機器之心報道
機器之心編輯部
谷歌在人工智能領域又一次取得了重大進展。
在最新發表的一篇論文中,研究者建立了一個神經網絡,可以在不使用傳統遊戲引擎的情況下為經典射擊遊戲【淪陷戰士】生成即時遊戲畫面。
這個名為 GameNGen 的系統標誌著人工智能領域向前邁出了重要一步,它在一個芯片上以每秒 20 幀的速度生成可玩的遊戲畫面,每幀畫面都由擴散模型進行預測。
可以說,這是第一個完全由神經模型驅動的遊戲引擎,可以高質素地在長軌跡上與復雜環境進行即時互動。
這一成就標誌著人工智能首次完全模擬了一款復雜的影片遊戲,GameNGen 執行在單個張量處理單元 (TPU)(谷歌客製的人工智能加速器芯片)上,能夠以驚人的效率處理【淪陷戰士】復雜的 3D 環境和快節奏的動作,而且完全不需要遊戲引擎的常規元件。
隨著這項研究的釋出,大家的討論居高不下。

要知道,2018 年的畫面還是模糊不清的:
現在無論從畫面質素還是流暢度,都表現的更好:
很多人認為這項研究簡直不可思議:

致力於將生成式人工智能整合到遊戲引擎中的開發人員表示:「人們可能還不明白這有多瘋狂,這項研究是構建虛擬事物的基礎,他們現在有了一條清晰的技術路徑,可以使用對世界的模擬來實作連貫、互動式的長篇生成。將來,這項技術可以推廣到能夠獲取數據的任何影片遊戲。隨後很可能為尚不存在的遊戲生成數據。因此會有新遊戲誕生。這將變得更加瘋狂。」
「未來,遊戲中的每一個像素都將是生成的,而不是渲染的。」

「這太瘋狂了,即使以目前的發展速度,我也沒有預料到這一切會來得如此之快。」

不過,面對一眾的好評,還是有人提出了相反的觀點,比如這位網友表示:「雖然這項研究很有趣,但並沒有解決任何問題。它沒有創造任何新東西,它並不比其他任何研究更有效率,可以說是一個很好的實驗,但你基本上不能用它做任何事情。」
不論大家對 GameNGen 的評價如何,這項研究具體如何實作的,我們接著往下看。
論文介紹
遊戲想在電腦上執行起來,要跑通這個迴圈:(1)收集使用者輸入(2)更新遊戲狀態(3)渲染為螢幕像素。這個高幀率執行的遊戲迴圈為玩家創造了一種互動式虛擬世界的體驗。
我們玩的遊戲大多是在普通的電腦上執行的,雖然現在也有人能用小算盤玩【原神】,效果也很不錯。然而,無論這些器材多麽先進,它們實際上只是在做一件事情:按照遊戲開發者事先編寫的指令來執行遊戲。此外,雖然遊戲行業采用不同的引擎來制作遊戲,但這些引擎在工作時,比如重新整理遊戲裏 NPC 的位置,都在遵照開發者預設的程式碼或配置。
近年來,生成模型在影像和影片方面取得了重大進展,比如 Stable Diffusion、Dall-E。我們可以想象,模擬電子遊戲的互動世界似乎與影片生成類似。然而,互動世界模擬不僅僅是非常快速的影片生成,還要求在整個生成過程中以可用的輸入動作流為條件,這打破了現有擴散模型架構的一些假設。
因此,人們自然會問:神經模型能否高質素地即時模擬復雜遊戲?
本文,來自谷歌、特拉維夫大學的研究者給出了肯定的答案。
具體來說,他們展示了一款復雜的影片遊戲【DOOM】(淪陷戰士),可以在神經網絡上(Stable Diffusion v1.4 的增強版本)即時執行,同時實作與原始遊戲相當的視覺質素。雖然不是精確的模擬,但神經模型能夠執行復雜的遊戲狀態更新,例如計算彈藥、攻擊敵人、破壞物體、開啟門等。

人類玩家在 GameNGen 上以 20 FPS 的速度玩【淪陷戰士】。
研究者提出了 GameNGen,這是第一個完全由神經模型驅動的遊戲引擎,能夠在長軌跡上高質素的與復雜環境進行即時互動。GameNGen 可以在單個 TPU 上以每秒 20 幀以上的速度互動模擬經典遊戲【淪陷戰士】。下一幀預測實作了 29.4 的 PSNR,與失真 JPEG 壓縮相當。
GameNGen 的訓練分為兩個階段:(1) RL 智能體學習玩遊戲並記錄訓練過程;(2) 訓練擴散模型以根據過去幀和動作的順序生成下一幀。條件增強功能可在長軌跡上實作穩定的自回歸生成。

論文地址:https://arxiv.org/pdf/2408.14837
專案主頁:https://gamengen.github.io/
論文標題:DIFFUSION MODELS ARE REAL-TIME GAME ENGINES

影片連結:https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650931999&idx=1&sn=9f5126384e7d3ca7e8ec0b93d1bc5cbb&chksm=84e7c761b3904e776c3a18d411e95fbceddd96e1626fd51e3096be4a38e162f34962fe2ba98e&token=1390133831&lang=zh_CN#rd
方法介紹
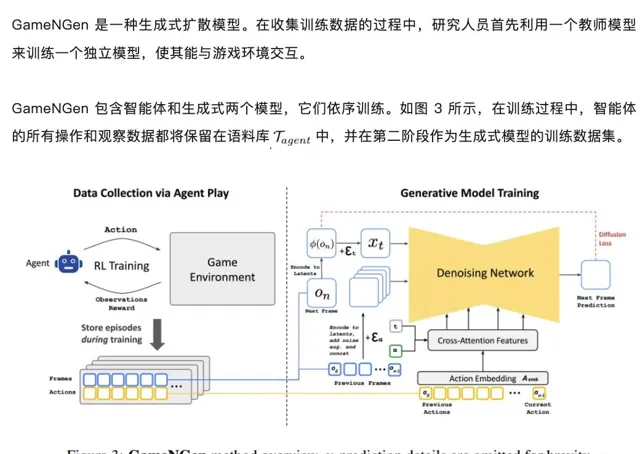
訓練生成式擴散模型

使用雜訊增強減輕自回歸偏差
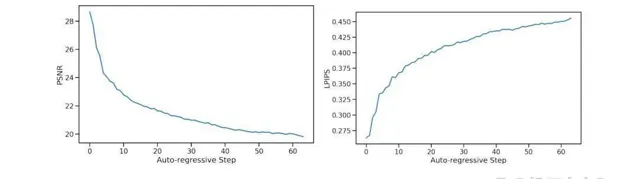
如圖 4 所示,訓練時使用了教師強制與自回歸采樣兩種方法。然而,這兩種方法的轉換不可避免地引發了誤差累積,進而導致樣本質素迅速下降。為了避免這種偏差,研究人員在訓練時向編碼幀添加了不同量的高斯雜訊來破壞上下文幀,同時將雜訊水平作為輸入提供給模型。
為了做到這一點,他們均勻地采樣了一個最大值內的雜訊水平 α,將其離散化,並針對每個雜訊區間訓練一個嵌入向量。這種方法能讓模型學會如何在有幹擾的情況下,如何糾正之前幀中的錯誤資訊。在推理過程中,可以控制輸入的雜訊水平,達到最優的訓練效果。在推理階段,透過調節輸入的雜訊水平,可以最佳化模型輸出的質素。值得註意的是,即便在不添加額外雜訊的情況下,這種方法也能顯著提升結果的表現。

微調潛在解碼器
由於 Stable Diffusion v1.4 的預訓練自動編碼器會將 8x8 像素塊壓縮成 4 個潛在通道,導致模型在預測遊戲幀時會產生偽影。這些偽影會讓一些小細節變得不夠完美,比如遊戲界面底部的那些小圖示。針對這個問題,研究人員僅對自動編碼器的潛在解碼器部份進行了微調,采用 MSE(均方誤差)作為目標幀像素的損失函數。
值得註意的是,這個微調過程完全獨立於 U-Net,且不會對自回歸生成過程產生影響。研究人員的操作僅限於潛在變量層面,而非像素層面。
實驗
總體來說,就影像質素而言,本文方法在長軌跡上實作了與原始遊戲相當的模擬質素。

影像質素:圖 5 顯示了模型預測的影像和相應的真實影像之間的對比。

影片質素:如圖 6 所示,預測的軌跡在內容和影像質素方面與實際遊戲相似。
人類評估:研究者向 10 位人類評分員提供了 130 個隨機短片(長度分別為 1.6 秒和 3.2 秒),並將模擬的遊戲與真實遊戲並列播放。評分員的任務是辨識真實遊戲。在這些測試中,評估者選擇真實遊戲而非模擬的比例分別為 58% 和 60%
為了消除雜訊增強的影響,該研究訓練了一個沒有添加雜訊的模型。圖 7 中報告了每個自回歸步驟的平均指標值,總共 64 幀。












