7 月 23 日,Meta 正式釋出 Llama 3.1 模型,包含 8B、70B 和 405B 三種參數規模。其中 405B 是目前最大開源模型之一,擁有 4050 億參數,支持多語言輸入輸出,在復雜數學和即時生成內容方面表現出色。
為了給企業、開發者提供更多元的模型選擇,騰訊雲 TI 平台迅速響應,國內首批完成Llama 3.1的適配和上架,支持一鍵發起精調和推理。騰訊雲對該系列模型進行了精調、推理測試驗證,保障模型的可用性、易用性,可覆蓋智能對話、文本生成、寫作等多個不同場景。
此前,騰訊雲 TI 平台除了內建自研的騰訊混元大模型、行業大模型之外,也已廣泛接入了Llama 3、Baichuan、Falcon、Dolly、Vicuna、Bloom等市場主流開源大模型,支持快速發起訓練任務或部署推理服務,使用流程簡單,開發效率高。企業、開發者可以根據不同細分場景的業務需求,靈活選擇各類大模型,降低模型使用成本。
打造面向實戰的大模型精調工具鏈,助力企業智能化升級
騰訊雲TI平台致力於構建面向實戰的大模型精調工具鏈,幫助使用者訓練出真正可用的大模型,並縮短模型開發周期,提升研發效率與資源利用率。
平台在數據準備階段提供極致靈活高效的數據構建與標註能力,包括3大類數據處理pipeline,覆蓋有監督多輪問答、單輪問答和無監督預訓練,以及5大高質素處理環節,如原始數據分析、數據清洗、數據去重等。程式碼完全開源,支持使用者按需靈活修改。此外,平台還基於騰訊雲的實戰經驗,沈澱了覆蓋12大類LLM套用場景的100多萬條精調配比數據,智能分配配比數據量,解決過擬合或能力遺忘問題,有效提升模型效果。
在數據標註方面,騰訊雲TI平台升級面向LLM和多模態大模型的數據標註能力,首創基於Schema定義數據標註結構及元件,提供個人化標註操作台,實作業內最極致的多模態數據標註靈活性。
精調訓練階段,騰訊雲TI平台提供易用、穩定、高效的訓練工具。內建主流開源大模型及騰訊混元等自研模型,支持一鍵啟動精調任務。透過3層機制保障大規模訓練穩定執行,包括硬件容錯、容器排程、任務斷點續訓。基於自研的Angel訓練框架,整體提升30%的訓練效能,部份模型如baichuan2模型相比deepspeed加速70%,顯著提升任務成功率及資源利用率。
模型驗證評測階段,騰訊雲TI平台貼合演算法真實使用流程,提供輕量體驗、客觀評測、主觀評測三階段評測能力。輕量體驗透過線上問答形式體驗模型效果,確保模型訓練過程不出現大偏差;客觀評測使用業界主流開源評測集進行自動化評估;主觀評測則透過業務人員人工標註打分,保障最終模型效果。
同時,為了簡化開發流程,騰訊雲TI平台還對外開放API介面和豐富的SDK,開發者可以輕松地將Llama 3.1等模型整合到自己的套用中,無需進行復雜的配置和改動,顯著提升了開發效率和套用的叠代速度。
持續推動大模型生態建設,加速模型套用場景落地
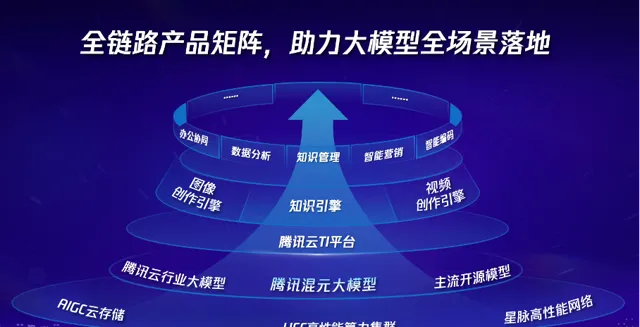
目前,騰訊在大模型領域已經構建了一套全鏈路產品矩陣,涵蓋從底層豐富基礎設施到頂層多元智能套用。包括自研通用大模型、模型開發平台、智能體開發平台,以及針對不同場景客製的智能套用解決方案等。透過這些產品和方案,致力於助力企業客戶高效地將大模型技術套用到實際業務場景中,實作快速部署和價值創造。
在醫療行業,騰訊雲攜手上海市數碼醫學創新中心,共研醫學大模型,目前在瑞金醫院實作了總檢報告和電子病歷生成等相關專案的落地套用。以體檢報告生成為例,平均每5秒即可自動生成一份總檢報告,為醫生節約50%+的撰寫時間。
在文娛行業,閱文集團一直利用大模型能力持續提升其使用者寫作和插圖制作效率,但面臨模型叠代快、更新復雜和推理成本高昂等問題。騰訊雲TI平台的套用簡化了模型訓練配置,透過加速框架提升了推理速度,同時提供了易於使用的管理工具,助力持續解決上述難題。
大模型時代,算力、網絡、數據構成了底層基礎設施的「鐵三角」。除了提供一站式AI大模型服務之外,騰訊雲還為客戶提供了HCC高效能計算集群、星脈高效能計算網絡以及向量數據庫等基礎設施服務。
不斷為千行百業打造行業大模型解決方案的同時,騰訊雲也在積極參與行業大模型標準的制定。在金融領域,騰訊雲與信通院合作,釋出了國內首個金融行業大模型標準,為智能化發展和大模型的安全合規提供了支持;在醫療健康領域,騰訊參與編寫的【人工智能大模型賦能醫療健康產業白皮書(2023年)】已釋出,旨在推動醫療健康大模型的發展並提出標準建議。
與此同時,騰訊還被選舉為全國信標委人工智能分委會委員兼副秘書長單位,作為核心成員,承擔了更多標準制定工作以及技術引領作用。未來,騰訊雲將持續最佳化技術,推動大模型生態建設,加速千行百業套用落地,為各行業的數碼化轉型提供有力支持。











