ChatGPT使用者狂喜,AI創業公司搖頭。
趕在 Google I/O 大會之前,5 月 14 日淩晨,OpenAI 釋出了一個新模型——GPT-4o。
對,不是搜尋,不是 GPT-5,而是 GPT-4 系列的一款全新多模態大模型。按照 OpenAI CTO 米拉·穆拉蒂(Muri Murati)的說法,GPT-4o——「o」代表了 omni(意為「全能的」)——能夠接受文本、音訊和影像任意組合的輸入與輸出。
而新的 GPT-4o 模型響應更快、處理更快、效率更高,也讓人機互動在一定程度上發生了質的變化。
事實上,在不到 30 分鐘的釋出會中,最為人津津樂道的不是 GPT-4o 這個模型自身,而是在 GPT-4o 的支撐下,ChatGPT 的互動體驗。 不僅是人機語音對話體驗更接近人與人之間的即時對話,視覺辨識能力的進步也讓 AI 更能基於現實世界進行語音互動。
簡而言之就是更自然的人機互動。這很容易讓人想起【她(Her)】中的 AI 虛擬助手,包括 OpenAI CEO 山姆·奧爾特曼(Sam Altman):
圖/ X
但對很多人來說,更重要的可能是免費使用者也能使用 GPT-4o(不包括新的語音模式),官方說將在接下來幾周正式推出。 當然,ChatGPT Plus 付費使用者顯然還是有「特權」的,從今天開始就可以提前試用 GPT-4o 模型。
圖/ ChatGPT
不過 OpenAI 演示中的桌面套用還未上線,ChatGPT 移動端 APP(包括 Android 與 iOS)也還沒更新到釋出會演示的版本。總之,ChatGPT Plus 使用者暫時還體驗不到的 ChatGPT(GPT-4o)新的語音模式。
圖/ X
所以在某種程度上,目前 ChatGPT Plus 使用者享受到的 GPT-4o 基本是未來幾周 ChatGPT 免費版使用者的體驗。
但 GPT-4o 的實際表現如何?值不值得免費版使用者重新開始使用 ChatGPT?說到底還是需要實際的上手體驗。同時,透過目前基於文本和影像的對話,我們或許也能窺見新 ChatGPT(GPT-4o)的能力。
從一張圖片中看出【原神】,GPT-4o 更懂影像了
GPT-4o 模型的所有升級,其實都可以總結為原生多模態能力的全面提升,不僅是文本、音訊和影像任意組合的輸入、輸出,同時各自的理解能力也有明顯的進步。
尤其是影像理解。
在這張圖片中,有被部份遮擋的書本,還有一台正在執行遊戲的手機,GPT-4o 不僅能準確辨識書本上文字,根據知識庫或者聯網正確地辨識出完整的書名, 最讓人驚艷的是能直接看出手機正在執行的遊戲——【原神】。

圖/ ChatGPT
坦白講,熟悉【原神】這款遊戲的玩家大概都能一眼看出本體,但僅憑這張圖片,很多沒玩過遊戲、不了解遊戲角色的人基本都認不出【原神】。
當小雷詢問 ta 怎麽看出是【原神】時,GPT-4o 的回答也符合邏輯:無非就是畫面內容、遊戲界面以及視覺風格。

圖/ ChatGPT
但同樣的圖片和問題,但我詢問通義千問(阿裏旗下)和 GPT-4,它們給出回答卻很難令人滿意。
類似的,在看了馬斯克剛發的梗圖之後,GPT-4o 也能較為準確地理解其中的笑點和諷刺之處。
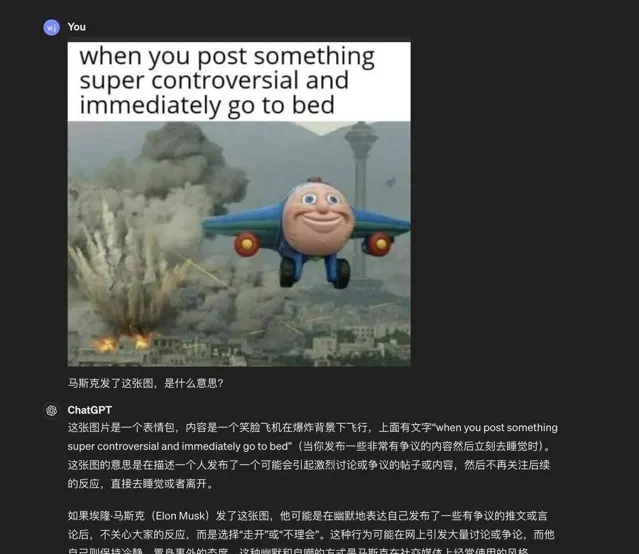
圖/ ChatGPT
而在移動端 ChatGPT APP 上,透過一張非常局部的拍攝照片,GPT-4o 對場景的描述也算準確,並且也大致推理住宅區或者辦公樓等範圍。
圖/ ChatGPT
以上這些例子,其實都能在一定程度上說明 GPT-4o 在影像理解方面的進步。需要一提的是, 根據 OpenAI 新的政策,幾周後免費版 ChatGPT 使用者也支持直接拍照或者上傳圖片給 GPT-4o。
此外,免費版使用者在使用 GPT-4o 時,還能使用透過上傳檔幫助總結、撰寫和分析。不過從檔個數和大小上,ChatGPT 可能還是不如 Kimi 或者其他國內 AI 聊天機器人大膽,限制明顯。
當然優點還是有,畢竟 GPT-4o 有著 GPT-4 的頂級「智能」。
新模式還沒來,但語音體驗已經上了一個台階
但比起影像理解能力,在小雷看來,這次 GPT-4o 最重要的能力升級還得是語音。
雖然新的語音模式還沒實裝,很多演示中的體驗都沒辦法感受,但開啟現有的語音模式聊幾句,就能發現 GPT-4o 的語音體驗已經有明顯的升級。
其一,不僅音色音調非常接近正常人的聲音,更關鍵的是 AI 也能熟練掌握各種語氣詞,比如「嗯」「啊」等,對話中也會有一定的抑揚頓挫。與此相對的,能明顯感受到,GPT-4o 下語音模式的回應更接近普遍意義上的「有感情」。
相比 Siri 等語音助手理所當然有大幅的進步,甚至比起目前一堆的生成式 AI 語音聊天,GPT-4o 下語音也顯得更加保真和自然。
其二,過去在語音模式的對話中,說完話往往需要較長的時間才能讓 ChatGPT 意識到我說完了,然後開始上傳、處理和輸出回答,以至於很多時候我會選擇手動控制。但在 GPT-4o 下,ChatGPT 能夠更靈敏地意識到我說完了並開始處理,基本就少了很多手動幹涉。

目前還是舊的語音模式和界面,圖/ ChatGPT
不過缺點也有,有些小雷估計正式推出時也很難有明顯的改善,比如一直在討論的「幻覺」問題,並沒有感受到明顯的改善;但有些可能將在推出發生質的改變,比如對話的延遲。
從目前版本的體驗來看,就算在聊天模式下網絡連線一切正常,語音模式一開始連線就會花費不短的時間,甚至是連線失敗。但即使連線上了,對話延遲還是很高,經常是我說完了要等待數秒才能等到語音回應。
實際上,舊的語音模式其實是先將使用者的語音透過 OpenAI 的 Whisper 模型轉錄成文本,再透過 GPT-3.5/GPT-4 進行處理和輸出,最後再透過文本轉語音模型將文本轉錄為語音。 這麽一通下來,也就不難理解之前 ChatGPT 語音回答之慢、語音互動體驗之差的的原因了。
同時,這也是新的語音模式讓人期待的核心原因。 按照 OpenAI 的說法,GPT-4o 則是跨文本、視覺和音訊端到端訓練的新模型,在新的語音模式下所有輸入和輸出都由同一個神經網絡處理。甚至不只是文本和語音,新的語音模式還能基於手機網絡攝影機的即時畫面進行對話。

新的語音模式和界面,圖/ OpenAI
簡單來說,原來 ChatGPT 回應你的語音必須要依序經過三個「腦」(模型)的處理和輸出。而在即將到來的新模式下,ChatGPT 只要經過一個同時支持文本、語音乃至影像的「大腦」(模型),效率提升也就自然可以想象了。
至於到底能不能實作 OpenAI 演示中的超低延遲回應,還是要等未來幾周新模式的實裝,屆時小雷也會在第一時間進行體驗。
寫在最後
誠然,在 GPT-4 釋出以來的一年裏,全球大模型還在瘋狂湧現和叠代,與 GPT-4 之間的差距也在不斷拉小,甚至一度超越(Claude 3 Opus)。但從權威基準測試、對戰 PK 排行榜以及大量使用者的反饋來看,GPT-4 依然是全球最頂級的大模型之一。
更重要的是,技術塑造能力,產品塑造體驗。GPT-4o 再次證明了 OpenAI 依然在技術和產品上的絕對實力,而 GPT-4o 對於語音互動體驗的叠代,恐怕還會再次消滅一批 AI 語聊、AI 語音助手方向的創業公司。
但另一方面,我們也再次看到了人機語音互動發生質變的希望。











