顯冷靜,他們認為2024可能會面對的一個很大的問題是,人工智能會延續之前的發展勢頭,還是出現一些減緩,「2024年可能並不像我們期望的那樣具有劃時代的意義」。

「追得還是蠻快」
對國內大模型來說,追趕OpenAI是過去一年最大的命題,也是行業內外都在關註的一個話題。
站在當下來看,至少在對標ChatGPT-3.5的版本上,國內大模型接下了這個挑戰。在對談中第一財經問及過去一年國內大模型的突破,林達華表示,「印象深刻的進步就是追得還是蠻快。」
「ChatGPT剛出來時,覺得我們離3.5的版本有較大的距離,但是看到2023年下半年釋出的模型,尤其是一些表現不錯的頭部模型,在我們主客觀以及公開的評測中都對ChatGPT-3.5有了比較全面的超越。」林達華發現,國內的廠商和研究機構追趕ChatGPT的周期,比他一年前的預期更快,沒到一年基本已達到ChatGPT-3.5的水平。
當然,目前國內大模型還未完全追趕上GPT-4,但林達華認為,我們的距離有了較明顯的縮小,「因為GPT-4是一個相對固定的點,不斷往這邊追,距離一定是越來越小的。總體來看,國內最新釋出的一些模型表現讓人有驚喜,看起來事情會比原來預期會更樂觀一些。」
在國內大模型與GPT-4的客觀比較上,上海人工智能實驗室旗下大模型評測體系司南(OpenCompass2.0)近日釋出了對部份主流大模型的評測結果,可以作為一個參考。
在百分制的客觀評測基準中,GPT-4 Turbo(升級版GPT-4)在各項評測中均獲最佳表現,達到61.8分的及格水平。另外,分析結果顯示,不少國內廠商近期新釋出的模型在多個能力維度上正在快速縮小與GPT-4 Turbo的差距,包括智譜清言GLM-4、阿裏巴巴Qwen-Max、百度文心一言4.0的排名較為靠前,反映了這些新釋出的模型具有較為均衡和全面的效能。
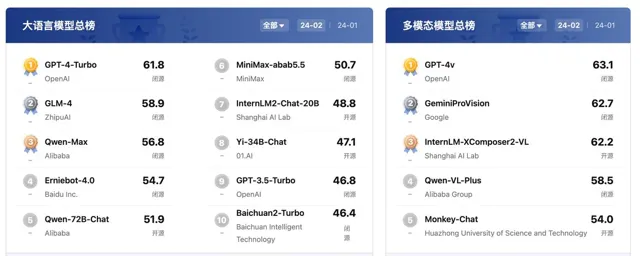
根據評測結果,推理、數學、程式碼、智能體是國內大模型的短板,但在主觀評測中,國內模型在中文場景下相比海外模型具有優勢,在中文語言理解、中文知識和中文創作上,國內營運模式相比GPT-4 Turbo具有極強的競爭力。
不過,在追趕過程中,GPT-4並非一成不變,「OpenAI的能力也在進步,後續會釋出的GPT-5也一定會超越前一代,不會完全停下來等待大家追趕,國內和國外的模型都需要往前去拓展自己的能力。」林達華表示。
復旦大學電腦科學技術學院教授、上海市數據科學重點實驗室主任肖仰華同樣對第一財經表示,如果限定一下,如在兩三年做到 GPT-3.5的版本和GPT-4的版本,是早晚能追上的事,但問題是對方也在叠代。他表示,「我們總體上還是屬於跟隨OpenAI的階段,即便從谷歌釋出的新的大模型來看,要追趕OpenAI也是很不容易的一件事,尤其是對於通用人工智能來說。」
「我們一直擔心的一個問題是,在通用人工智能這個賽道上只有第一沒有第二,因為它一旦突破了這個拐點,後面的增長是指數級的,而且有明顯的先發優勢,可以更快利用真實使用者的反饋,跑在一個快速叠代的道路上,且它已經形成了一定程度的商業閉環。」肖仰華說。
天工智能聯席CEO兼昆侖萬維2050全球研究院院長顏水成此前對第一財經表示,在國內以前研究大模型的團隊相對較少,主要原因是對算力資源的需求非常巨大而商業化前景不是非常明朗,2023年由於ChatGPT的成熟讓大家感覺AGI的時代已經來臨,國內在大模型上的投入產生了巨大的變化。
目前國內通用大模型的發展已經取得了一定的進展,但與OpenAI等國際領先企業相比,仍存在一定的差距,「OpenAI在自然語言處理領域的研究和套用已經積累了多年的經驗和技術優勢,其團隊成員中也擁有眾多的頂尖科學家和工程師。相比之下,國內的大模型研究和套用還比較年輕,需要更多的時間和努力來追趕。」顏水成說。
「夢幻般的一年」
拋開追趕不談,大模型行業在過去一年也有諸多技術進展。
「自ChatGPT在2022年底上線以來,對所有的行業從業人員來說,2023年都是夢幻般的一年,」肖仰華感慨,「這一年裏,ChatGPT在不到2個月裏突破了1億的月活,似乎大家一覺醒來就會見證一些新的技術到來。」
「我們IT研發人員,過去一年每天早晨都是一個新的開始,醒來最擔心的一件事是又發生了什麽新的技術變革,飯碗還能不能端得穩,很多新技術的名詞層出不窮,我們還沒有弄明白一個新概念是怎麽回事,另外一個更新的技術又冒出來了,我們似乎處於前所未有的技術加速發展的時代,唯一不變的是變化本身。」肖仰華說。
林達華認為,過去一年大模型有幾個關鍵的進展,一方面是3月初GPT-4的出現,讓大家看到大模型不僅僅是一個一本正經胡說八道的聊天工具,而是真正有用。另一方面,函數工具呼叫的能力、程式碼解釋能力的提升,讓大家看到了大模型向現實場景銜接的可能性和技術途徑,同時模型推理速度、效能的急劇提升,對於降低落地門檻也非常重要。
在肖仰華看來,大模型過去一年最明顯的進步是上下文視窗的文本長度限制有了很大的增長,從2k-4k提升到了128k,這意味著大模型能夠處理更大範圍的文本,更好地理解長篇文章或對話,使其在各種套用中更加有用。
在2020年的GPT-3模型中,上下文視窗的文本長度限制約為2k,在GPT-3.5中增加到4k。據OpenAI給出的參考,1k的文本單元(token)大約可以有750 個英文單詞或者 500個左右的漢字及標點。
在2023年更新的GPT-4中,大模型的文本容量限制提升到了32k,記憶長度是以往的8倍,而2023年11月更新的GPT-4 turbo版已能夠接收128k的輸入,基本相當於10萬字的小說長度,「也就是說現在整本書丟給大模型,它基本就能理解,不需要像以前要把它分成一段一段地丟進去。」肖仰華介紹。
國內大模型目前最大的文本長度已經來到200k。2023年11月大模型初創公司零一萬物釋出的模型Yi-34B,以及 2024年1月上海人工智能實驗室與商湯科技聯合香港中文大學和復旦大學釋出大語言模型書⽣·浦語2.0(InternLM2),都支持200k的長語境輸入。
「大模型本身所承載的是固定的記憶,但真正處理很多事情的時候,需要短期記憶,這段短期記憶不在其知識體系裏,因此模型能夠承載更多的長文互動資訊,對於它的落地很有用。」林達華介紹,有了長語境互動,大模型能夠讀幾百頁的財報,將裏面一些非常細致的資訊精準提取出來形成摘要,或者聽一場幾個小時的會議轉錄,並將會議的關鍵資訊摘取出來。
在技術上,大模型在多模態和數據的理解方面能力顯著增長,2022年底的ChatGPT主要還是以文本理解為主進行對話,但今天的大模型都聚焦於多模態的理解,「自然語言模型只能看懂語言,而多模態模型可以處理多種媒體數據,並將他們整合到統一的語意空間之中,如GPT-4可以進行看圖作答、數據推理、分析圖表等,GPT-4的多模態能力必將催生更加廣泛的下遊套用。」肖仰華說。
另外很值得關註的一個技術進步是成本,大模型最終要落地非常關鍵一件事是成本可控,以盡可能低的成本達到相同的效果。在2023年11月的開發者大會上,Open AI宣布包括GPT-4 Turbo在內全系列模型降價,輸入成本降低了三分之二,每輸入1k tokens的價格由0.03美元下降至0.01美元。對於開發者來說,使用 GPT-4的成本大幅降低。
肖仰華認為,GPT-4或許已經在成本控制技術上有所進步,業內猜測OpenAI用了大小模型協同提高了效率。「大模型本身模型越大使用成本越高,成本控制一個很基本的思想是,絕大部份真實的套用場景並不需要一個超大模型來服務,大部份問題可能是簡單的,相對規模小一點、成本低一點的模型就已經能解決問題,沒必要‘殺雞用牛刀’。」
林達華表示,實際上目前AI先進算力的租用成本一直高居不下,但隨著各種計算技術的最佳化,計算效率會持續提升,數據效率也會得到最佳化,帶來效率的提升和成本的下降。
「把大模型越做越大,投入在目前的階段肯定是增加的,但是套用方面,我們看到7B的甚至現在有一些更小的3B的大模型,也能在垂直領域帶來一個較為實用的水平,那大家在套用領域有可能會選擇體量尺寸更小的模型做一些具體的事。」林達華說,所有這些進步都會加快大模型在實際場景中的落地。
把「煉丹」變成科學
「2024年要面對一個很大的問題是,人工智能會延續之前的發展勢頭,還是出現一些減緩。雖然行業增長放緩會引起人們的擔憂,但這是可能發生的,這取決於研究中的未知因素。」在一場與復旦大學管理學院教授的對話中肯尼斯表示。
雖然過去一年大模型發展迅速,取得諸多進展,但在行業人士看來,目前的大模型離真正比肩人類的、可信的通用人工智能還有距離,無論是國內的模型還是GPT-4。
」過去人工智能興起核心的一點是大力出奇跡,堆更多的數據、用更多的算力,但只靠規模、只靠數據解決不了幻覺、可信和可控的問題。」上海人工智能實驗室主任助理、領軍科學家喬宇認為。
大模型目前存在一個重要的短板是復雜推理能力,最強如GPT-4 Turbo,即便已領先於國內的大模型,在這方面仍有很大的提升空間。復雜推理的能力關乎可靠性和準確性,是大模型在金融、工業等場景落地需要的關鍵能力。
隨著大模型進入商用,若要分析一家公司的財報、或是工業領域去分析一些技術文件,數學和計算能力就會成為一個關鍵點。「現在很多大模型的套用場景是客服、聊天等等,數學能力的影響可能不大,但如果是比較嚴肅的商業場合,模型‘一本正經地胡說八道’,將很難真正去落地。」林達華表示。
在未來,林達華認為,大模型的訓練不能單純只依靠互聯網數據的收集和灌註,而要更體系地構建。在復雜推理上關鍵是要構造很多過程性的內容,從互聯網上很難去大量獲取這些數據,「未來在模型的訓練數據上面,尤其是突破更高層次的智能的過程中,會越來越依賴構造型的數據,不是直接爬取下來的數據。」林達華認為。
肖仰華同樣提到,大模型的煉制過程和調教一個行業專家高度相似,整個過程尤其要註重高質素指令數據的收集,高質素指令數據可以提高底座大模型的價值,因此把大模型整個煉制過程變成科學的尤其重要。
「現在大模型的煉制非常像傳統的煉金術煉丹,把所有的數據往伺服器一丟,祈禱它出好的效果,實際上整個過程是不透明的,我們要把它變成透明科學的,現在仍然需要努力,其中很重要的是對語料做精準的刻畫,我們到底用什麽樣的語料能夠煉出什麽樣的能力,我們要建立之間的因果關系,這樣才有可能真正把大模型從‘煉金術’變成科學,這個過程中跨學科研究尤為重要。」肖仰華說。
林達華認為,未來會有頂尖的研究機構沿著更強的技術手段,如擴大規模、用更好的數據,或改進訓練的方法、模型架構,逐漸向通用人工智能靠近,這是一個核心技術層面的突破,也是頂尖研究機構的使命。
另一方面,雖然我們離通用人工智能還有距離,但這並不妨礙行業去探索落地。「人類要做的事分了不同的難度等級,現在已經打通第一關、第二關了,相關的初級套用就可以去做了。」林達華認為,大模型的能力已經到了一定的高度,具備了逐漸向某些行業滲透的條件。
在1月的達沃斯論壇上,OpenAI CEO山姆·奧爾特曼就表示,若GPT-4目前只能完成人類任務的10%,那麽GPT-5預計能處理15%至20%的任務。林達華認為,在大模型能將普通簡單的問題回答得非常好的情況下,有5%-10%的套用場景已經能開始滲透,隨著未來第三關的打通,或許能夠解鎖更多套用。
在落地場景上,林達華認為,從大模型的技術規律來說,會從對準確率、可靠性的要求由低到高的順序去滲透。「先從對於準確性要求沒那麽高的行業開始,如第一落地是聊天,然後慢慢是文章創作,但是接下來會朝著提升生產力的角度,如安裝在手機裏當助理,最後落地的是對於準確度可靠性要求極高的,如做手術或者操作精密儀器。」

百花齊放的生態
據【北京市人工智能行業大模型創新套用白皮書(2023年)】,截至2023年10月,中國10億參數規模以上的大模型廠商及高校院所共計254家,分布於20余個省市/地區。過去一年,自主研發大模型的企業包括互聯網大廠、AI領域的廠商、各類初創企業以及各垂直行業的企業、機構等。
「現在我們正經歷大規模的爆炸和重組,很多人湧入人工智能領域,我從沒想過他們會和人工智能有什麽樣的聯系,但好像突然之間每個人都與人工智能有關,這是一種過度飽和的現象。」作為OpenAI前研究員,肯尼斯提醒,加入已經形成的浪潮是有危險的。
但肯尼斯同時表示,如果個人真的非常擅長這個領域,那可能是好事,因為很明顯這是一個有利可圖的領域,「但如果你並不確信自己就是世界上最優秀的,那可能非常危險,因為世界上最優秀的人一定會和你競爭。」
在肖仰華看來,未來作為基礎設施的通用大模型註定只能留下頭部幾家,通用大模型如同電能、通訊網絡,一旦能落地千行百業,很容易形成頭部效應,「從這個意義上來講,(大模型)一定是往頭部集中,因為只有往頭部集中才能集中力量做出代表國家水平的大模型,如果資源精力很分散,那勢必就變成一堆小煉鋼爐。」
不過,從短期來看,肖仰華認為,不必一上來就整合行業,這也是一個自發的市場過程,「大家先各自‘煉’,到最後透過資本整合,逐步向一些有優勢的大模型去匯聚和集中,這有可能是未來一條發展的基本路徑。」
2023年中,對於國內的百模大戰,就有聲音認為這會是資源的浪費,彼時銜遠科技CEO周伯文認為,良性競爭是發展的助推器。如果只有一個通用大模型思路,就沒有辦法看到不同技術方向的叠代與對比,商業套用、學術創新和技術生態,都需要多元化。商湯科技智能產業研究院院長田豐也對第一財經提到,「必須要透過競爭才能出來一個更優秀的大模型」。
從大模型的幾個要素來看,肖仰華認為,企業機構要想勝出,真正核心的壁壘在於算力和數據,套用生態也是一個優勢。
「首先看誰優先布局了高端算力,因為高端算力的可用性是第一個資源因素,其次看能否匯聚盡可能多的高質素數據,尤其是一些有獨特價值的數據,是否有企業在這方面有它的獨特優勢,都是判斷玩家潛力的一些維度。第三是套用的生態,有一些企業本身套用生態很完善,這也會反向促進技術模型的發展。」肖仰華說。
不過,雖然將來幾個底座大模型可能往頭部企業匯聚,但大模型整個賽道非常寬廣,肖仰華表示,不求通用大模型做到最好,行業做得最好也是一種出路。
「大部份的企業家都會選擇一個獨特的賽道,做到國內第一或世界第一,而不會都去擠底座,」肖仰華發現,堅持在做底座的大模型目前看來也不多,「因為底座通用大模型的變現鏈條很長,過程也比較艱辛,長期得不到市場的正面反饋的話,這種研發也很難持續。」
「大模型可以做通用大模型,也可以做行業大模型、場景大模型,我們沒有必要在別人的賽道上去跟風。」肖仰華認為,國內制造業發達,制造領域最終可能也會有多個專業大模型,有些大模型要懂機械原理,有些要懂化合物,這些專業大模型都是將來有機會的方向。
「其實我們當時最擔心的是為了跟風ChatGPT而錯失下一個‘GPT’,大模型是一個百花齊放的生態,是很多元化的,我們不能因為跟風而錯失了下一個機會。」肖仰華說。











