簡介
大語言模型的英文全稱為:Large Language Model,縮寫為 LLM,也被稱為大型語言模型,主要指的是在大規模文本語料上訓練、包含百億級別參數的語言模型,它用來做自然語言相關任務的深度學習模型。
自然語言的相關任務簡單理解為:給到模型一個文本輸入,經過訓練的模型會給出相應的輸出文本。通常被用來解決常見的語言問題,如:文本分類、問答、總結和文本生成等。
大語言模型的局限性
隨著 ChatGPT 的出現,LLM(大型語言模型)的開發受到越來越多的關註,吸引了眾多企業的參與,包括 OpenAI 的 GPT-3、Google 的 LaMDA 和 PaLM、以及清華大學的 GLM 等。盡管 LLM 的強大潛力引發了廣泛興趣,但直接呼叫這些大模型進行編程也暴露出一些局限性,例如:
大語言模型套用框架
針對上述限制,直接呼叫大語言模型似乎並不是最佳選擇,因此出現了基於大語言模型的套用框架,旨在解決這些問題。
大語言模型的套用框架通常指的是使用已有的大模型進行各種自然語言處理任務時所采用的軟件架構或工具集,這些套用框架提供了一種便捷的方式,使得開發者能夠利用大語言模型的強大能力解決特定的問題。
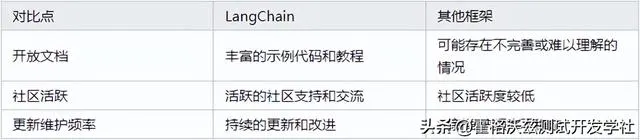
目前有多種大語言模型的套用框架,比如 LangChain 、AutoGPT 等其他大語言模型。而 LangChain 的社區生態、更新速度、熱度包括融資情況都占據了不小的優勢。包括 LangChain 的設計理念,兼具易用性(LCEL)與很強的拓展性,都成為學習大語言模型套用框架的首選
如何學習大語言模型套用框架
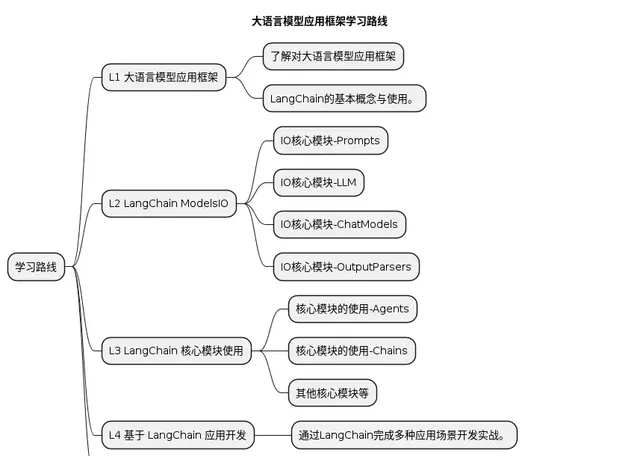
學習大語言模型套用框架應當循序漸進,所以本課程主要分為 5 個模組,從 L1 ~ L5,由淺入深帶大家進行學習。
總結
- 了解什麽是大語言模型套用框架。
- 了解大語言模型套用框架的套用場景。
- 了解常見的大語言模型套用框架。
- 了解大語言模型的學習路線。
軟件測試開發免費影片教程分享 - 公眾號 - 測試人社區











