2022年底ChatGPT的橫空出世,讓所有人驚嘆於自然語言處理聊天機器人(NLP)的能力,它們能夠將簡短的文本提示神奇地轉換為連貫的類人文本,甚至包括論文、語言轉譯和程式碼範例。科技公司也被 ChatGPT 的潛力深深吸引,紛紛開始探索如何將這項創新技術套用於自身產品和客戶體驗。
然而,與以往的AI模型相比,GenAI由於其更高的計算復雜度和功耗需求,帶來了顯著的「成本」提升。那麽,GenAI 演算法是否適用於對功耗、效能和成本都至關重要的邊緣器材套用呢?答案是肯定的,但是不無挑戰。
GenAI,下沈到邊緣端潛力巨大
GenAI,即生成式人工智能(Generative AI),是一類可以生成各種內容(包括類人文本和影像)的機器學習演算法。早期的機器學習演算法主要專註於辨識影像、語音或文本中的規律,並基於數據進行預測。而 GenAI 演算法則更進一步,它們能夠感知和學習規律,並透過模擬原始數據集按需生成新的規律。舉個例子,早期演算法可以預測某一影像中有貓的概率,而GenAI則可以生成貓的影像或詳細描述貓的特點。
ChatGPT可能是當下最著名的GenAI演算法,但並非唯一,目前已有眾多GenAI演算法可供使用,並且新演算法也在不斷湧現。GenAI演算法主要分為兩大類:文本到文本生成器(又名聊天機器人,如 ChatGPT、GPT-4 和 Llama2)和文本到影像生成模型(如 DALLE-2、Stable Diffusion 和 Midjourney)。圖 1展示了這兩種模型的範例。由於兩種模型的輸出類別不同(一種基於文本,另一種基於影像),因此它們對邊緣器材資源的需求也存在差異。

圖 1:文本到影像生成器 (DALLE-2) 和文本到文本生成器 (ChatGPT) 的 GenAI 輸出範例
傳統的GenAI套用場景往往需要連線互聯網,並存取大型伺服器群以進行復雜計算。然而,對於邊緣器材套用而言,這並非可行方案。邊緣器材需要將數據集和神經處理引擎部署在本地,以滿足低延遲、高私密、安全性和有限網絡連線等關鍵需求。
將GenAI部署於邊緣器材,蘊藏著巨大潛力,能夠為汽車、相機、智能電話、智能手錶、虛擬現實/增強現實 (VR/AR) 和物聯網 (IoT) 等領域帶來全新機遇和變革。
例如,將GenAI部署到汽車中,由於車輛並不總是受到無線訊號覆蓋,因此 GenAI 需要利用邊緣可用的資源執行。GenAI的套用包括:
- 改善道路救援,並將操作手冊轉換為AI增強的互動式指南。
- 虛擬語音助手,基於GenAI的語音助手能夠理解自然語言指令,幫助駕駛員完成導航、播放音樂、發送資訊等操作,同時確保行車安全。
- 個人化座艙:根據駕駛員的喜好和需求,客製車內氛圍照明、音樂播放等體驗。
其他邊緣套用也可能受益於GenAI。透過本地生成影像並減少對雲處理的依賴,可以最佳化AR 邊緣器材。另外,語音助手和互動式問答系統也可以套用於很多邊緣器材上。
但是GenAI在邊緣器材上的套用尚處於起步階段,要實作大規模部署, 需要突破計算復雜性和模型大小的瓶頸,並解決邊緣器材的功耗、面積和效能限制問題。
挑戰來了,如何將GenAI部署到邊緣側?
想要理解 GenAI並且將之部署到邊緣側,我們首先需要了解它的架構和運作方式。
GenAI 快速發展的核心是transformers,一種新型的神經網絡架構, 是Google Brain團隊在2017年的論文中提出的。與傳統的遞迴神經網絡 (RNN) 和用於影像、影片或其他二維或三維數據的摺積神經網絡 (CNN)相比,transformers在處理自然語言、影像和影片等數據方面展現出了更強大的優勢。
Transformers之所以如此出色,關鍵在於其獨特的 註意力機制 。與傳統的 AI 模型不同,transformers更加關註輸入數據中的關鍵部份,例如文本中的特定字詞或影像中的特定像素。這種能力使transformers能夠更準確地理解上下文,從而生成更加逼真和準確的內容。與 RNN 相比, transformers 能夠更好地學習文本字串中單詞之間的關系,與 CNN 相比,可以更好地學習和表達影像中的復雜關系。
得益於海量數據的預訓練,GenAI 模型展現出強大的能力,使他們能夠更好地辨識和解讀人類語言或其他類別的復雜數據。 數據集越大,模型就越能更好地處理人類語言。
與 CNN 或視覺轉換器機器學習模型相比,GenAI 演算法的參數(神經網絡中用於辨識規律和建立新規律的預訓練權重或系數)要大幾個數量級。如圖2所示,用於基準測試的常見 CNN 演算法 ResNet50 擁有2500萬個參數,而一些 GenAI 模型(如BERT 和 Vision Transformer (ViT) )的參數則高達數億。
然而也有例外,Mobile ViT 是一種經過最佳化的 GenAI 模型,其參數數量可以和CNN模型 MobileNet 相媲美,這意味著它可以用於計算資源有限的邊緣器材上。
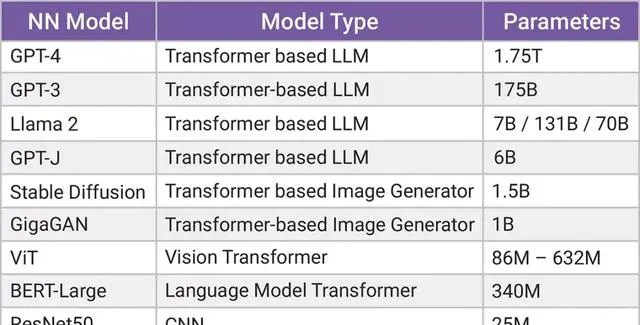
圖 2:各種機器學習演算法的參數大小
由此可見,GenAI 模型功能雖強大,但也需要龐大的參數數量來支持。鑒於邊緣器材的記憶體有限,嵌入式神經處理單元 (NPU) 怎樣才能完成處理如此巨大參數數量的工作?
答案是它們無法完成。
為了解決這一難題,研究人員正在積極探索參數壓縮技術,以減少 GenAI 模型的參數數量。例如,Llama-2 提供了700億個參數的模型版本,甚至更小的 70 億個參數模型。雖然具有 70 億個參數的 Llama-2 仍然很大,但已經處於嵌入式 NPU能實作的範圍內了。MLCommons 已將 GPT-J(一個具有 60 億個參數的 GenAI 模型)添加到其 MLPerf 邊緣 AI 基準列表中。
選擇最快的記憶體介面很重要
GenAI 演算法的強大功能背後,隱藏著對計算資源和記憶體頻寬的巨大需求。如何平衡這兩者之間的關系,是決定 GenAI 架構的關鍵因素。
例如,文生圖往往需要更多的計算能力和更高的頻寬支持,因為處理二維影像需要大量計算,但參數量相差不大(通常在億範圍內)。大型語言模型的情況較為不平衡,它們需要較少的計算資源,但需要大量的數據傳輸。即使是較小規模的語言模型(例如6-7億參數的模型),也受到記憶體限制的影響。
解決這些問題的有效方法是 選擇更快的記憶體介面。 從圖3可以看出,邊緣器材通常使用的LPDDR5記憶體介面頻寬為51 Gbps,而HBM2E可以支持高達461 Gbps的頻寬。使用 LPDDR 記憶體介面會自動限制最大數據頻寬,這意味著,與伺服器套用中使用的 NPU 或 GPU 相比,邊緣套用給予 GenAI 演算法的頻寬將自動減少。我們可以透過增加片上 L2 記憶體的數量來解決這個問題。

圖 3:LPDDR和HBM之間的頻寬和功率差異
在ARC® NPX6 NPU IP上實作 GenAI
要針對GenAI等基於Transformer的模型實作高效的NPU設計,就需要復雜的多級記憶體管理。
新思科技的ARC® NPX6處理器具有靈活的記憶體架構,可支持可延伸的L2記憶體,最高可支持64MB的片上SRAM。此外,每個NPX6內核都配備了獨立的DMA,專門用於執行獲取特征圖和系數以及編寫新特征圖的任務。這種任務區分可以實作高效的流水線數據流,從而最大限度地減少瓶頸並最大化處理吞吐量。該系列在硬件和軟件中還具有一系列頻寬節省技術,以最大化利用頻寬。
Synopsys ARC® NPX6 NPU IP 系列基於第六代神經網絡架構,旨在支持包括 CNN 和轉換器在內的一系列機器學習模型。NPX6 系列可透過可配置數量的內核進行擴充套件,每個內核都有自己的獨立矩陣乘法引擎、通用張量加速器 (GTA) 和專用直接記憶體存取 (DMA) 單元,用於簡化數據處理。NPX6 可以使用相同的開發工具,將需要效能低於1 TOPS的套用擴充套件為需要數千TOPS的套用,從而最大限度地提高軟件的重復使用。
矩陣乘法引擎、GTA 和 DMA 全都經過最佳化以支持轉換器,使 ARC® NPX6 能夠支持 GenAI 演算法。每個內核的 GTA 都經過明確設計和最佳化,可高效執行非線性函數,例如 ReLU、GELU、Sigmoid。這些功能使用靈活的尋找表方法加以實作,可預測未來的非線性函數。GTA 還支持其他關鍵操作,包括轉換器所需的 SoftMax 和 L2 標準化。除此之外,每個內核內的矩陣乘法引擎每個迴圈可以執行 4,096 次乘法。由於 GenAI 基於轉換器,因此在 NPX6 處理器上執行 GenAI 沒有計算限制。
在嵌入式 GenAI 套用中,ARC NPX6 系列將僅受系統中可用LPDDR的限制。NPX6能夠成功執行Stable Diffusion(文本到影像)和 Llama-2 7B(文本到文本)GenAI 演算法,而其效率取決於系統頻寬和片上SRAM的使用情況。雖然更大的GenAI模型也可以在 NPX6 上執行,但它們會比在伺服器上實作的更慢(按照每秒令牌數測量)。
結論
隨著行業各界人士不斷探索新的演算法和最佳化技術,以及IP廠商的助推,未來,GenAI 將徹底改變我們與器材互動的方式,為我們帶來更加智能化、個人化和美好的未來。











