大模型訓練對算力基礎設施的要求從單卡拓展到了集群層面,這對大規模卡間互聯的相容性、傳輸效率、時延等指標提出了更高的要求。近日,中國移動研究院網絡與IT技術研究所主任研究員陳佳媛在公開演講中盤點了大模型發展的最新趨勢,萬億參數大模型對於計算集群和互聯技術的最新要求,並提出全向智感互聯(OISA)的設計方案,以突破大規模卡間互聯的技術瓶頸。
大模型發展仍遵循尺度定律
當前,大模型的發展呈現三大技術趨勢:從規模來看,大模型的技術發展總體上遵循尺度定律(ScalingLaw),參數規模從千億擴充套件到萬億,業界已出現多個萬億參數模型,十萬億模型即將出現,且隨著參數量的增大,大模型處理問題的能力也隨之增強,例如,GPT-4(1.8萬億參數量)在處理復雜任務方面的能力已經遠超GPT-3.5(1750億參數量)。從模型泛化程度來看,模型結構在原有Transformer的基礎上,引入了擴散模型、MoE(混合專家模型) ,使得模型的泛化能力增強、效能提升,大模型從支持自然語言的單一模態下的單一任務,逐漸發展為支持語音、文字、影像、影片等多種模態下的多種任務。從架構來看,模型架構正從資源密集的稠密結構向資源節約的稀疏結構轉變,透過只啟用部份神經元,展現出與稠密結構相媲美的效能。
對於大模型企業而言,能否搭建起大算力的基礎設施成為能否實作大模型創新落地的關鍵。由此,國內外大型科技公司正在積極投建萬卡集群智算中心。例如,OpenAI用25000張A100訓練GPT-4。

大型科技公司建立的萬卡集群智算中心
萬億模型對卡間互聯提出了更高的要求
大模型訓練參數量的提高引發了業界對支撐該訓練所需智算器材形態的思考:新一代智算器材需要具備更高密度的算存硬件、高效能無阻塞的網絡連線以及更高並列度的訓練策略和通訊範式。
首先,萬億模型對卡間互聯效能提出了更嚴苛的要求。
千億模型的通訊將伺服器作為節點,單節點的通訊要求集中在8卡以內。而在萬億參數量模型中,網絡節點成為由百卡組建的「超節點」,同時MoE(混合專家模型)及並列策略被引入AlltoAll通訊,其特征是單次通訊數據量小,但通訊頻繁,對高頻寬、低時延的要求更為迫切。陳佳媛認為,伺服器的發展方向是TP(張量模型並列)效率提升,實作數據在所有的GPU之間充分計算。
其次,萬億模型需要包含交換芯片的互聯拓撲。
當智算中心向百卡級別的全互聯方向演進,傳統的直連拓撲結構不再適用,迫切需要轉向更高效、更先進的互聯拓撲設計。在十億或中等模型中,互聯拓撲以橋接的形式實作,可以支持至多四卡的互聯,單卡最大吞吐量為3個埠;在千億參數模型中,國內主流方案中,互聯拓撲透過直連拓撲,以Cube Mesh或全互聯方式實作,Cube Mesh支持通訊需求從4卡拓展到8卡,單卡最大吞吐4~6個埠,全互聯方式則可實作8卡全互聯,單卡最大吞吐為7個埠,P2P頻寬為幾十個GB;而輝達則透過8卡交換 全互聯方式實作,可將P2P頻寬提升到百GB級別。
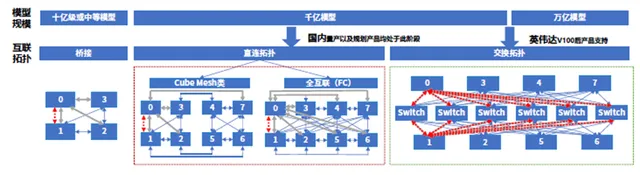
不同規模模型互聯拓撲方式對比
再次,萬億模型需要異構芯片之間構建大容量統一記憶體池。
模型規模的增長帶來了對GPU視訊記憶體容量需求的提高。單顆芯片往往難以滿足對超大視訊記憶體的需求。AI業務如搜尋引擎、廣告投放和推薦系統等,涉及大量數據處理、復雜演算法計算和精密系統控制,這要求CPU、GPU、xPU等多個芯片能夠高效協同作業。原有異構芯片連線基於PCIe實作,數據搬運速度慢,同時頻寬受限,因此需要建立多異構芯片統一記憶體池,既在執行流程上實作多處理器記憶體一致性存取,又實作近TB/s級頻寬能力。透過多異構芯片的互聯實作統一記憶體池,能夠提高視訊記憶體效能、提升開發效率,促進CPU/GPU/xPU有效協同。
突破GPU卡間互聯技術瓶頸
當前,單芯片算力還跟不上生成式AI爆發性的需求。為滿足需求,各半導體廠商紛紛推出效能更優的伺服器芯片及更新的互聯技術:行業標桿輝達陸續推出超級芯片(SuperChip:Gp00和GB200);Intel Gaudi2采用8卡全互聯拓撲,每個Guadi2芯片透過21個100Gb RoCEv2埠與其它7個芯片互聯;AMD MI300X透過7個AMD Infinity Fabric連結組建8卡全互聯拓撲。相比輝達,盡管上述兩款芯片具有較強的GPU互聯能力,但由於缺少交換芯片,組建更大規模的縱向擴充套件集群面臨挑戰。
為解決這一問題,陳佳媛提出四個攻關方向:
第一,突破算力間交換芯片效能瓶頸。提高卡間互聯頻寬,提升埠數量以滿足集群算力縱向擴充套件升級需求;低延遲通訊,減少GPU通訊跳數,最佳化數據傳輸路徑。
第二,實作超百卡大規模物理連線。統籌單層、分層的網絡拓撲結構,提高GPU間高速通訊設計的點對點連線能力,實作P2P連線;最佳化GPU記憶體管理、計算和通訊的重疊,實作軟硬件協同。
第三,提升協定層面的互聯效率。在演算法層面,兼顧流量控制和擁塞控制條件下,實作低時延的傳輸效能;在協定層面,使主流協定滿足傳輸需求;在封包結構層面,保證封包格式同時滿足多種AI套用需求。
第四,要保持智算縱向擴充套件過程中的生態開放,其中包括保持遵循開放的行業標準,實作跨行業的廣泛合作和建立開放的資訊共享機制。
陳佳媛 由此提出全向智感互聯的設計,其內涵包括:全方位連線,使GPU可以與任何一張GPU實作對等通訊;最佳化的報文格式,采用對GPU友好的報文格式提高網絡利用率,設計具備動態規模感知和簡化機制的協定;實作高效物理傳輸,最佳化解串器 、控制器等實體層元件,引入CPO/NPO降低功耗並提高訊號完整性;靈活擴充套件,當需要增加更多GPU以提升計算能力時,新的GPU可以無縫融入現有互聯網絡中。
陳佳媛將這種設計架構稱之為OISA——全向智感互聯。其關鍵技術特征在於架構、物理、鏈路、事務等幾個核心最佳化點。在架構層面最佳化拓撲結構,引入高效能交換芯片和GPU-交換 IP來提升P2P頻寬和研發效率。在實體層,改進訊號傳輸技術,減少雜訊和幹擾,提高訊號質素和完整性,采用更先進的物理介質提高數據傳輸效率,最佳化高速高能效的電互聯介面解串器 IP。在鏈路層,最佳化錯誤檢測和快速恢復技術,減少數據傳輸中的丟包和重傳,采用多個物理鏈路提供更高的頻寬和冗余路徑。在事務層,精簡事務層協定,降低開銷,提高數據處理速度,重定義報文頭,增加GPU標識提高傳輸效率。
作者 丨姬曉婷
編輯丨張心怡
美編丨馬利亞
監制丨連曉東











