進入2024年,大模型和生成式AI的迅速崛起,正在重新定義技術和商業競爭的邊界。在中國市場,有這樣一個問題——誰能成為中國版的OpenAI?
在這個關鍵時刻,商湯科技的2023年財報成為了業界關註的焦點。盡管財報顯示其收入34億人民幣,同比下降11%,這背後實際上是一場深思熟慮的轉型——一次「騰籠換鳥」式的業務結構變化。商湯科技主動縮減了其曾經占主導地位的智慧城市業務,將資源和焦點轉移到了快速增長的生成式AI領域。
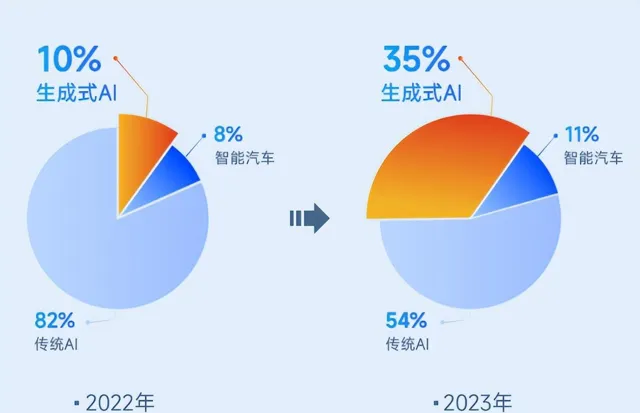
商湯科技各業務板塊收入占比變動情況 數據來源:商湯科技財報
這一轉變標誌著商湯科技已經邁入一個全新的發展階段,如此看來,它已經不再是人們記憶中的那個商湯科技了。那麽,商湯科技變成了什麽呢?
AI大裝置+大模型雙輪驅動,生成式AI高速增長
推出大模型的公司很多,但能這麽快透過大模型賺錢的公司卻很少。如果說2023年是生成式AI的技術元年,那2024年就是商業落地元年。而商業落地的成敗,最核心的評價指標就是能否兌現足夠的業務收入。
財報數據顯示,商湯科技生成式AI收入貢獻較多,達到了12億元,增速達到了200%。據悉,這也是商湯成立以來,以最快速度從無到有、超過10億收入體量的新業務。
如何實作?深入分析其業務特征,可以發現,商湯科技在生成式AI領域的增長邏輯,可以歸結為:在感知智能、決策智能的長期積累,加上大裝置與大模型的深度協同。
一方面,技術實力是基礎。
生成式AI的成功商用,核心依賴於其技術的成熟度和實用性。在技術層面,生成式AI需要具備強大的理解、推理和創造能力,這不僅要求模型能夠處理和生成前所未有的復雜數據類別,還要求其能在多變的套用場景中保持高效和準確。
然而,生成式AI面臨的技術難點不少。例如,模型泛化與適應力就是一大難題,雖然當前的生成式AI模型在特定任務上表現出色,但在面對新領域或新問題時,模型的泛化能力和適應力仍有限。模型需要在保持高效能的同時,具備跨領域套用的能力;數據偏差也是一個嚴重問題,可能導致模型生成帶有偏見的結果;生成式AI的強大能力也帶來了潛在的風險,如生成不準確或有害的內容,則可能面臨業務合規的挑戰。要解決這一系列問題,需要深厚的技術積澱才行。
在過去十年中,商湯科技深耕於感知智能和決策智能,積累了豐富的多模態數據資源,這些不僅增強了其基礎模型對物理世界的理解能力,也極大地提升了模型處理多種數據類別的能力。特別是商湯科技推出的「日日新」大模型,在基礎模型構建、多模態理解、程式語言處理、工具呼叫,以及處理百萬字級無失真上下文資訊等方面,達到了業內領先水平。
「日日新」4.0版本在多個套用場景中展現出的能力,如程式碼編寫、數據分析、醫療問答等,不僅與GPT-4持平,甚至在某些方面超越了它。。
另一方面,算力是大模型最大瓶頸,AI大裝置SenseCore成為商湯科技攻城拔寨的「彈藥庫」。
大模型訓練的本質是一個計算密集型過程,對算力的需求極其龐大。這種對算力的依賴,使得掌握足夠算力資源的企業,能夠在生成式AI的研發和套用上取得先機。在這個意義上,算力成為了企業在生成式AI領域進攻和防守的重要「彈藥」。風險資本投資大模型創業公司,最關鍵的就看兩個指標,一個看公司有沒有厲害的人才,另一個就是看公司手裏有沒有足夠的算力。
對於商湯科技而言,其AI大裝置SenseCore的建設和營運,昭示著公司在算力資源配置上的戰略遠見。財報數據顯示,商湯科技的算力規模已經達到了12,000 petaFLOPS,擁有45,000卡GPU。透過龐大的算力支撐,商湯科技成功實作了對萬億參數級別大模型的有效訓練,從而為公司在生成式AI領域的快速發展奠定基礎。
在AI大模型領域,有一個著名的 「尺度定律」(Scaling Law):隨著模型大小(如參數數量)、數據集規模、或計算資源(如訓練時的算力投入)的增加,模型的效能(如準確率、生成質素)通常會呈現出持續改善的趨勢 ,這包括但不限於更好的泛化能力、更強的推理能力和更高的任務解決效率。
尺度定律,推動了AI大模型規模的不斷擴大。然而,模型規模的增加也帶來了算力需求的急劇上升。這要求算力大裝置不僅要有足夠的計算資源,還需要具備高度的可延伸性和彈性,以適應模型規模的快速增長。同時,如何在保證模型效能提升的同時,控制訓練成本,避免算力資源的無效消耗,成為演算法與算力協同過程中需要解決的重要問題。
商湯科技的AI大裝置SenseCore+「日日新」大模型的協同,則是遵循尺度定律的典型案例:「日日新」大模型在萬卡算力的保障下,遵循尺度定律不斷提升效能;而源於大模型研發的深刻理解,幫助商湯更有前瞻性地設計基礎設施,實作領先同行的算力效率和彈性。
需要指出的是,商湯科技所實作的這種協同,不僅是簡單的演算法最佳化和硬件升級,而是一個涉及計算架構、模型設計、演算法效率和資源管理等多個層面的復雜系統工程。算力大裝置的設計需要考慮到模型架構的特點,以及模型訓練和推理過程中的計算需求。這意味著,計算架構必須能夠靈活適應不同的模型設計,支持平行計算、分布式訓練等技術,從而實作模型訓練的高效率和低成本。同時,大模型的設計也需要考慮到算力的限制,透過模型壓縮、量化、稀疏化等技術降低對算力的需求,提高模型的運算效率。透過改進模型訓練演算法、引入更高效的最佳化器和排程策略,可以在不增加額外算力的情況下提升模型的訓練速度和質素。
聚焦大模型推理,快速推進商業落地
上面,我們分析了商湯科技的基本能力。要實作可持續發展,需要將這些能力實作商業落地。一個公司要在市場中立足,首先是要找到自己在產業中的位置。那麽,商湯科技將自己定位在哪裏呢?
商湯科技董事長兼CEO徐立,在2024全球開發者先鋒大會(GDC)中提出的「大模型能力的三層架構」理論,為理解商湯科技的大模型套用策略,提供了重要視角。
一般來看, 大模型可以分為三層能力框架,分別是知識層、推理層和執行層。
其中,第一層是知識層,大模型透過對海量數據的學習,吸收世界知識,形成對不同領域知識的全面理解。第二層是推理層,在知識層之上,推理層使得AI能夠在掌握大量知識的基礎上進行邏輯推理和決策。第三層是執行層,關註如何將AI的知識和推理能力轉化為具體行動,與現實世界進行互動。這涉及到AI在物理環境中的操作能力,如自動駕駛、機器人控制等。
其中,推理層在生成式AI體系中起著至關重要的作用,透過對海量數據中抽象模式的邏輯演繹和推演,推理層使AI能夠在面對未曾遇見的問題時,提出創造性的解決方案。此外,推理過程本身的反饋還能促進知識層的持續最佳化,形成一個動態學習和前進演化的閉環。因此,推理層不僅是AI智能處理的核心,也是實作AI技術深度商業落地和跨越式發展的關鍵。
商湯科技正是聚焦於推理層,將生成式AI深度融入到各個行業和領域中,並取得了不菲「戰果」。在C端,商湯科技的大模型C端呼叫量,在過去半年呈現出近120倍的增長;在金融、醫療、Copilot助手、擬人互動、智能終端等B端套用中,商湯科技的大模型不僅提供了決策支持,更在復雜的數據分析和處理中展現了出色的能力,其客戶涵蓋中國銀行、招商銀行、中國工商銀行等金融機構,上海交通大學醫學院附屬新華醫院、瑞金醫院以及鄭州大學第一附屬醫院等醫療機構,金山辦公、小米、榮耀等領域頭部企業。

商湯科技生成式AI典型客戶
我們可以透過一個具體的客戶套用案例,來看商湯科技的生成式AI技術,如何賦能客戶。
客戶案例:上海銀行,基於大模型打造AI數碼人,降低服務門檻。
上海銀行,在其數碼化轉型過程中遇到了雙重挑戰:一方面,需要在有限的人力資源下滿足日益增長的、多樣化的金融服務需求;另一方面,銀行面臨著如何縮小數碼鴻溝,尤其是對年長客戶群體而言,普及和降低數碼服務的使用門檻成為了迫切需求。這些痛點不僅關系到服務效率和覆蓋範圍的提升,也關乎客戶體驗的全面最佳化。
針對這些挑戰,商湯科技提供了基於日日新大模型體系的解決方案,透過打造AI數碼人員工「海小智」和「海小慧」,深度整合了生成式AI的前沿技術。這兩位AI數碼人員工不僅具備高度擬人化的表達和互動能力,還透過對2000條問答數據和10萬條語料數據的深度學習,實作了對客戶需求的精準理解和響應,顯著提高了服務的可及性和個人化。
目前來看,該方案套用效果顯著,特別是對於上海銀行60歲以上的客戶群體,「「海小智」和「海小慧」有效降低了使用門檻,使得老年客戶也能輕松享受到手機銀行的便捷服務。此外,這一方案還極大地提升了客戶服務的效率和質素,在不增加人力資源的情況下,實作了更高頻次的客戶互動和服務滿足。
商湯科技的天花板,更高了
透過分析商湯科技的發展歷程和其業務特征,我們發現其與OpenAI有諸多相似之處。
OpenAI自2015年成立以來,透過不斷的技術創新,推出了一系列引領行業發展的生成式AI產品,如GPT系列。直到推出ChatGPT,OpenAI迅速出圈,奠定了自己在AI市場的地位。
商湯科技成立於2014年,比OpenAI還早一年「出生」。成立以來,商湯科技也依托其在電腦視覺、深度學習等方面的深厚技術積累,持續推動技術創新。2023年,商湯推出在生成式AI領域的「日日新SenseNova」系列產品,展現了其在AI技術創新上的實力,並迅速實作商業突破。
在直接的大模型競爭方面,商湯科技正加緊追趕OpenAI的腳步。商湯新近釋出的 「日日新SenseNova 4.0」不僅在知識覆蓋、推理能力、長文本理解、數碼推理以及程式碼生成方面實作了全面升級,還引入了支持跨模態互動的能力。
尤其值得註意的是,「日日新·商量」大語言模型通用版本(SenseChat V4)在綜合評測中與GPT-4不相上下,甚至在某些關鍵領域如推理和程式碼編程方面超越了GPT-4。特別是在HumanEval Coding測試中,其一次透過率達到75.6%,超越了GPT-4的74.4%。在醫療領域,「大醫」模型在兩項行業權威評測中均獲得了第二名的好成績,效能接近乃至部份超越了GPT-4。
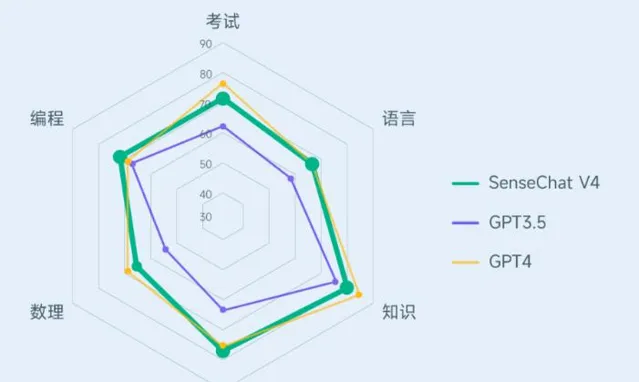
SenseChat V4與GPT4、GPT3.5對比 數據來源:基於Opencompass full全集測試
看完技術比較,我們再來看看商業化成果。根據【路透社】報道,OpenAI在2023年一整年的營收16億美元,商湯科技營收4.7億美元(34億人民幣,匯率:1 美元 ≈ 7.2 人民幣),約為OpenAI的30%;如果只算商湯科技的生成式AI收入,則有1.7億美元(12億人民幣),超過OpenAI的10%。
而算市值,商湯科技為30億美元(234億港元,2024年3月27日市值),不到OpenAI近1000億美元估值的3%。如果再考慮到商湯科技在生成式AI領域200%的增速,目前商湯科技的價值被嚴重低估。
2024年,商湯科技迎來了10周歲生日,這也成為他轉變的一個契機。商湯在財報中闡釋了下一步計劃,推動業務增長和核心業務盈利,穩健而前瞻地占據AI 2.0時代有利競爭地位。











