
我懷疑有些人會指責我設定引誘性標題。其他人會說,這並不是真正的範圍——大多數人在最初的人工智能嘗試中都會失敗,但這並不重要,學習是值得的。在某種程度上,兩者都是對的——但我認為為什麽企業會失敗是值得探索的,並且可能讓我們的一些讀者至少在他們走得太遠之前重新評估。
企業人工智能戰略將在2024年失敗,因為它們專註於模型,而不是數據。為基礎模型選擇什麽遠不如訓練它所依據的數據重要。如果您的數據和數據基礎設施建立在錯誤的基礎上,那麽您對向量數據庫的選擇就無關緊要了。
這似乎是不言而喻的,但我們與企業交談,真正的大企業有很多聰明人,我們可以肯定地告訴你,組織動力導致其中一些企業認為模型下降而不是數據上升。這是一個嚴重的錯誤。

你必須從數據開始。構建適當的數據基礎架構。然後想想你的模型。
如果考慮過程是購買一些 GPU 並重用現有的數據基礎設施,那麽您將失敗。您現有的數據基礎架構可能是一堆 SAN/NAS 器材。它們無法擴充套件。結果是,您將對公司數據的一小部份進行訓練,並且您將獲得一小部份價值。鏈的強度與其最薄弱的環節一樣快,而您的 AI/ML 基礎設施的速度僅與最慢的元件一樣快。如果您使用 GPU 訓練機器學習模型,那麽您的薄弱環節可能是您的儲存解決方案。Keith Pijanowski 稱其為「饑餓的 GPU 問題」。當您的網絡或儲存解決方案無法以足夠快的速度將訓練數據提供給訓練邏輯以充分利用 GPU 時,就會出現 GPU 匱乏問題。
我們有點超前了。讓我們從數據應該是什麽樣子開始。
完整且正確:如果您願意,可以將其稱為「幹凈」數據。清潔度級別會顯著影響 中LLMs的基礎計算和向量表示。高質素的語料庫對於微調和 RAG 至關重要。它必須包括代表組織正確和真實表示的文件/內容,以生成正確的輸出。這對培訓效率有影響。不完整的數據集會阻礙模型的學習過程,導致訓練效率低下和對新數據的泛化能力差。最後,還有偏置放大。不正確的數據,尤其是系統性偏差,可能導致模型內偏差的放大,影響公平性和道德考慮。
擴充套件:這需要獲得足夠的數據。如果您的基礎結構導致您人為地限制可以使用的數據量和/或類別,它將限制您生成的價值。例如,在檢索增強生成中,擁有大量數據允許LLM從龐大的資訊庫中提取數據,使其能夠提供更細致和更明智的答案,類似於咨詢藏書豐富的圖書館。這同樣適用於使用 AI 進行日誌分析。是的,大多數情況下,該值位於最近的數據中,但這並不意味著該值不會擴充套件到較舊、較大的數據視窗。如果基礎結構決策限制了可以分析的數據量,則會影響模型輸出。
新近度:雖然我們剛才談到了更長的視窗和更多的數據,但這顯然是有限制的。該數據不能過時以至於不再有效。特定領域的專業知識在這裏很重要。例如,對於技術、金融或時事等動態欄位,超過 6-12 個月的數據可能被認為太舊。相比之下,對於穩定或歷史領域,幾年前的數據仍然很有價值(例如,關於伯羅奔尼撒戰爭的新資訊有限)。必須使數據的年齡與LLM模型的特定用例和相關域的變化率保持一致。
一致性:數據一致性是指數據集中數據的一致性、準確性和可靠性。它確保數據在其從收集到處理和分析的整個生命周期中保持不變,為 AI 模型提供穩定和連貫的基礎,以便從中學習和做出預測。因為LLMs,不一致的數據會破壞語言模式的學習,導致文本生成或理解不準確。對於像拓撲數據分析這樣的方法,它分析了數據的形狀和結構,不一致可能會扭曲拓撲見解,從而影響復雜數據集的解釋。從本質上講,一致的數據類似於建築物的穩定基礎,確保人工智能的「結構」站穩腳跟並正常執行。
唯一性:數據唯一性對 an LLM 很重要,因為它確保了多樣化的訓練集,增強了模型泛化和理解不同上下文的能力。獨特的數據點可防止對重復資訊的過度擬合,從而LLM能夠更廣泛地理解並生成更具創造性、更準確的響應。它還支持對模型和 RAG 進行微調。
這是「幹凈」數據的有效起點。接下來是您的數據基礎架構選擇。數據基礎設施必須支持您的數據,而不是限制數據。您的數據基礎架構不能「強迫」您只檢視行和列中的數據。您的數據基礎架構無法限制您可以從影片或日誌檔中收集的內容。它必須啟用。
下面是現代數據湖的參考體系結構。將其用於 AI 等。
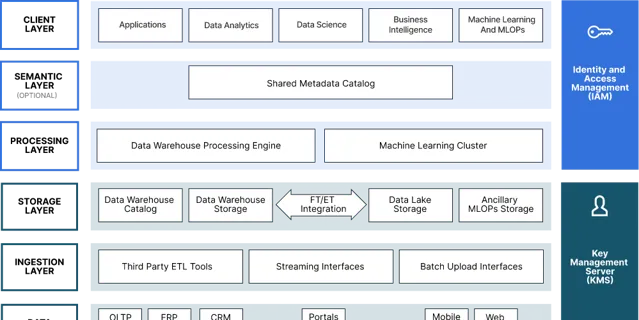
如果你願意,你可以開始用徽標來填充它。使用像 MinIO 這樣的工具的優勢之一是整個生態系將開箱即用。MLflow、Tensorflow、Kubeflow、PyTorch、Ray - 你明白了。
這裏的重點是,您希望將所有數據都放在一個儲存庫中(適當復制)。它支持更好的治理、存取控制和安全性。
這需要高度可延伸的東西,並且可以處理各種類別的數據。那將是一個物件儲存(一個現代的,同樣,電器在這裏沒有太多的實用性)。
您需要一些高效能的東西(吞吐量和 IOPS),而在這裏,現代物件儲存就是答案。你想要一些簡單的東西 - 因為規模需要簡單。你想要一些軟件定義的東西。您需要的秤需要商用硬件才能實作經濟效益。電器是一個糟糕的選擇。
你想要一些你控制的東西。這是你的數據,它是你整個人工智能工作所依賴的基礎。你不能把它外包給可能在幾個季度內與你競爭的人。構建您控制的 AI 現代數據湖。
你想要一些雲原生的東西。Kubernetes 是雲營運模式的作業系統。容器化和編排原生的數據基礎架構實際上是一項要求。
這需要一個可以跨數據中心和地理位置復制(主動-主動)的解決方案。
可能需要在國家/地區儲存一些數據,這也需要滿足。重點應該很清楚,數據需求定義了基礎設施要求,並為框架/模型提供了資訊。反之則不然。從數據出發並努力工作的公司將取得成功。這是構建功能性人工智能戰略的基礎。框架和模型很重要,但Alpha和歐米茄是數據。我們正在為數據第一的世界而建設,事實上,我們已經這樣做了十年的大部份時間。這就是為什麽 AI 生態系與我們一起開箱即用的原因。要了解更多資訊,請檢視我們的 AI 和 ML 解決方案頁面。它深入探討了使我們成為全球 AI 架構師選擇的特性、功能和效能。











