
「
如果把AI 大模型比作汽車,原始數據就是原油。
」
作者 | 江江
編輯|蔓蔓周
ChatGPT 的出現和 Midjourney 的爆發式采用讓 AI 實作了第一次大規模套用,即大模型的普及。
所謂大模型,是指具有大量參數和復雜結構的機器學習模型,能夠處理海量數據、完成各種復雜的任務。
01
AI數據版權糾紛
如果把當下的 AI 大模型比作汽車,原始數據就是原油。無論如何,首先 AI 模型需要足夠的「原油」。
AI 公司的「原油」來源主要有以下幾類:
●網上公開免費的資料來源,比如維基百科、網誌、論壇、新聞資訊等;
●老牌新聞媒體和出版社;
●大學等研究機構;
●使用模型的 C 端使用者。
現實世界的石油歸屬權已經有成熟的法律規範,而在 AI 這個天地尚且混沌的領域,「原油」開采權還不明晰,由此造成的糾紛不勝列舉。
就在最近,多家大型音樂廠牌起訴AI音樂制作公司 Suno 和 Udio ,指控其侵犯版權。這起訴訟與【紐約時報】去年12月對OpenAI的訴訟類似。

圖源:Billboard
2023年7月,一些作家對該公司提起訴訟,指控ChatGPT根據受版權保護的內容生成了作者作品的摘要。
同年12月,【紐約時報】也對
微軟
和
OpenAI
提起類似版權侵權訴訟,指控這兩家公司利用該報的內容訓練人工智能聊天機器人。
此外,還有一起集體訴訟在加利福尼亞州提起,指控OpenAI未經使用者同意,從互聯網上獲取使用者私人資訊來訓練ChatGPT。
OpenAI 最終並沒有為這份指控買單,他們表示不認同【紐約時報】的指控,也無法復現【紐約時報】提到的問題,更重要的是,所謂【紐約時報】提供的資料來源,對於 OpenAI 來說並不重要。

來源:https://openai.com/index/openai-and-journalism/
對於 OpenAI 來說,這件事情帶來的最大教訓也許就是處理好與數據供應商的關系,明確雙方權責。於是,我們在近一年的時間內看到 OpenAI 跟很多數據供應商達成合作夥伴關系,包括但不僅限於The Atlantic、Vox Media、News Corp、Reddit、Financial Times、Le Monde、Prisa Media、Axel Springer、American Journalism Project 等等。
未來,OpenAI 將名正言順地使用這些媒體的數據,而這些媒體也會將 OpenAI 的技術融合到產品中。
02
AI 推動內容平台變現
不過,OpenAI 跟數據供應商達成合作關系最根本的原因不是恐懼被起訴,而是機器學習即將面臨的數據枯竭。MIT等研究人員曾進行一項研究估計,機器學習數據集可能會在 2026 年之前耗盡所有「高質素語言數據」。
「高質素的數據」因此成為像 OpenAI 和 Google 這樣的模型制造商的香餑餑。內容公司與AI模型廠商屢屢達成合作,開啟躺平賺錢模式。
傳統媒體平台Shutterstock陸續和Meta, Alphabet, Amazon, Apple, OpenAI, Reka等AI公司達成合作, 2023年透過內容授權給AI模型將年收入提高到 1.04 億美元,預計 2027 年產生 2.5 億美元收入;Reddit 授權給谷歌的內容版權收入每年高達 6000 萬美元;蘋果也在尋求與主流新聞媒體合作,開出一年至少5000萬美元的版權費。內容公司從 AI 公司收到的版權費正在以 450% 的年增長率瘋狂上漲著。

圖源:CX Scoop
而在過去一些年裏,串流媒體之外的內容難以變現,這是內容行業的一大痛點。相比互聯網創業時代,AI 的出現給內容行業帶來了更大的想象力以及更強烈的收入預期。
03
高質素數據依然稀缺
當然不是什麽樣的內容都符合 AI 的需求。
關於前文提到的 OpenAI 和【紐約時報】的爭論,另一個亮點是數據質素。從原油中提煉石油,一則是要油本身質素好,二則提純技術要好。
OpenAI 特意強調【紐約時報】的內容並未對 OpenAI 的模型訓練產生任何重大貢獻,比起能夠讓 OpenAI 每年自掏腰包數千萬美金的 Shutterstock,【紐約時報】這類靠時效性起家的文字媒體並不是 AI 時代的寵兒。AI 更需要深刻而獨特的數據。
而高質素數據太稀缺,AI 公司也開始在「提純技術」和「一站式套用」上下功夫。
6 月 25 日,OpenAI 收購實時分析數據庫公司 Rockset。這家公司主要提供即時數據索引和查詢功能,OpenAI將在其產品中整合 Rockset 的技術,提高數據的即時使用價值。

圖源:DePIN Scan
透過收購Rockset,OpenAI 計劃使 AI 更好地利用和存取即時數據。這能使 OpenAI 的產品支持更復雜的套用,如即時推薦系統、動態數據驅動的聊天機器人、即時監控和報警系統等。
Rocket是 OpenAI 內建的「石化部門」,將普通數據直接轉化為套用所需的高質素數據。
04
創作者數據確權是異想天開嗎?
互聯網媒體平台(Facebook、Reddit 等)的數據很大程度來自於UGC,即使用者貢獻內容。很多平台在向 AI 公司收取高額數據費的同時,也悄悄在使用者條款上加上了一條「平台擁有使用使用者數據訓練 AI 模型的權力」。
雖然使用者條款對 AI 模型訓練權力有所標註,但創很多作者並不清楚自己生產的內容具體被哪些模型使用,也不知道是否是付費使用,更無從獲得本該屬於自己的相關權益。
在今年 2 月份的 Meta 季度業績電話會議上,朱克伯格明確表示將使用 Facebook 和 Instagram 上的圖片來訓練他的 AI 生成工具。
據報道,Tumblr 也已經與 OpenAi 和 Midjourney 神秘達成內容授權協定,但並未公開具體協定的具體的內容。
圖片庫平台EyeEm的創作者們最近也收到一份通知,提示他們釋出過的照片會用於 AI 模型訓練。通知提到,使用者可以選擇因此不使用產品,但還未提及任何補償政策。EyeEm 的母公司 Freepik 向路透社透露,該公司已與兩家大型科技公司簽署協定,以每張圖片 3 美分左右的價格授權其 2 億張圖片中的大部份圖片。行政總裁 Joaquin Cuenca Abela 表示,還有五筆類似的交易正在進行中,但拒絕透露買家的身份。
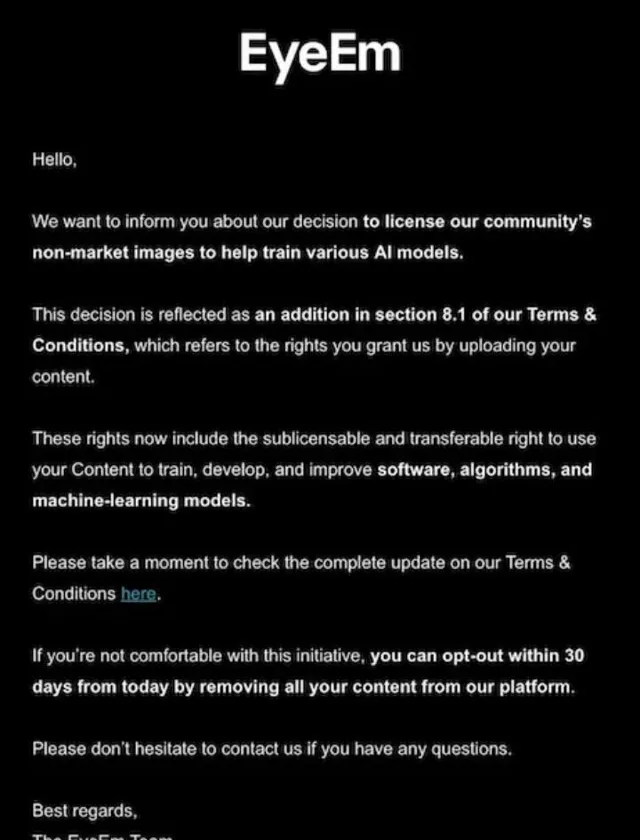
Getty Images、Adobe、Photobucket、Flickr、Reddit 等UGC 為主導的內容平台都面臨類似的問題,在巨大的數據變現誘惑下,平台選擇忽視使用者的內容所有權,一把將數據打包賣給 AI 模型公司。
整個過程都在暗處進行,創作者並沒有任何反抗的機會。甚至許多創作者,可能要在未來某一天,在某個模型中訓練出與自己作品類似的內容時,才能有機會懷疑曾經的作品被某個平台拿去賣給 AI 公司做模型訓練。
解決創作者的數據確權和收益難以保護的問題,Web3 可能是個好選擇。當 AI 公司在美股屢創新高時,web3 的 AI 概念幣也在同時一飛沖天。區塊鏈以其去中心化和不可篡改的特性,在保護創作者權益上享有得天獨厚的優勢。
諸如圖片和影片這樣的媒體內容已經在 2021 年的牛市完成了上鏈的大規模采用,而社交平台的 UGC 內容上鏈也在悄然發生。同時,許多 web3 AI 模型平台已經在激勵為模型訓練做貢獻的普通使用者,無論是數據所有者,還是訓練者,都被激勵著。
AI 模型指數級的發展為數據確權提出了更大的需求,創作者應該思考:為什麽我的作品在沒有經過我同意的情況下被 5 美分一幅賣給了 AI 模型公司?為什麽整個過程中我不知情,且無法得到任何收益?
媒體平台竭澤而漁也無法緩解 AI 模型公司的數據焦慮,實作高質素數據高產量的前提是數據確權,是創作者、平台和 AI 模型公司三者合理的利益分配。
參考來源:
Shutterstock Made $104 Million Licensing Assets to AI Devs Last Year(PetaPixel)
All The Photo Companies That Have Struck Licensing Deals With AI Firms (PetaPixel)
Reddit has a new AI training deal to sell user content(TheEverge)
GPT-4耗盡全宇宙數據!OpenAI接連吃官司,竟因數據太缺了,UC柏克萊教授發出警告(新智元)
OpenAI acquires Rockset(OpenAI)











