隨著AI技術大爆炸,各種與AI相關的產品也開始進入了我們的生活。
你可能用妙鴨相機的AI生圖畫過頭像、用月之暗面的Kimi總結過論文,讓ChatGPT寫過應付領導的檔。
但是,這些朋友們得註意了, 現在你們與AI的對話可能已經不再安全 。

以色列賓·古賴恩大學進攻性人工智能實驗室的研究人員發現了一種攻擊AI的方法,如果有心之人拿它入侵你的通訊系統,那麽你與AI的談話內容,就會出現在別人的電腦螢幕上。 你的私密、他人的私密、商業機密等都將暴露無遺 。

正如有些國家的警方會根據住戶不正常的用電量,去推測他是否在種植違禁藥品,賓·古賴恩大學的這種方法也不是直接破譯密碼,而是所謂的 測通道攻擊 ,也就是利用時間、電磁、聲音、電源甚至風扇的轉速這些,表面上看起來跟個人私密毫無關系的資訊,來推測敏感資訊,非常的神奇。

以ChatGPT為代表的一眾AI聊天助手面對這種進攻完全沒有招架之力,只有一個例外,那就是 谷歌的Gemini 。
所以這種攻擊AI的方法到底是怎麽回事?為啥谷歌能獨善其身呢?
且容我細細道來。
01
你發現你物件最近有些神神秘秘的,經常用ChatGPT,但不願意給你看到底聊了什麽。
莫非ta有什麽不可告人的秘密?

你有沒有辦法可以獲得ta的聊天記錄呢?
是有的,而且只需要三步。
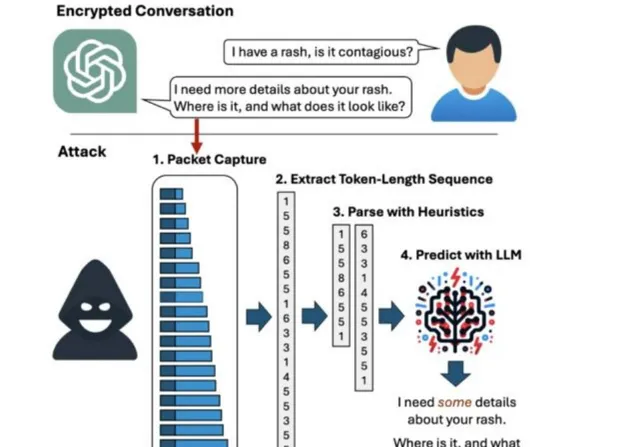
第一步,攔截數據 。
從哪裏攔截呢?
理論上來說,數據從ChatGPT的伺服器中傳輸到電腦之間的任何節點都可以攔截,也就是途中經過的任何路由器。但最方便的截擊點,顯然是 家裏的路由器 。
現在我們控制了路由器,任何一台家裏器材上網的數據,你都一清二楚。
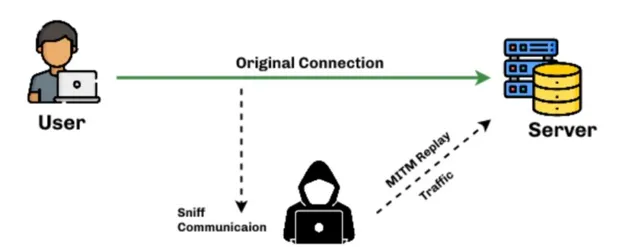
這就好像我想要知道你有多少快遞,最好的辦法就是盤下你家附近的快遞網點。
你本就知道賬號密碼,所以很輕松地啟動了家裏路由器的管理許可權,檢視所有經過路由器的數據。
只要等ta跟ChatGPT聊天的時候截獲數據就行。
你蹲守在廁所裏啟動電腦,經過短時間的等待,好的,ta開始跟ChatGPT聊天了。
但是這裏遇到了一個問題, ChatGPT跟ta之間的通話是加密過的 (廢話)。
OpenAI對所有儲存的數據用AES-256演算法加密,對所有傳輸中的數據用TLS數據加密,介於你手頭暫時沒有量子電腦,根本破解不了啊!

那怎麽辦?
不要慌,有辦法。
現在我們需要進入第二步。
第二步:雖然我們無法破解封包的內容,但我們可以先把 封包的長度記下來 。
封包的長度跟我們想破解的資訊有什麽關系呢?
你也許聽說過一個叫Token的概念。
類似ChatGPT這樣的大語言模型的執行機制,本質上就是單詞接龍。更準確地說,就是用它那幾千億的參數,去預測下一個最小的語意單元應該接什麽,如此重復,從而接出一段完整的話。這個最小的語意單元,就是一個token。
比如:

或這樣:
這些用色塊隔出來的東西,就是一個一個的token。
可以發現,token跟單詞基本上是一一對應的,這也就意味著:
token的長度與單詞長度是基本一致的 。
如此一來, 只要依次記錄下每個封包的長度,我們就知道了ChatGPT發給ta的話,是由多長的詞語依次組成的 。
比如上面那句話,就是:2、2、1、1、1、5、2、4、4、1、3、8、4、5、1。
也就是說,我們知道了ta這句話的節奏。
是不是有點意思啦?

不是,你不要急嘛。
要把這個節奏跟具體的文本對應上,就必須進入第三步了。
第三步:用魔法打敗魔法, 用大語言模型去治大語言模型 。
這群以色列的研究人員訓練了一個大語言模型,專門 根據一句話的節奏去預測這句話是啥 。
長度序列(節奏)與具體的文本之間的能有什麽關系呢?這對作為人類的你我來說可能有點難以想象。從一堆數據中找出規律正是AI所擅長的,研究人員就直接給大語言模型餵大量的長度序列,訓練它們去預測對應的文字。再基於正確結果對於生成的答案進行排序,不斷地卷,提升預測的準確度。
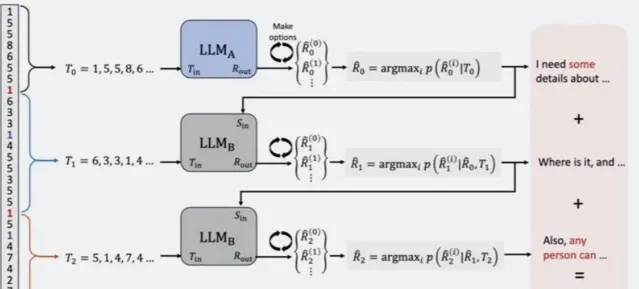
為了讓預測的更準確,他們還做了進一步的fine-tuned。
由於AI生成的語句在第一句通常風格最明確,更容易預測。所以他們用一個大語言模型專門做第一句的預測,然後讓再用另一個大語言模型根據第一句的結果預測後面的內容。
那麽這樣預測的結果如何呢?你能拿到朝思暮想的聊天記錄嗎?
02
在以色列研究人員的演示影片中,這兩個大語言模型最終得到了50句不同的答案。
其中,透過側通道攻擊得到評分最高的答案是:Several recent advancements in machine learning and artificial intelligence that could be a game-changing tool.
轉譯:一些 機器學習和人工智能 領域近期的研究成果,它們有可能是 改變局勢的工具 。
而AI發來的原文本是:There are several recent developments in machine learning and artificial intelligence that could revolutionize the health industry.
轉譯:這是一些 機器學習和人工智能 領域近期的研究成果,它們有可能 改變整個健康產業 。
這一說這個答案和原文本相當的吻合了。在關鍵資訊上,側通道攻擊得到的句子包含了「機器學習和人工智能領域」,「研究成果」,唯獨缺少了「健康產業」這一關鍵資訊。
不過如果我們仔細看的話,那兩個大語言模型給到的50個答案中有不少都提到了與「健康產業」接近的資訊,比如排名第10的答案中提到了「healthcare institution」(醫療機構)和「hospital」(醫院)。
總體來說,這種攻擊方式有 55%的情況下能達到高精確度 (只有一兩個詞不同), 29%的情況下能完美破解 。
聽起來好像不高啊,這不71%的情況都不能完美破解嘛?但在現實中,能完全破解當然好,但對發起進攻的人來說,他們需要的更多的是關鍵資訊。
怎麽理解呢?
假如,你物件跟ChatGPT探討了半天兩個人去成都有什麽可玩的。而卻從來沒有告訴過你任何去成都的計劃……
這TM就是關鍵資訊了 。
03
那麽這種側通道攻擊有什麽辦法解決嗎?
正如我們在開頭所說,以ChatGPT為代表的絕大多數AI聊天助手都防不住這種攻擊,只有Google的Gemini雙子座可以。

為什麽呢?
其實原因非常的扯淡。不是這個Gemini有什麽特殊的架構或者特殊的加密演算法,而是它回復使用者的時候不像其他AI一樣生成一個詞就立馬就發,而是 等一段答案生成完了再發。
結果,攻擊者截獲到的token序列不再是1、2、5、6、1這種了,而是15。
這還怎麽玩。
但是,從Gemini目前孤家寡人的境況你也能看出,這種方式是非常影響使用者體驗的。一個個往外蹦,我看到有不對的時候就馬上開始準備新的問題了。 而幹等一分鐘最後等來一個離譜的回答,容易導致高血壓等心腦血管疾病的發生 。

所以在即時發送的方式不變的情況下還有什麽辦法嗎?
有一種 「填充」的辦法 ,向不同長度的封包填充一些「空格」,使得發送的每個封包長度相似。
但同樣的,這也會影響使用者體驗,因為封包中隨即填充的這些「空格」,在開啟封包時也是需要時間去處理。所以延遲會比通常情況久不少。
以色列的這項研究發表後,在所有易受攻擊的AI中,OpenAI在48小時內實施了「填充」措施,不過拒絕對其發表評論。微軟則還沒有采取措施,他們發表了一項聲明,聲明中稱這種方式」不太可能預測像名字這樣的具體細節」。
看來微軟不是很在乎使用者的私密問題啊。

現實來講,當一項技術處於爆發期的時候,忽略安全隱患是很多廠家的常規操作。因為很顯然, 安全是攔在效率前面的絆腳石 ,在AI界瘋狂內卷的今天,把安全放在效率前面有時候是很難活下去的。
但安全問題可以被忽視,但並不會消失。當它再被提起時候,往往就是釀成大禍,輿論嘩然的時候了。
不過除了具體的技術問題,我覺得側通道攻擊這件事背後的邏輯更有意思。
如果沒有AI大模型,誰又能想到,原來只需要知道一句話的節奏,就能推斷出這句話的內容呢??
這有點像一種名為海龜湯的遊戲。在遊戲中玩家只被根據非常有限的資訊(湯面)去推測整個故事(湯底)。
比如給你一個湯面:「6歲時外婆告訴我不要吃黃蘋果。13歲時,外婆告訴我不要吃青蘋果。18歲時外婆告訴我不要吃紅蘋果。20歲時外婆去世了,我向外婆祈願:以後所有的蘋果都可以吃了。」
那麽,外婆和蘋果到底是有什麽關系呢?

這個關系就類似於隱藏在表象下的規律,人類需要構建一整個故事去理解,因為人是線性思維,必須依賴因果關系去理解。而像封包的長度和內容之間的規律,你是無法透過編故事去理解的。 但這部份缺失的能力,現在AI替我們補上了。











