這幾天字節的大模型事件鬧得沸沸揚揚,一名實習生居然能給公司造成巨量的損失,不少人覺得不可思議。但從方法上來說,其實是可以達到的。這篇文章,作者就給我們分享了如何實作的辦法。
這兩天,字節 GPU 投毒事件沸沸揚揚:


和朋友們細聊了這個事兒,也在這裏給大家盤一盤。
根據公開資訊,推測一下可能的實作方法,或為三個方面:
- 惡意程式碼執行
- 擾亂模型訓練
- 程式碼隱藏與對抗
下面介紹每個唯維度可能攻擊的手法,以及如何進行安全防護。
一、惡意程式碼執行攻擊者透過精心設計的模型檔或數據集,利用底層庫的漏洞,引發遠端程式碼執行(RCE),從而獲得控制權。在這種攻擊中,即便攻擊者沒有直接的集群 SSH 許可權,也可以透過以下幾種方式悄無聲息地執行惡意程式碼。
1. 有關 transformer
以 transformers 庫為例,已經發現了多起相關的安全漏洞:
這些漏洞的存在,意味著如果攻擊者能夠控制模型檔內容,便可透過反序列化行為,在模型載入的瞬間就可以觸發惡意程式碼執行。
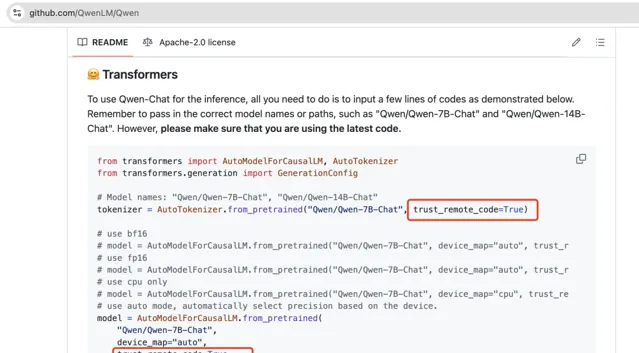
2. trust_remote_code:遠端程式碼執行的「後門」
在 transformers 庫中,還有一個較為隱蔽的危險選項:trust_remote_code。這個參數允許從遠端伺服器載入程式碼,並直接在本地執行。它的初衷是為了方便開發者快速獲取並使用最新的模型和功能,但同時也給了攻擊者一個可乘之機。
當 trust_remote_code=True 時,攻擊者可以誘導使用者載入一個經過篡改的模型,而這個模型會包含惡意程式碼。一旦載入,惡意程式碼將在本地執行,可能導致系統被入侵、數據泄露,甚至模型訓練過程被完全掌控。
目前大多數開源模型的官方教程都預設開啟這個選項,如果倉庫許可權被控制,後果不堪設想。
3. 惡意數據集
除了模型檔,攻擊者還可以透過偽造數據集來達到執行惡意程式碼的目的。
huggingface 的 datasets 庫是目前最流行的數據集載入工具之一,但該庫也存在一個潛在的安全風險:如果下載的數據集中包含與數據集同名的 Python 指令碼,datasets 庫在載入數據時會自動執行該指令碼。
換句話說,攻擊者可以透過嵌入惡意程式碼在數據集中,來實作遠端程式碼執行。
官方已明確指出,這一行為是 datasets 的「特性」而非漏洞,但這無疑給了攻擊者一個可利用的機會。
二、擾亂模型訓練:隱蔽的「暗手」如何影響 AI 模型在 GPU 模型投毒攻擊中,觸發惡意程式碼執行只是開始。更為隱蔽且難以察覺的是攻擊者透過精細化手段,直接幹擾模型的訓練過程。這不僅讓模型的最終效果變得不可預測,甚至可能導致模型朝著錯誤的方向訓練,產生嚴重的商業後果。本文將揭示幾種常見的擾亂模型訓練的方式,讓大家更加警惕這一隱秘的威脅。
1. 修改模型層輸出:讓模型「產生幻覺」
在深度學習模型的訓練過程中,模型的每一層都會輸出中間結果,並依次傳遞到下一層。如果攻擊者在這些中間層的輸出上做手腳,模型的表現將會變得極為混亂。
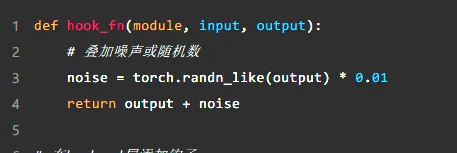
一種常見的方式是向模型的某些層(例如 lm_head)加入勾點函數,疊加隨機數或雜訊。這種「微調」看起來不起眼,但由於大模型的自回歸特性,早期層的微小擾動會在模型後續的輸出中被逐漸放大,最終導致模型產生「幻覺」,生成錯誤甚至荒謬的結果。
範例:在輸出層添加勾點
在沒有勾點之前,模型可能會輸出正確的預測結果。然而,加入勾點並疊加隨機雜訊後,輸出結果可能逐步偏離正常軌域:
經過這樣的篡改,模型在訓練過程中就會逐漸偏離正軌,生成大量錯誤的預測。特別是在超大規模自回歸模型中,這樣的擾亂會隨著生成過程不斷放大,最終導致整個訓練數據無效。
加勾點前輸出結果:

加勾點後輸出結果:

2. 篡改最佳化器
最佳化器是模型訓練的核心模組,負責根據梯度更新模型參數。如果攻擊者能夠篡改最佳化器的行為,模型的訓練過程將變得極其不穩定,甚至根本無法收斂。
攻擊者可以透過修改最佳化器的 step 方法,加入延時或隨機清空梯度等操作,來偽造正常的訓練狀態。例如,以下程式碼透過簡單的延時操作拖慢了訓練過程,這不僅會增加訓練時間,還可能影響訓練的整體效果:

更嚴重的是,攻擊者可以透過隨機化梯度或參數,直接破壞模型的訓練行程。例如,清空最佳化器的梯度或隨機篡改參數值,都會使模型訓練陷入混亂,無法正常更新參數。
3. 篡改梯度方向
深度學習模型的訓練過程依賴於梯度下降法,透過不斷調整參數,使模型逐漸收斂到最優解。而梯度的方向正是參數更新的「指南針」,如果這個「指南針」被篡改,模型就會朝著錯誤的方向前進,訓練出的模型可能完全失效。
攻擊者可以透過修改梯度的方向來擾亂模型訓練。例如,簡單地反轉梯度方向就可以讓模型的參數朝著與預期相反的方向更新,使得模型無法收斂,甚至訓練出一個帶有後門的模型。

這種方式雖然隱蔽,但後果卻極其嚴重。模型不僅會訓練出錯誤的結果,甚至可以被設計成帶有特定行為的「後門模型」,在特定條件下生成攻擊者預期的輸出。
三、程式碼隱藏與對抗在 GPU 模型投毒的攻擊鏈條中,程式碼隱藏與對抗是攻擊者最隱蔽、最難防範的環節。透過巧妙地隱藏惡意程式碼,攻擊者可以長時間不被察覺,持續影響模型訓練,甚至在面對內部調查時,依然能夠「全身而退」。本章將揭示攻擊者是如何透過篡改庫檔、動態載入程式碼等手法,隱蔽地進行攻擊,以及如何對抗這些潛在威脅。
1. 篡改 site-packages 目錄:持久化「幽靈攻擊」
在 Python 環境下,site-packages 目錄存放著專案依賴的第三方庫(如 transformers、torch 等)。攻擊者可以透過篡改這些常用庫的程式碼,將惡意程式碼嵌入其中,達到持久化攻擊的目的。
由於這些庫被頻繁呼叫,攻擊者可以在庫的初始化程式碼或關鍵函數(如模型載入、最佳化器更新、梯度計算等)中加入惡意程式碼,每次庫被載入時,惡意程式碼都會悄無聲息地執行。這種方式不僅能保證攻擊的持續性,還十分隱蔽,因為開發者或運維人員通常不會頻繁審查這些已安裝的庫檔。
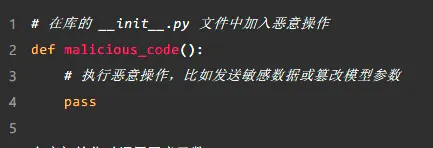
範例:篡改初始化程式碼
攻擊者可以在庫的初始化程式碼中插入惡意操作,並偽裝成正常的載入過程,難以被察覺。比如,以下程式碼展示了如何在庫載入時執行惡意程式碼:
這種篡改方式非常隱蔽,因為 site-packages 目錄下的檔往往不在日常的程式碼審查範圍內,攻擊者可以「潛伏」在系統中,悄悄執行惡意操作。
2. Python 執行時動態載入:無痕跡篡改核心函數
除了直接篡改 Python 庫檔,攻擊者還可以透過動態載入的方式,修改模型訓練中的關鍵函數(如 backward、step等),以便在不修改顯著程式碼的情況下,悄悄改變模型的訓練行為。
這種方法利用 Python 語言的動態特性,攻擊者可以在訓練框架初始化之前,提前註入程式碼,改變函數的返回值或行為。例如,攻擊者可以修改 backward函數,使得梯度計算出現偏差,或修改 step函數,幹擾最佳化器的正常更新。
範例:動態修改函數行為
以下程式碼展示了如何透過動態載入篡改模型的關鍵函數:

透過這種動態篡改,攻擊者可以在不直接修改程式碼檔的情況下,影響模型的訓練過程。這種方式尤為隱蔽,開發者可能在偵錯時發現不了任何異常。
3. 對抗內部調查
為了進一步隱藏惡意行為,攻擊者往往會為惡意程式碼設定特定的觸發條件,只有在特定情況下才會執行。例如,攻擊者可以設定只有當任務使用 256 張 GPU 時,惡意程式碼才會被觸發,這使得日常的小規模訓練任務不會檢測到任何異常。
此外,攻擊者可能會利用內部的偵錯工具或渠道,悄悄修改程式碼並隨時調整攻擊策略。比如,透過內部的 debug 群組,攻擊者可以即時監控訓練任務的進展,隨時修改惡意程式碼或增加新的觸發條件。這大大增加了內部調查的難度。
範例:設定觸發條件
攻擊者可以透過簡單的條件判斷,控制惡意程式碼的觸發時機:
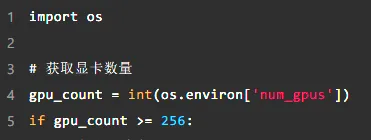
這種方式讓惡意程式碼在大多數情況下處於「休眠」狀態,只有在特定條件滿足時才會執行,進一步增加了調查和排查的難度。最後
最後預測一下某字節的攻擊手法:推測是基於其公司內部 AI 訓練平台正常員工許可權,利用訓練元件漏洞執行了惡意程式碼,並進一步篡改模型輸出、最佳化器與修改梯度方向實作來擾亂 GPU 集群中的模型訓練結果,同時由於該內鬼員工還進行了隱藏與持續修改程式碼等對抗操作,導致了其公司在較長時間後才調查清楚。











