北大陳寶權教授:從圖形計算到世界模型

近日,北京大學的陳寶權教授在第九屆電腦圖形學與混合現實研討會(GAMES 2024)上,發表了主題演講【從圖形計算到世界模型】,分享了他在圖形仿真與世界模型關系上的獨特見解。文章將整理陳教授的報告,期待啟發大家的思考與討論。當今,世界模型成為炙手可熱的話題,本次演講以「圖形計算到世界模型」為出發點,探討二者可能形成的深厚聯系。借助GAMES這一平台,陳教授希望大家能夠大膽分享觀點,啟發更深入的交流。

隨著近年來AIGC領域的迅猛發展,大型模型備受矚目。尤其是透過簡單的文字輸入,模型能夠生成連貫且邏輯性強的場景。這引發了一個自然的思考:這些模型是否背後隱藏著某種世界模型?這個問題的核心直接關系到AI技術的根本,在這個領域內,行業內正展開對模型機制與能力的深入探討。筆者特意在Google上尋找「Sora是否具有世界模型」,結果顯示,Sora確實展現了模擬真實世界的能力,這一發現與在場的Jiwen老師的相關研究不謀而合。該研究探討了多種生成模型,指出Sora等模型的視覺元素與世界模型特性之間的聯系。
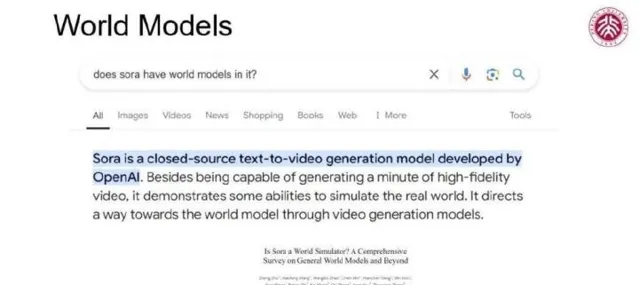
那麽,世界模型究竟是什麽?如今,學界與業界對其並沒有達成嚴格的定義。回顧歷史,LSTM的開創者Schmidhuber及其學生在論文中探討了這一概念,強調其在預測與規劃決策的核心地位。換句話說,具備透過當前資訊預測未來狀態並進行相應決策能力的模型,那便可視為擁有世界模型特征。這一觀點雖然並未提供細致的結構性描述,卻為理解世界模型提供了實用視角。

在人工智能領域的重要人物Yann LeCun也嚴格分析了世界模型的概念,盡管他並沒有給出明確的定義,主要能力如預測、推理、決策及規劃等,與我們目前所討論的內容完全一致。值得註意的是,LeCun的觀點甚至將世界模型的功能與人類大腦的運作進行了類比。GPT-4o的回答也給出了類似的描述:世界模型是一種具備模擬、預測、規劃和決策能力的系統。這種系統透過對大量數據的學習、理解,構建現實世界的內部模型,從而模擬不同情境下的結果,並制定最佳決策。

透過簡明的示意圖,我們能直觀理解世界模型。真實場景作為輸入,經由具有分析、評估及模擬能力的世界模型,最終實作符合實際情況的未來預測與決策推理。這一模型展現了人工智能技術處理復雜資訊的能力,讓我們看到它在多種套用中的潛力。如今,各大型AI模型已在復雜場景中展現優異效能,尤其是在無人駕駛領域,有著顯著的進展。
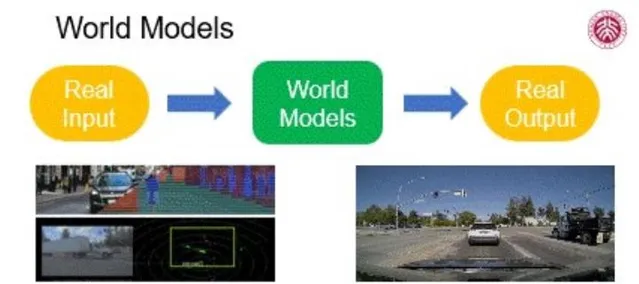
在無人駕駛技術中,高度真實的仿真系統能夠模擬多種傳感器,如激光雷達、網絡攝影機、聲音傳感器等,生成豐富的多模態數據,借此構建龐大的訓練數據集。後續,該模型能夠在全新的場景中精確感知環境,完成動態預測和判斷決策。比如,有些專案如nuScenes超越了傳統的KITTI數據集,為模型提供了更全面的學習資料。此外,輝達等科技巨頭在無人駕駛的仿真方面投入了巨資,加速了相關技術的發展和套用。總體看來,人工智能技術已經實作了從真實場景輸入到適應輸出的完整鏈條,表明其正在朝著成熟的方向發展,實際套用也將迅速推廣。

接下來的討論將圍繞如何構建更完整的世界模型展開。盡管如今在語言與影片等大模型展現出強大能力,這一切僅是構建世界模型征途的起點。大模型由海量數據「餵養」,取得顯著成效,但我們所能產生的數據遠未觸及邊界,可能的訓練方式也仍有許多。我將從幾個核心維度討論:數據豐富性、訓練模式、增強的監督機制,以及這些要素的有機融合,推動世界模型的構建。

simulation在這一過程中扮演著關鍵角色。圖形計算的獨特目標便是模擬現實世界,因此我將其視作simulation。在模擬真實世界方面,透過simulation來訓練模型、加速其叠代、驗證等展現出巨大價值。我們應首先觀察現有大模型訓練中的基本原則與局限性。在這個過程中,一個顯著的觀察是數據量與模型損失之間的關系。盡管常以線性方式描述,實際聯系更接近於對數關系,這意味著模型對數據的需求呈指數增長。隨著訓練深入,數據需求迅猛增加,數據資源亦在迅速枯竭,尤其是在涉及更高維度的數據處理時。二維領域的數據需求龐大,如德國的LAION專案展現的5TB數據量,盡管衍生版本經清理釋出,但數據量依然可觀,然而在三維數據領域卻相對匱乏。

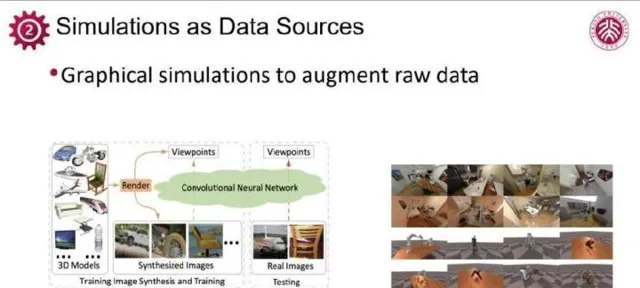
這一點正展示出三維數據的極度稀缺,成為當前人工智能與電腦視覺研究的挑戰。因此,simulation的價值愈加突出。鑒於數據的有限性,如何系統性地生成更多的高質素、有標簽數據成為關鍵,而simulation恰好滿足這一需求。如今,電腦圖形技術已經遠不止特效制作和影像編輯,它的力量在於構建simulation系統,生成海量數據,擴充套件數據集規模,為大模型訓練提供了重要支持。

許多關於數據生成的初步探索已經取得了成功,如UCSD蘇昊團隊早期在影像姿態估計任務上的研究。他們基於帶有pose標註的影像進行摺積神經網絡的訓練。由於現實世界影像中pose標註數量有限,不足以訓練出有效的模型,蘇昊團隊利用ShapeNet等三維數據集,經過3D渲染生成了大量帶有姿態資訊的影像數據,顯著豐富了訓練樣本。這種生成數據的方法有助於解決現實數據標註匱乏的問題。

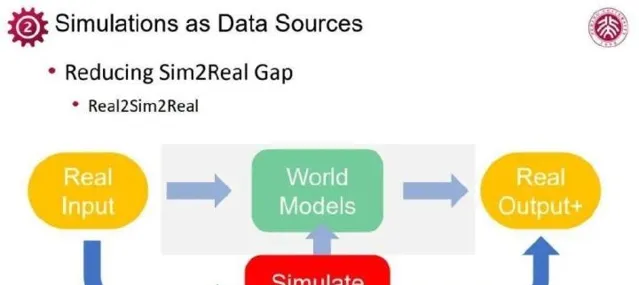
此外,蘇昊團隊及其他研究者還探索了復雜場景互動功能,如櫃門開啟、物體抓取等,更貼近真實世界互動,為機器人訓練等套用提供支持。可見,透過圖形計算提供的simulation能力,已經成為生成高質素、多功能教學數據的核心手段。雖然模擬與真實作象之間仍有差距,然而為了更好地生成貼近現實的數據,在具身智能等智能套用上,可以運用「real to sim」與「sim to real」的策略,前者是透過獲取真實世界傳感數據搭建相應的仿真環境,後者是透過改變模擬參數,生成更多樣的場景。
如若在這方面真正獲得進展,simulation取自真實世界的物理原理,需保證在各類動態、互動上的真實性,透過simulation來實作令人信服的「as-real-as-possible」。盡管「sim to real」不斷追求真實,但完全消除二者間的異同仍是難題。通常,在部署階段,往往還需「real to real」微調,獲取真實環境中的輸入輸出數據,進一步增強模型效能。
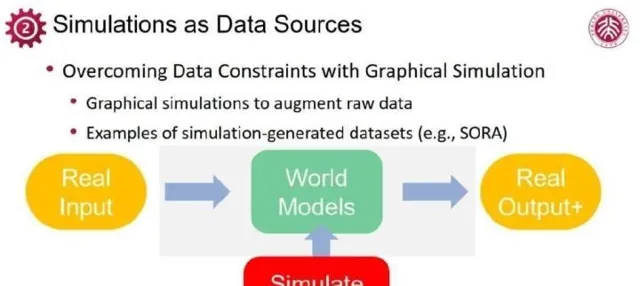
對眾多復雜套用場景,Real2Real數據十分有限,完全依賴於這類數據實作具身智能恐怕不夠。透過結合真實數據的simulation,展現出高真實數據生成的潛力,Real2Sim2Real框架便成為推動具身智能發展的重要路徑。在工業界迅速發展的無人駕駛領域,現實到模擬與模擬到現實的雙向轉換已取得初步成效。僅局限在數據生成的領域顯然低估了simulation的潛力,圖形仿真不再止於充當數據提供者,而是變成了訓練環境的構建者。
透過深度強化學習等先進技術,圖形仿真為訓練過程提供環境支持,使智能體得以學習、最佳化決策能力。而這正是構建世界模型的重要職能,涉及理解、預測、策略與執行等多個方面。作為電腦圖形領域的研究者,陳教授為圖形學在未來人工智能的發展中發揮越來越重要的作用感到自豪。

在不同領域,數碼人和機器人的運動控制,無人車行為調整等都在利用深度強化學習作為有效訓練方式。這一方法利用simulation環境中豐富的互動場景,透過深度強化學習決策背後的策略,獲得更有效的預測能力。北京大學劉利斌教授關於數碼人體運動控制的研究,結合了仿真環境等多個方向,取得了顯著成果。在這些強化學習研究中,物理仿真環境的有效互動極大地提升了模型的魯棒性和泛化能力。

如同上述,基於訓練過程中捕獲的真實人體動作,劉教授的團隊透過模擬環境與深度強化學習緊密結合,成功掌握了一些復雜的運動策略,如滑滑板、使用筷子等。模擬的精準性至關重要——越精準,學習質素越高,越接近現實。比如,近期研究中的肌肉模型不僅超越了傳統的關節動畫,更貼近人體真實運動機制,模擬諸多細節,比如長時間跑步後的疲憊與動作變化。

在機器人領域,一些較新的研究利用輝達的Omniverse平台等高效仿真框架,推進了仿真技術的進步與創新。因此,現實世界中物體變化與動態現象的復雜性與多樣性,需要我們不斷探索更精確與全面的仿真環境,模擬這些豐富的物理現象。

可微模擬的重要性在於透過可微分性原則,實作精細的梯度回傳機制,構建出監督學習的閉環,最佳化學習過程。轉變依賴於simulation全面實作可微分,保證有效的梯度傳遞與策略最佳化。雖然可微模擬領域已有初步探索,整體研究仍顯薄弱,但越來越受到重視。在這方面的一個亮點便是與模型的逆向軟體仿真結合。

透過捕捉真實荷葉在外力下晃動的數據,結合物理模型與參數,建立可微模擬系統,前向模擬荷葉運動,並透過最佳化實作準確擬合,使我們能夠準確模擬荷葉在不同條件下的響應。同樣,針對流體,基於可微性的技術也在實作真實流體重建上發揮潛力。可微模擬賦予了我們設計軟體機器人的形狀與物理參數能力,帶來了廣泛套用的可能性。

當前,盡管在全部可微模擬中已取得重要進展,實際套用場景仍面臨局限與資源需求高等挑戰,部份復雜現象非平滑性捆綁了技術的提升。但整體而言,探索這一領域的潛力無可置疑。總結來說,圖形仿真在世界模型訓練中發揮著關鍵作用,潛在的發展路徑寬廣且充滿機遇。希望大家能夠繼續挖掘這些強大潛能,為未來建立更深入的討論。期待與各位的熱烈交流!












