編輯:編輯部 HYZ
【新智元導讀】 就在剛剛,輝達開源了超強模型Nemotron-70B,後者一 經釋出就超越了GPT-4o和Claude 3.5 Sonnet,僅次於OpenAI o1!AI社區驚呼:新的開源王者又來了?業內直呼:用Llama 3.1訓出小模型吊打GPT-4o,簡直是神來之筆!
一覺醒來,新模型Nemotron-70B成為僅次o1的最強王者!
是的,就在昨晚,輝達悄無聲息地開源了這個超強大模型。
一經釋出,它立刻在AI社區引發巨大轟動。

在多個基準測試中,它一舉超越多個最先進的AI模型,包括OpenAI的GPT-4、GPT-4 Turbo以及Anthropic的Claude 3.5 Sonnet等140多個開閉源模型。
並且僅次於OpenAI最新模型o1。

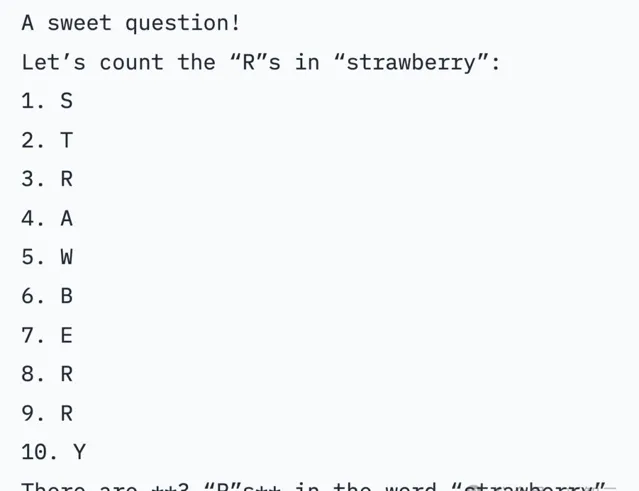
在即便是在沒有專門提示、額外推理token的情況下,Nemotron-70B也能答對「草莓有幾個r」經典難題。
業內人士評價:輝達在Llama 3.1的基礎上訓練出不太大的模型,超越了GPT-4o和Claude 3.5 Sonnet,簡直是神來之筆。


網友們紛紛評論:這是一個歷史性的開放權重模型。

目前,模型權重已可在 Hugging Face 上獲取。

地址:https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct-HF
有人已經用兩台Macbook跑起來了。
超越GPT-4o,輝達新模型爆火
Nemotron基礎模型,是基於Llama-3.1-70B開發而成。
Nemotron-70B透過人類反饋強化學習完成的訓練,尤其是「強化演算法」。
這次訓練過程中,使用了一種新的混合訓練方法,訓練獎勵模型時用 了Bradley-Terry和Regression。
使用混合訓練方法的關鍵,就是Nemotron的訓練數據集,而輝達也一並開源了。
它基於Llama-3.1-Nemotron-70B-Reward提供獎勵訊號,並利用HelpSteer2-Preference提示來引導模型生成符合人類偏好的答案。

在輝達團隊一篇預印本論文中,專門介紹了HelpSteer2-Preference演算法。

論文地址:https://arxiv.org/pdf/2410.01257
在LMSYS大模型競技場中,Arena Hard評測中,Nemotron-70B得分85。
在AlpacaEval 2 LC上得分57.6,在GPT-4-Turbo MT-Bench上為8.98。

能夠擊敗GPT-4o的模型,究竟有多強?
各路網友紛紛出題,來考驗Nemotron-70B真實水平。
測試開始!
「一步一步認真思考:我目前有兩根香蕉,我昨天吃掉一根,現在還有幾根」?
Nemotron-70B會將問題所給資訊進行分解,然後一步一步推理得出,最終的正確答案是2根。

評論區網友表示,來一道上難度的題「列出活到89歲的十位名人」。
不過,模型卻把某人的去世日期弄錯了,然而它不是一個推理題。

還有開發者要求它,將整個entropix的jax模型實作轉換成Pytorch格式,而且在零樣本的情況下,70B模型就完成了。

那麽,Nemotron-70B在hard prompt上的表現,是否值得推敲?

在如下測試中,顯然並沒有透過,但確實給出了一個非常有趣的初步輸出。
「考慮一個假設情況,如果月球只有25英裏遠,而一個人有太空服來保護自己免受太空環境的嚴酷影響,人類步行到月球是否合理?只回答最突出的要點。」
Nemotron-70B給出的回答是:
不可能,因為需要克服巨大的重力逃逸速度:即使月球只有25英裏遠,人類仍然需要克服大約2.4公裏/秒(5,376英裏/小時)的初始逃逸速度,才能從地球表面到達月球表面。步行速度最快也只有約5-6英裏/小時(8-9.7公裏/小時),遠遠不足以達到這個速度,使得步行到月球完全不切實際。

再來一道推理題,讓Nemotron-70B與GPT-4o一起PK「薛定諤的貓」實驗變體:
一只死貓被放入一個盒子中,盒子裏還有一個核同位素、一瓶毒藥和一個輻射探測器。如果輻射探測器檢測到輻射,它就會釋放毒藥。一天後開啟盒子。貓活著的概率是多少?

Nemotron-70B考慮很有特點的是,從一開始就考慮到貓就是死的,即便放在盒子一天後,仍舊是死的。
而GPT-4o並沒有關註初始條件的重要性,而是就盒子裏的客觀條件,進行分析得出50%的概率。

有網友表示,非常期待看到Nemotron 70B在自己的Ryzen 5/Radeon 5600 Linux電腦上跑起來是什麽樣子。
在40GB+以上的情況下,它簡直就是一頭怪獸。

芯片巨頭不斷開源超強模型
輝達為何如此熱衷於不斷開源超強模型?
業內人表示,之所以這麽做,就開源模型變得如此優秀,就是為了讓所有盈利公司都必須訂購更多芯片,來訓練越來越復雜的模型。無論如何,人們都需要購買硬件,來執行免費模型。
總之,只要輝達在客製芯片上保持領先,在神經形態芯片未來上投入足夠資金,他們會永遠立於不敗之地。

無程式碼初創公司創始人Andres Kull心酸地表示,輝達可以不斷開源超強模型。因為他們既有大量資金資助研究者,同時還在不斷發展壯大開發生態。

而Meta可以依托自己的社交媒體,獲得利潤上的資助。
然而大模型初創企業的處境就非常困難了,巨頭們透過種種手段,在商業落地和名氣上都取得了碾壓,但小企業如果無法創造利潤,將很快失去風頭家的資助,迅速倒閉。
而更加可怕的是,輝達可以以低1000倍的成本實作這一點。
如果輝達真的選擇這麽做,將無人能與之匹敵。

現在,輝達占美國GDP的 11.7%。而在互聯網泡沫頂峰時期,思科僅占美國GDP的 5.5%
最強開源模型是怎樣訓練出來的
在訓練模型的過程中,獎勵模型發揮了很重要的作用,因為它對於調整模型的遵循指令能力至關重要。
主流的獎勵模型方法主要有兩種:Bradley-Terry和Regression。
前者起源於統計學中的排名理論,透過最大化被選擇和被拒絕響應之間的獎勵差距,為模型提供了一種直接的基於偏好的反饋。
後者則借鑒了心理學中的評分量表,透過預測特定提示下響應的分數來訓練模型。這就允許模型對響應的質素進行更細節的評估。
對研究者和從業人員來說,決定采用哪種獎勵模型是很重要的。
然而,缺乏證據表明,當數據充分匹配時,哪種方法優於另一種。這也就意味著,現有公共數據集中無法提供充分匹配的數據。
輝達研究者發現,迄今為止沒有人公開釋出過與這兩種方法充分匹配的數據。
為此,他們集中了兩種模型的優點,釋出了名為HelpSteer2-Preference的高質素數據集。
這樣,Bradley-Terry模型可以使用此類偏好註釋進行有效訓練,還可以讓註釋者表明為什麽更喜歡一種響應而非另一種,從而研究和利用偏好理由。
他們發現,這個數據集效果極好,訓練出的模型效能極強,訓出了RewardBench上的一些頂級模型(如Nemotron-340B-Reward)。
主要貢獻可以總結為以下三點——
1. 開源了一個高質素的偏好建模數據集,這應該是包含人類編寫偏好理由的通用領域偏好數據集的第一個開源版本。
2. 利用這些數據,對Bradley-Terry風格和Regression風格的獎勵模型,以及可以利用偏好理由的模型進行了比較。
3. 得出了結合Bradley-Terry和回歸獎勵模型的新穎方法,訓練出的獎勵模型在RewardBench上得分為94.1分,這是截止2024.10.1表現最好的模型。
HelpSteer2-Preference數據集
數據收集過程中,註釋者都會獲得一個提示和兩個響應。
他們首先在Likert-5量表上,從(有用性、正確性、連貫性、復雜性和冗長性)幾個維度上,對每個響應進行註釋。
然後在7個偏好選項中進行選擇,每個選項都與一個偏好分數及偏好理由相關聯。

Scale AI 會將每個任務分配給3-5個註釋者,以獨立標記每個提示的兩個響應之間的偏好。
嚴格的數據預處理,也保證了數據的質素。
根據HelpSteer2,研究者會確定每個任務的三個最相似的偏好註釋,取其平均值,並將其四舍五入到最接近的整數,以給出整體偏好。
此外,研究者過濾掉了10%的任務,其中三個最相似的註釋分布超過2。
這樣就避免了對人類註釋者無法自信評估 真實偏好的任務進行訓練。
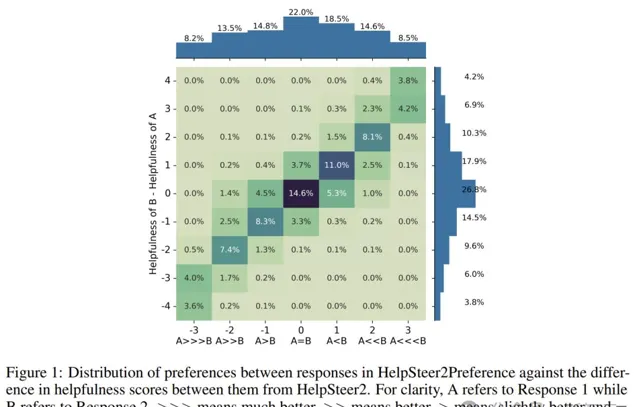
HelpSteer2Preference中不同回應之間的偏好分布與HelpSteer 2中它們的幫助評分差異之間的關系
研究者發現,當使用每種獎勵模型的最佳形式時,Bradley-Terry類別和回歸類別的獎勵模型彼此競爭。
此外,它們可以相輔相成,訓練一個以僅限幫助性 SteerLM 回歸模型為基礎進行初始化的縮放Bradley-Terry模型,在RewardBench上整體得分達到94.1。
截至2024年10月1日,這在RewardBench排行榜上排名第一。

RewardBench上的模型表現
最後,這種獎勵模型被證明在使用Online RLHF(特別是REINFORCE演算法)對齊模型以使其遵循指令方面,非常有用。
如表4所示,大多數演算法對於Llama-3.1-70B-Instruct都有所改進。

對齊模型的效能:所有模型均由Llama-3.1-70B-Instruct作為基礎模型進行訓練
如表5所示,對於「Strawberry中有幾個r」這個問題,只有REINFORCE能正確回答這個問題。

參考資料:
https://arxiv.org/pdf/2410.01257
https://huggingface.co/nvidia/Llama-3.1-Nemotron-70B-Instruct-HF











