白交 發自 凹非寺量子位 | 公眾號 QbitAI
首屆ICLR時間檢驗獎,頒向變分自編碼器VAE。
這篇跨越十一年的論文,給後續包括擴散模型在內的生成模型帶來重要思想啟發,才有了今天的DALL-E3、Stable Diffusion。此外,在音訊、文本等領域都有廣泛套用,是深度學習中的重要技術之一。

論文一作、VAE主要架構師Diederik Kingma可是妥妥大佬一枚。現在他在DeepMind擔任研究科學家,曾是OpenAI創始成員、演算法負責人,還是Adam最佳化器發明者。
網友紛紛表示祝福:Well Deserved,並稱VAE改變了遊戲規則。


值得一提的是,榮獲亞軍的論文也同樣具有代表性,其參與者包括OpenAI首席科學家的Ilya、GAN的發明者Ian Goodfellow。
與此同時,傑出論文獎也悉數頒出。
首屆ICLR時間檢驗獎
首先來看榮獲時間檢驗獎的論文講了什麽。

概率建模是我們推理世界的最基本方法之一。這篇論文率先將深度學習與可延伸的概率推理(透過所謂的重參數化技巧進行攤平均值場變分推理)整合在一起,從而產生了變分自編碼器(VAE)。
委員會評價這項工作其持久價值在於它的優雅。用於開發 VAE 的原理加深了我們對深度學習和概率建模之間相互作用的理解,並引發了許多後續有趣的概率模型和編碼方法的開發。
傳統自編碼器有個問題,它學到的隱向量是確定的、離散的,也沒有很好的可解釋性,而且不能隨機采樣隱向量來生成新樣本。VAE就是為了解決這些問題而提出的。
VAE的核心思想是把隱向量看作是一個概率分布。具體而言,編碼器(encoder)不直接輸出一個隱向量,而是輸出一個均值向量和一個變異數向量,它們刻畫了隱變量的高斯分布。這樣一來,我們就可以從這個分布中隨機采樣隱向量,再用解碼器(decoder)生成新圖片了。
但是問題在於,這個隱變量的後驗分布很復雜,難以直接求解。
所以VAE的第二個關鍵思想是用一個簡單分布(例如高斯分布)去近似真實的後驗分布,並透過最佳化一個下界(ELBO)來訓練模型。
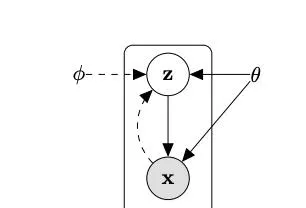
這個下界可以分解為兩部份:一部份讓生成的圖片更接近原始圖片,另一部份讓近似後驗分布更接近先驗分布(例如標準高斯分布)。直觀地說,這相當於在重構輸入圖片的同時,對隱變量分布進行了一個「規範化」。
為了讓這個下界能透過梯度下降來最佳化,VAE論文提出了一個重參數技巧,它把從分布中采樣的過程覆寫成從標準高斯分布采樣並進行線性變換。這樣梯度就可以直接反向傳播了。
這樣一來,VAE可以學習到數據的隱空間表示,並用它來生成新樣本。和傳統自編碼器相比,VAE學到的隱變量具有更好的可解釋性和泛化能力。
在實驗部份,論文在MNIST數據集上展示了VAE生成數碼影像的效果。

而這篇研究背後的作者同樣來頭不小。
Diederik P. Kingma博士畢業於阿姆斯特丹大學。曾是OpenAI創始成員之一、演算法團隊負責人,專註於基礎研究,比如用於生成模型的演算法。
離開OpenAI之後,他來到谷歌,參與到谷歌大腦、DeepMind團隊研究中去,他主導了一系列生成模型的研究,包括文本、影像和影片。除了VAE之外,他也是Adam最佳化器、Glow等發明者。谷歌學術被引超20萬次。
除此之外,他還有著天使投資人這一身份。
不過目前從Twitter介紹上看,他貌似已經離開DeepMind。

AI大牛Max Welling目前是阿姆斯特丹大學機器學習研究主席,也是MSR傑出科學家。

另外,同樣來自2013年的研究,來自谷歌、紐約大學、蒙特利爾大學的論文Intriguing properties of neural networks獲得了亞軍。

裏面還有不少熟悉面孔,比如那個消失的OpenAI聯創兼首席科學家Ilya Sutskever、GAN發明者Ian Goodfellow。
ICLR委員對這篇論文評價如下:
隨著深度神經網絡在實際套用中的日益普及,了解神經網絡何時以及如何出現不良行為顯得尤為重要。這篇論文強調了這樣一個問題,即神經網絡很容易受到輸入中幾乎難以察覺的微小變化的影響。這一想法有助於催生對抗性攻擊(試圖愚弄神經網絡)和對抗性防禦(訓練神經網絡使其不被愚弄)領域。
傑出論文獎
與此同時,本屆ICLR傑出論文獎也悉數頒出,共有5篇優秀論文獲獎、11篇論文獲得榮譽提名。
那麽主要來看看這5篇論文講了什麽。
Generalization in diffusion models arises from geometry-adaptive harmonic representations

這篇來自紐約大學、法蘭西學院的研究,從實驗和理論研究了擴散模型中的記憶和泛化特性。作者根據經驗研究了影像生成模型何時從記憶輸入轉換到泛化機制,並透過 「幾何自適應諧波表征 」與諧波分析的思想建立聯系,進一步從建築歸納偏差的角度解釋了這一現象。
這篇論文涵蓋了我們對視覺生成模型理解中的一個關鍵缺失部份,很可能會對該領域未來的重要理論研究有所啟發。
Learning Interactive Real-World Simulators

研究機構來自UC柏克萊、Google DeepMind、MIT、阿爾伯塔大學。匯集多個來源的數據來訓練機器人基礎模型是一個長期的宏偉目標。由於不同的機器人具有不同的感知-運動界面,這阻礙了大規模數據集的訓練,因此帶來了巨大的挑戰。這項名為 「UniSim 」的工作是朝著這個方向邁出的重要一步,也是一項工程壯舉,它使用基於視覺感知和控制文字描述的統一界面來聚合數據,並利用視覺和語言領域的最新發展,從數據中訓練機器人模擬器。
Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors

來自特拉維夫大學、IBM的研究深入探討了最近提出的狀態空間模型和Transformer架構對長期順序依賴關系的建模能力。令人驚訝的是,作者發現從頭開始訓練Transformer模型會導致對其效能的低估,並證明透過預訓練和微調設定可以獲得巨大的收益。
這篇論文執行得非常出色,在註重簡潔性和系統性見解方面堪稱典範。
Protein Discovery with Discrete Walk-Jump Sampling

基因泰克、紐約大學的研究解決了基於序列的抗體設計問題,這是蛋白質序列生成模型的一個重要套用。作者引入了一種創新而有效的新建模方法,專門用於處理離散蛋白質序列數據的問題。除了在矽學中驗證該方法外,作者還進行了大量濕實驗室實驗,在體外測量抗體結合親和力,證明了其生成方法的有效性。
Vision Transformers Need Registers

來自Meta等機構的研究,辨識了vision transformer網絡特征圖中的偽影,其特點是低資訊量背景區域中的高規範Tokens。作者對出現這種情況的原因提出了關鍵假設,並提供了一個簡單而優雅的解決方案,利用額外的register tokens來解決這些偽影問題,從而提高模型在各種任務中的效能。從這項工作中獲得的啟示也會對其他套用領域產生影響。
這篇論文寫得非常好,提供了一個開展研究的絕佳範例—發現問題,了解問題發生的原因,然後提供解決方案。
除此之外,本屆會議共收到了7262 篇送出論文,接收2260篇,整體接收率約為 31%。此外Spotlights論文比例為 5%,Oral論文比例為 1.2%。
參考連結:[1]https://arxiv.org/abs/1312.6114[2]https://x.com/yisongyue/status/1787910669477757207[3]https://blog.iclr.cc/2024/05/06/iclr-2024-outstanding-paper-awards/[4]https://blog.iclr.cc/2024/05/07/iclr-2024-test-of-time-award/











