夢晨 發自 凹非寺量子位 | 公眾號 QbitAI
AI做數學題,真正的思考居然是暗中「心算」的?
紐約大學團隊新研究發現,即使不讓AI寫步驟,全用無意義的「……」代替,在一些復雜任務上的表現也能大幅提升!
一作Jacab Pfau表示:只要花費算力生成額外token就能帶來優勢,具體選擇了什麽token無關緊要。

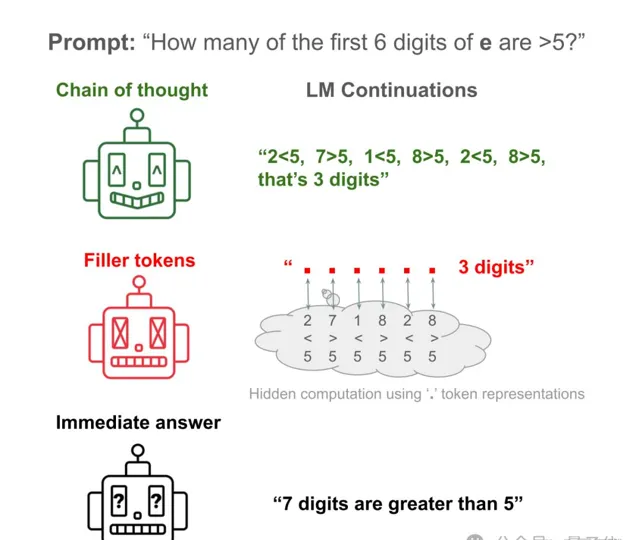
舉例來說,讓Llama 34M回答一個簡單問題:自然常數e的前6位數碼中,有幾個大於5的?
AI直接回答約等於瞎搗亂,只統計前6位數碼居然統計出7個來。
讓AI把驗證每一數碼的步驟寫出來,便可以得到正確答案。
讓AI把步驟隱藏,替換成大量的「……」,依然能得到正確答案!
這篇論文一經釋出便掀起大量討論,被評價為「我見過的最玄學的AI論文」。

那麽,年輕人喜歡說更多的「嗯……」、「like……」等無意義口癖,難道也可以加強推理能力?
從「一步一步」想,到「一點一點」想
實際上,紐約大學團隊的研究正是從思維鏈(Chain-of-Thought,CoT)出發的。
也就是那句著名提示詞「讓我們一步一步地想」(Let‘s think step by step)。

過去人們發現,使用CoT推理可以顯著提升大模型在各種基準測試中的表現。
目前尚不清楚的是,這種效能提升到底源於模仿人類把任務分解成更容易解決的步驟,還是額外的計算量帶來的副產物。
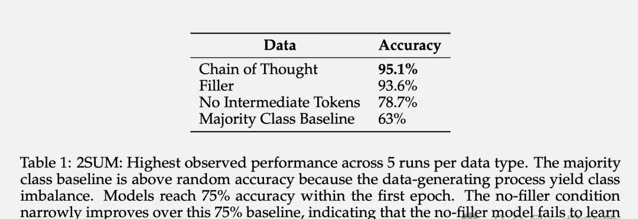
為了驗證這個問題,團隊設計了兩個特殊任務和對應的合成數據集:3SUM和2SUM-Transform。
3SUM要求從一組給定的數碼序列中找出三個數,使得這三個數的和滿足特定條件,比如除以10余0。

這個任務的計算復雜度是O(n3),而標準的Transformer在上一層的輸入和下一層的啟用之間只能產生二次依賴關系。
也就是說,當n足夠大序列足夠長時,3SUM任務超出了Transformer的表達能力。
在訓練數據集中,把與人類推理步驟相同長度的「...」填充到問題和答案之間,也就是AI在訓練中沒有見過人類是怎麽拆解問題的。

在實驗中,不輸出填充token「…...」的Llama 34M表現隨著序列長度增加而下降,而輸出填充token時一直到長度14還能保證100%準確率。

2SUM-Transform僅需判斷兩個數碼之和是否滿足要求,這在 Transformer 的表達能力範圍內。
但問題的最後增加了一步「對輸入序列的每個數碼進行隨機置換」,以防止模型在輸入token上直接計算。
結果表明,使用填充token可以將準確率從 78.7%提高到93.6%。
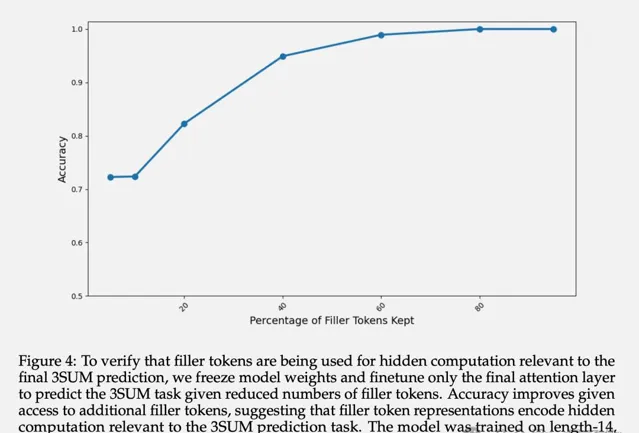
除了最終準確率,作者還研究了填充token的隱藏層表示。實驗表明,凍結前面層的參數,只微調最後一個Attention層,隨著可用的填充token數量增多,預測的準確率遞增。
這證實了填充token的隱藏層表示確實包含了與下遊任務相關的隱性計算。
AI學會隱藏想法了?
有網友懷疑,這篇論文難道在說「思維鏈」方法其實是假的嗎?研究這麽久的提示詞工程,都白玩了。

團隊表示,從理論上講填充token的作用僅限於TC0復雜度的問題範圍內。
TC0也就是可以透過一個固定深度的電路解決的計算問題,其中電路的每一層都可以並列處理,可以透過少數幾層邏輯門(如AND、OR和NOT門)快速解決,也是Transformer在單此前向傳播中能處理的計算復雜度上限。
而足夠長的思維鏈,能將Transformer的表達能力擴充套件到TC0之外。
而且讓大模型學習利用填充token並不容易,需要提供特定的密集監督才能收斂。
也就是說,現有的大模型不太可能直接從填充token方法中獲益。
但這並不是當前架構的內在局限性,如果在訓練數據中提供足夠的示範,它們應該也能從填充符號中獲得類似的好處。
這項研究還引發了一個令人擔心的問題:大模型有能力進行無法監控的暗中計算,對AI的可解釋性和可控性提出了新的挑戰。
換句話說,AI可以不依賴人類經驗,以人們看不見的形式自行推理。
這既刺激又可怕。

最後有網友開玩笑提議,讓Llama 3首先生成1千萬億點點點,就能得到AGI的權重了(狗頭)。

論文:https://arxiv.org/abs/2404.15758
參考連結:[1]https://x.com/jacob_pfau/status/1783951795238441449[2]https://x.com/johnjnay/status/1784261779163349110











