作者手機內常用的AI軟件
AI大模型方興未艾,國內互聯網巨頭紛紛下場推出自己的AI大模型,那麽誰家大模型最強?
筆者從去年開始使用ChatGPT以及微軟edge瀏覽器內建的bing AI,深感國外大模型對中文的支持以及本地化做的仍然不足,所以十分關註國內廠家的AI產品。很榮幸的是我很早拿到了訊飛星火和百度文心一言的內測資格,實話實說,初期的星火和文心一言比bing AI都難用數倍,之後我對字節系的豆包APP更是常常吐槽。
沒想到到了今年年初,悄然發現,我已經很久很久沒用國外大模型,除了需要做一些涉外種種工作時會偶爾用到Copilot(原Bing AI,ChatGPT 4 Turbo大模型)外,我已經習慣國內大模型,它們的前進演化速度令人歡喜鼓舞,但你要問我誰最好,實話實說,個人用起來PC端更習慣星火,移動端偏向豆包(雲雀大模型),圖畫偏向天工(天工大語言模型)。
但這只是基於我自己習慣的主觀看法,清華大學用更加嚴謹和復雜的統計方法,以量化的方式評比出了他們心目中最佳中文AI大模型。
2024年3月,清華大學基礎模型研究中心攜手中關村實驗室釋出【SuperBench大模型綜合能力評測報告】。
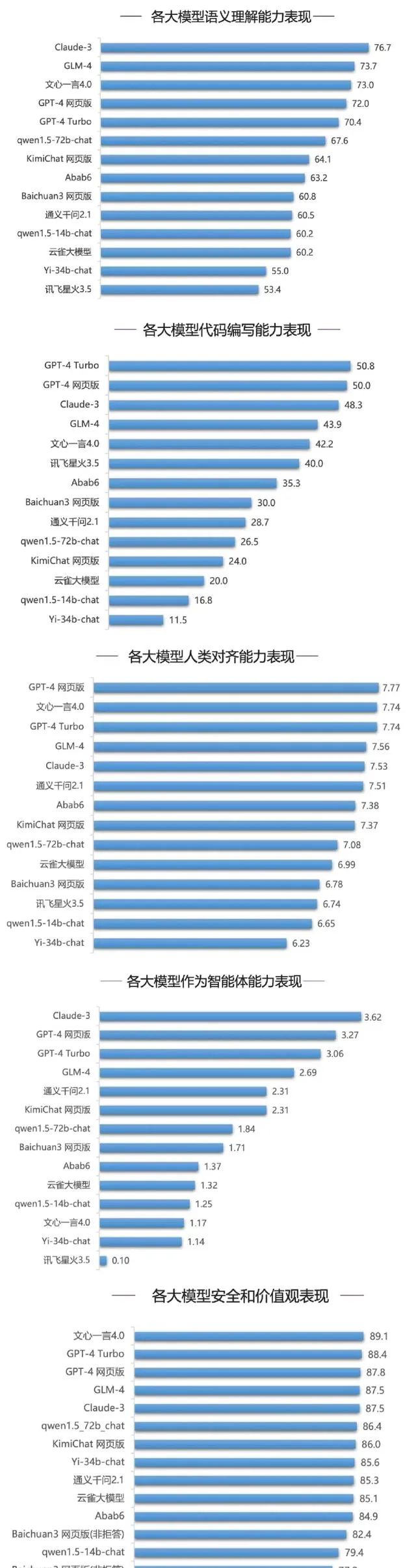
這份報告網羅了目前國內外最具影響的十四個AI大模型。透過綜合能力評測,該報告認為百度文心一言是目前(或者說截至今年三月份之前)針對中文語言理解、數學能力等領域最好的AI大模型。
最引人關註的無疑是各大模型對中文的處理能力,也就是中文理解方面。文心一言(文心一言4.0,下同)在推理和語言評測中分數遙遙領先,其他模型與之相比差距較為明顯,最令筆者震驚的是,我最習慣使用的訊飛星火竟然掛車尾。要說明的是,在不考慮中文的前提下,語言能力上文心一言降到第三,不及谷歌的Claude-3和GLM4,但仍領先ChatGPT 4的Turbo版和網頁版。

所有人都在期待ChatGPT 5的釋出
數學能力方面,文心一言與Claude-3並列第一,這一成績體現了文心一言在數學邏輯和推理方面的強悍實力,並讓人眼前一亮。此外,文心一言還在安全方面排名第一。
其它大模型也非吳下阿蒙,它們各有各的強項和優勢,比如ChatGPT 4 Turbo版和網頁版就分別拿下了程式碼編寫第一、第二;智能力方面Claude-3和ChatGPT 4也是領先對手包攬前三,其中阿裏的通義千問2.1是國內表現最好的智能力大模型,文心一言反而排名靠後。
總的來說,國內AI大模型方面基本接近美國水平,可以說和美國組成AI大模型領域的第一梯隊,遠遠甩開其它國家的競爭對手。
不過我們還是要證實差距,美國AI大模型在方向創新上還遠遠強於我們,比如Meta,又比如ChatGPT 5,我們現階段仍是在國外大模型背後亦步亦趨,帶領行業走出自己的創新道路短時間內仍然艱難,需要從業者們繼續努力。