人工智能(AI)涉及到多個學科和領域,如電腦科學、數學、統計、心理學、生物學等。AI的目標是讓機器能夠模擬和超越人類的智能,包括感知、推理、學習、決策等能力。在AI的發展過程中,深度學習(DL)和貝葉斯方法(BM)是兩種重要的技術,它們各自具有獨特的優勢和套用場景。
深度學習是一種基於神經網絡的機器學習方法,它可以利用大量的數據和強大的計算能力,自動地學習數據的復雜特征和規律,從而實作高效的預測和分類。深度學習在影像辨識、自然語言處理、語音辨識、電腦視覺等領域取得了顯著的成果,推動了AI的快速發展。然而,深度學習也面臨著一些挑戰和局限,如數據量和質素的依賴、模型的復雜度和不透明性、不確定性的處理和量化等。
貝葉斯方法是一種基於概率模型的推理方法,它可以利用貝葉斯定理,結合先驗知識和觀測數據,推斷出後驗分布,從而實作不確定性的建模和量化。貝葉斯方法在統計學、機器學習、資料探勘等領域有著廣泛的套用,它可以處理數據稀疏、雜訊、缺失等問題,提高模型的魯棒性和可解釋性。然而,貝葉斯方法也存在著一些困難和限制,如模型的選擇和設計、後驗分布的計算和近似、超參數的設定和調整等。
為了克服深度學習和貝葉斯方法各自的缺點,同時發揮它們的優勢,一種自然的想法是將它們結合起來,形成貝葉斯深度學習(BDL)。BDL是一種將深度神經網絡和概率模型相結合的方法,它可以實作對數據和模型的不確定性的建模和量化,從而提高模型的效能和可信度。BDL在近年來受到了越來越多的關註和研究,它在推薦系統、話題模型、控制系統等領域有著廣泛的套用和潛力。
本文旨在介紹和分析一篇關於BDL的最新論文:【Position Paper: Bayesian Deep Learning in the Age of Large-Scale AI】。該論文由來自美國、英國、德國、加拿大等國家的Theodore Papamarkou、Maria Skoularidou、Konstantina Palla、Laurence Aitchison 、Julyan Arbel 等十幾位知名學者合作撰寫。該論文從不同的角度闡述了BDL的重要性和必要性,提出了BDL的一般框架和具體模型,展示了BDL在不同領域的套用和效果,總結了BDL的挑戰和未來的研究方向。該論文是一篇具有創新性和前瞻性的綜述性文章,為BDL的發展提供了有價值的參考和啟示。
背景和動機
人工智能的發展經歷了多個階段,從早期的符號主義,到後來的連線主義,再到現在的統計主義。在這些階段中,深度學習和貝葉斯方法都扮演了重要的角色,但也有著不同的側重點和局限性。
深度學習是一種基於神經網絡的機器學習方法,它可以利用大量的數據和強大的計算能力,自動地學習數據的復雜特征和規律,從而實作高效的預測和分類。深度學習在影像辨識、自然語言處理、語音辨識、電腦視覺等領域取得了顯著的成果,推動了AI的快速發展。
深度學習也面臨著一些挑戰和局限,比如:
數據量和質素的依賴。深度學習模型通常需要大量的標註數據來進行訓練,而這些數據往往是昂貴和耗時的,或者是不完整和有雜訊的。當數據量不足或質素不高時,深度學習模型的效能會下降,甚至出現過擬合或欠擬合的問題。
模型的復雜度和不透明性。深度學習模型通常具有很高的復雜度和參數量,這使得模型的訓練和偵錯變得困難和耗時。同時,深度學習模型的內部機制和邏輯往往是不清楚和不可解釋的,這使得模型的可信度和可靠性受到質疑,也給模型的部署和套用帶來了風險和障礙。
不確定性的處理和量化。深度學習模型通常只給出一個確定的輸出,而沒有給出輸出的不確定性或置信度。這使得模型在面對新的或異常的數據時,無法有效地處理和量化不確定性,也無法給出合理的風險評估和決策建議。例如,在醫療診斷或自動駕駛等領域,不確定性的處理和量化是非常重要和必要的,因為模型的錯誤或不確定的輸出可能會導致嚴重的後果和損失。
貝葉斯方法是一種基於概率模型的推理方法,它可以利用貝葉斯定理,結合先驗知識和數據,更新對參數或假設的信念。貝葉斯方法的優點是可以處理不確定性和缺失數據,提供完整的後驗分布,而不僅僅是點估計或區間估計。它利用先驗知識,增加模型的可解釋性和可信度,也可以進行模型比較和選擇。可以適應復雜和非線性的數據結構,使用靈活和多樣的概率模型,如貝葉斯網絡、高斯過程、深度生成模型等。可以實作線上和增量學習,動態地更新後驗分布,適應數據的變化。
貝葉斯方法的缺點是需要指定合適的先驗分布,這可能需要一定的領域知識和經驗,也可能引入主觀偏見。它需要計算復雜和高維的後驗分布,這通常需要使用近似方法,如變分推斷、馬可夫鏈蒙特卡羅(MCMC)方法等,這些方法可能需要較多的時間和資源,也可能存在收斂和穩定性的問題。它需要評估和利用後驗分布的不確定性,這可能需要一定的統計技巧和理解,也可能影響決策和最佳化的效果。
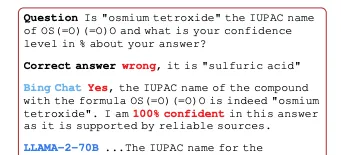
圖1:流行的LLM聊天助手,如Bing chat(使用GPT-4)和LLAMA-2-70B,經常以非常高的置信度產生錯誤的答案,表明他們的置信度沒有經過校準。BDL傳統上被用來克服這種過度自信問題,但在LLM時代,BDL沒有得到充分利用。請註意,OS(=O)(=O)O是眾所周知的分子pSO4的文本表示,可以很容易地在維基百科上尋找。強調和省略是我們的。存取日期:2024-01-23。
貝葉斯深度學習(BDL)是一種將深度學習和貝葉斯方法相結合的方法,它旨在實作對數據和模型的不確定性的建模和量化,從而提高模型的效能和可信度。BDL的基本思想是將深度神經網絡的權重和偏置視為隨機變量,而不是固定的參數,從而使模型的輸出也成為一個隨機變量,它的分布取決於權重和偏置的分布。為了描述權重和偏置的分布,我們需要定義一個先驗分布和一個似然函數。先驗分布是對權重和偏置的初始信念,它可以是一個簡單的分布,如高斯分布,或者是一個復雜的分布,如深度生成模型。似然函數是對數據的觀測模型,它描述了給定權重和偏置時,數據的生成過程。似然函數通常是一個條件概率分布,如多項式分布或高斯分布。BDL的目標是根據觀測到的數據,更新對權重和偏置的信念,得到一個後驗分布。後驗分布是根據貝葉斯定理計算的,它反映了數據對先驗分布的影響。後驗分布可以用來預測新的數據,以及量化預測的不確定性。然而,後驗分布通常是無法直接計算的,因為它涉及到一個高維的積分或求和,這在深度神經網絡中是非常困難的。因此,我們需要使用一些近似方法,如變分推斷、馬可夫鏈蒙特卡羅(MCMC)方法、拉普拉斯近似等,來得到後驗分布的近似解。
BDL的研究意義和目的是為了解決深度學習中的不確定性問題,提高模型的效能和可信度。BDL的研究動機是為了利用深度學習和貝葉斯方法的互補優勢,實作對數據和模型的不確定性的建模和量化。BDL的研究內容是為了提出一些有效的模型、演算法、框架和套用,展示BDL的理論和實踐方面的進展和貢獻。BDL的研究方法是為了結合深度神經網絡和概率模型,進行後驗分布的推斷和近似,以及不確定性的評估和利用。BDL的研究難點是為了處理高維的後驗分布的計算和近似,以及不確定性的建模和量化。BDL的研究前景是為了在不同的領域和場景中發揮作用,解決實際的問題和挑戰,展示BDL的優勢和效果。
主要內容
論文的主要內容分為三個部份,分別是:
BDL的一般框架。這一部份介紹了BDL的基本原理和方法,包括如何將深度神經網絡和概率模型相結合,如何進行後驗分布的推斷和近似,以及如何評估和利用不確定性。
BDL的具體模型。這一部份介紹了BDL的幾種典型的模型,包括貝葉斯神經網絡(BNN)、貝葉斯摺積神經網絡(BCNN)、貝葉斯迴圈神經網絡(BRNN)、貝葉斯變分自編碼器(BVAE)、貝葉斯生成對抗網絡(BGAN)、貝葉斯元學習(BML)等。這些模型分別適用於不同的數據類別和任務,如影像、文本、序列、生成、對抗、元學習等。
BDL的套用和效果。這一部份介紹了BDL在不同領域的套用和效果,包括推薦系統、話題模型、控制系統等。這些領域都涉及到不確定性的建模和量化,以及基於不確定性的決策和最佳化。論文展示了BDL相比於傳統的深度學習和貝葉斯方法,在這些領域的優勢和改進,如提高了預測的準確性和魯棒性,降低了數據的需求和成本,增加了模型的可解釋性和可信度等。
下面我們將分別對這三個部份進行更詳細的解讀和分析。
1、BDL的一般框架
BDL的一般框架是將深度神經網絡和概率模型相結合,從而實作對數據和模型的不確定性的建模和量化。具體來說,BDL的一般框架包括以下幾個步驟:
1)定義模型。BDL的模型是一個深度神經網絡,它的權重和偏置被視為隨機變量,而不是固定的參數。這意味著模型的輸出也是一個隨機變量,它的分布取決於權重和偏置的分布。為了描述權重和偏置的分布,我們需要定義一個先驗分布和一個似然函數。先驗分布是對權重和偏置的初始信念,它可以是一個簡單的分布,如高斯分布,或者是一個復雜的分布,如深度生成模型。似然函數是對數據的觀測模型,它描述了給定權重和偏置時,數據的生成過程。似然函數通常是一個條件概率分布,如多項式分布或高斯分布。
2)推斷後驗分布。BDL的目標是根據觀測到的數據,更新對權重和偏置的信念,得到一個後驗分布。後驗分布是根據貝葉斯定理計算的,它反映了數據對先驗分布的影響。後驗分布可以用來預測新的數據,以及量化預測的不確定性。然而,後驗分布通常是無法直接計算的,因為它涉及到一個高維的積分或求和,這在深度神經網絡中是非常困難的。因此,我們需要使用一些近似方法,如變分推斷、馬可夫鏈蒙特卡羅(MCMC)方法、拉普拉斯近似等,來得到後驗分布的近似解。
3)評估和利用不確定性。BDL的優勢是它可以提供對數據和模型的不確定性的評估和利用。不確定性可以分為兩種類別:模型不確定性和數據不確定性。模型不確定性是指對權重和偏置的不確定性,它反映了模型的復雜度和靈活性。數據不確定性是指對輸出的不確定性,它反映了數據的雜訊和稀疏性。BDL可以透過後驗分布的變異數或熵來量化不確定性,也可以透過後驗預測分布的置信區間或可靠性曲線來量化不確定性。BDL可以利用不確定性來進行更好的決策和最佳化,例如,可以根據不確定性來選擇最優的行動或參數,或者根據不確定性來分配更多的資源或註意力。
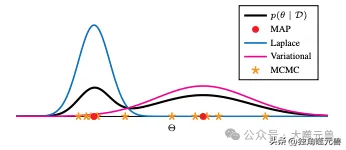
圖2:近似參數空間θ上的後驗p(θ|D)的BDL方法的不同風格。雖然基於拉普拉斯和高斯的變分方法都產生高斯近似,但它們通常捕獲後驗的不同局部模式。集合方法使用MAP估計作為樣本。
2、BDL的具體模型
BDL的具體模型是指將深度神經網絡和概率模型相結合的一些典型的模型,它們分別適用於不同的數據類別和任務,如影像、文本、序列、生成、對抗、元學習等。論文介紹了以下幾種BDL的具體模型:
貝葉斯神經網絡(BNN)。BNN是一種將神經網絡的權重和偏置視為隨機變量的模型,它可以用來進行回歸或分類等任務。BNN的優點是它可以量化模型的不確定性,提高模型的魯棒性和泛化能力,減少模型的過擬合或欠擬合。BNN的挑戰是它需要對高維的後驗分布進行推斷和近似,這通常是非常困難和耗時的。BNN的常用的推斷和近似方法有變分推斷、MCMC方法、拉普拉斯近似等。
貝葉斯摺積神經網絡(BCNN)。BCNN是一種將摺積神經網絡的權重和偏置視為隨機變量的模型,它可以用來處理影像等高維的數據。BCNN的優點是它可以利用摺積層的局部性和共享性,降低模型的參數量和計算量,提高模型的效率和穩定性。BCNN的挑戰是它需要對摺積層的後驗分布進行推斷和近似,這通常需要一些特殊的技巧和假設,如摺積分解、貝葉斯壓縮等。
貝葉斯迴圈神經網絡(BRNN)。BRNN是一種將迴圈神經網絡的權重和偏置視為隨機變量的模型,它可以用來處理序列等動態的數據。BRNN的優點是它可以利用迴圈層的記憶和反饋,捕捉數據的時序和上下文資訊,提高模型的表達能力和預測能力。BRNN的挑戰是它需要對迴圈層的後驗分布進行推斷和近似,這通常需要一些復雜的方法和結構,如變分迴圈單元、貝葉斯註意力機制等。
貝葉斯變分自編碼器(BVAE)。BVAE是一種將變分自編碼器的權重和偏置視為隨機變量的模型,它可以用來進行生成等任務。BVAE的優點是它可以利用變分自編碼器的編碼和解碼結構,學習數據的潛在表示和生成分布,提高模型的靈活性和多樣性。BVAE的挑戰是它需要對變分自編碼器的後驗分布進行推斷和近似,這通常需要一些精細的設計和最佳化,如重參數化技巧、正則化項、重構損失等。
貝葉斯生成對抗網絡(BGAN)。BGAN是一種將生成對抗網絡的權重和偏置視為隨機變量的模型,它也可以用來進行生成等任務。BGAN的優點是它可以利用生成對抗網絡的生成器和判別器結構,學習數據的真實分布和對抗分布,提高模型的逼真度和魯棒度。BGAN的挑戰是它需要對生成對抗網絡的後驗分布進行推斷和近似,這通常需要一些難度和不穩定性,如拿殊均衡、模式崩潰、梯度消失等。
貝葉斯元學習(BML)。BML是一種將元學習的權重和偏置視為隨機變量的模型,它可以用來進行元學習等任務。BML的優點是它可以利用元學習的元參數和子參數結構,學習不同任務之間的共性和差異,提高模型的快速適應能力和泛化能力。BML的挑戰是它需要對元學習的後驗分布進行推斷和近似,這通常需要一些高效和靈活的方法和演算法,如貝葉斯最佳化、貝葉斯神經網絡、貝葉斯元最佳化等。
3、BDL在不同領域的套用和效果
BDL在不同領域的套用和效果是指BDL如何在實際的問題和場景中發揮作用,以及BDL相比於傳統的深度學習和貝葉斯方法,在這些領域的優勢和改進。
論文介紹了以下幾個領域的套用和效果:
推薦系統。推薦系統是一種根據使用者的偏好和行為,向使用者提供個人化的產品或服務的系統,它在電子商務、社交媒體、資訊檢索等領域有著廣泛的套用。推薦系統的核心問題是如何預測使用者對專案的評分或反饋,以及如何根據預測的評分或反饋來生成推薦列表。推薦系統面臨著一些挑戰,如數據的稀疏性、冷啟動問題、使用者和專案的動態變化等。BDL可以在推薦系統中發揮作用,例如,可以使用BNN或BCNN來預測使用者對專案的評分或反饋,同時量化預測的不確定性,從而提高預測的準確性和魯棒性,也可以使用BVAE或BGAN來生成新的專案或使用者,從而解決冷啟動問題,也可以使用BRNN或BML來捕捉使用者和專案的時序和上下文資訊,從而適應使用者和專案的動態變化。
話題模型。話題模型是一種用來發現文本數據中隱含的主題或話題的模型,它在文本分析、資訊檢索、自然語言處理等領域有著重要的套用。話題模型的核心問題是如何從文本數據中提取出有意義的話題,以及如何將文本數據分配到不同的話題中。話題模型面臨著一些挑戰,如話題的選擇和設計、文本的復雜性和多樣性、話題的動態演化等。BDL可以在話題模型中發揮作用,例如,可以使用BVAE或BGAN來學習文本數據的潛在表示和生成分布,從而提高話題的靈活性和多樣性,也可以使用BRNN或BML來捕捉文本數據的時序和上下文資訊,從而適應話題的動態演化。
控制系統。控制系統是一種用來控制物理或虛擬的系統的狀態或行為的系統,它在機器人、自動駕駛、智能電網等領域有著重要的套用。控制系統的核心問題是如何根據系統的當前狀態和目標狀態,選擇最優的控制策略或行動,以及如何根據系統的反饋或獎勵,更新控制策略或行動。控制系統面臨著一些挑戰,如系統的復雜性和不確定性、控制策略或行動的選擇和評估、系統的安全性和穩定性等。BDL可以在控制系統中發揮作用,例如,可以使用BNN或BCNN來預測系統的狀態或行為,同時量化預測的不確定性,從而提高預測的準確性和魯棒性,也可以使用BVAE或BGAN來生成新的系統或環境,從而解決探索和利用的平衡問題,也可以使用BRNN或BML來捕捉系統的時序和上下文資訊,從而適應系統的動態變化。
創新點和優勢
論文的創新點和優勢是指論文如何在BDL的理論和實踐方面,提出了一些新的觀點和方法,以及BDL相比於傳統的深度學習和貝葉斯方法,在不同方面的優勢和改進。
作者提出了BDL的一般框架,包括如何將深度神經網絡和概率模型相結合,如何進行後驗分布的推斷和近似,以及如何評估和利用不確定性。論文也介紹了BDL的幾種典型的模型,包括BNN、BCNN、BRNN、BVAE、BGAN、BML等。這些模型分別適用於不同的數據類別和任務,如影像、文本、序列、生成、對抗、元學習等。論文的這些內容為BDL的發展提供了一個清晰和完整的概述和指導,也為BDL的研究和套用提供了一些有用的參考和範例。
他們展示BDL在不同領域的套用和效果,包括推薦系統、話題模型、控制系統等。這些領域都涉及到不確定性的建模和量化,以及基於不確定性的決策和最佳化。論文展示了BDL相比於傳統的深度學習和貝葉斯方法,在這些領域的優勢和改進,如提高了預測的準確性和魯棒性,降低了數據的需求和成本,增加了模型的可解釋性和可信度等。論文的這些內容為BDL的套用和效果提供了一些有力的證據和支持,也為BDL的推廣和普及提供了一些有益的案例和經驗。
論文總結了BDL目前面臨的一些挑戰和限制,以及未來的一些研究方向和展望。這些挑戰和限制包括模型的選擇和設計、後驗分布的計算和近似、超參數的設定和調整、可延伸性和效率、安全性和倫理等。這些研究方向和展望包括混合貝葉斯方法、深度核過程和機器、半監督和自監督學習、混合精度和張量計算、壓縮策略、貝葉斯遷移和持續學習、概率數值、奇異學習理論、符合預測、LLM作為分布、元模型等。論文的這些內容為BDL的進步和創新提供了一些有價值的思路和方向,也為BDL的未來的發展提供了一些有意義的期待和願景。
參考資料:https://browse.arxiv.org/pdf/2402.00809.pdf

噬元獸(FlerkenS)是一個去中心化的個人AI數碼價值容器,同時也是數碼經濟的新型資產捕捉器和轉化器,用數據飛輪為使用者提供無邊界的數碼化、智能化和資產化服務。
噬元獸(FlerkenS)構建AI市場、AI釋出器和一個在通用人工智能(AGI)上建設可延伸的系統,AI-DSL讓不同類別和領域的AI套用和服務可以相互協作和互動,透過RAG向量數據庫(Personal Vector Database)+ Langchain技術方案(Langchain Technology Solution)+大模型的技術實作路徑,讓使用者獲得個人化的AI服務,在分布式的網絡環境裏與AI技術下的服務商實作點到點的連線,建設一個智能體和經濟體結合的數智化整體。
波動世界(PoppleWorld)是噬元獸平台的一款AI套用,采用AI技術幫助使用者進行情緒管理的工具和傳遞情緒價值的社交產品,采用Web3分布式技術建設一套采集使用者情緒數據並透過TOKEN激勵聚合形成情感垂直領域的RAG向量數據庫,並以此訓練一個專門解決使用者情緒管理的大模型,結合Agents技術形成情感類AI智慧體。在產品裏植入協助使用者之間深度互動提供情緒價值的社交元素,根據使用者的更深層化的需求處理準確洞察匹配需求,幫助使用者做有信心的購買決定並提供基於意識源頭的商品和服務,建立一個指導我們的情緒和反應的價值體系。這是一款針對普通人的基於人類認知和行為模式的情感管理Dapp應用程式。











