夢晨 發自 凹非寺
量子位 | 公眾號 QbitAI
蘋果一出手, 在手機等流動通訊器材上部署大模型 不可避免地成為行業關註焦點。
然而,目前在流動通訊器材上執行的模型相對較小(蘋果的是3B,谷歌的是2B) ,並且消耗大量記憶體,這在很大程度上限制了其套用場景。
即使是蘋果,目前也需要與OpenAI合作,透過將雲端GPT-4o大模型嵌入到作業系統中來提供能力更強的服務。
這樣一來,蘋果的混合方案引起了非常多 關於數據私密的討論和爭議,甚至馬斯克都下場討論 。
如果蘋果在作業系統層面整合OpenAI,那麽蘋果器材將被禁止在我的公司使用。這是不可接受的安全違規行為。

既然終端側本地部署大模型的方案既讓手機使用者享受到AI強大的智能,又能保護好自己的私密安全,為什麽蘋果還要冒著侵犯私密的風險選擇聯手OpenAI采用雲端大模型呢?主要挑戰有兩點:
為了解決上述挑戰,上海交大IPADS實驗室推出了面向手機的大模型推理引擎(目前論文已在arxiv公開) : PowerInfer-2.0 。
PowerInfer-2.0能夠在記憶體有限的智能電話上實作快速推理,讓Mixtral 47B模型在手機上達到 11 tokens/s 的速度。
與熱門開源推理框架llama.cpp相比,PowerInfer-2.0的 推理加速比平均達到25倍,最高達29倍 。
為了充分釋放出PowerInfer-2.0框架的最大潛力,上海交大團隊還提出了配套的大模型最佳化技術 Turbo Sparse ,相關論文近期也上傳了arxiv,並且已經在業內引起關註。

另外值得一提的是,去年底上海交大團隊提出了針對PC場景的快速推理框架PowerInfer-1.0,在4090等消費級顯卡的硬件上,實作了比llama.cpp高達11倍的推理加速,曾連續三天登頂GitHub趨勢榜,5天獲得了5k的GitHub star,目前已達到7.1k star。
相比PC,手機的記憶體和算力受到的約束更多,那麽這次的PowerInfer-2.0是如何針對手機場景加速大模型推理呢?
動態神經元緩存
首先,針對手機執行記憶體(DRAM) 不足的問題,PowerInfer-2.0利用了稀疏模型推理時的一個特點: 每次只需要啟用一小部份神經元,即「稀疏啟用」。 沒有被啟用的神經元即使不參與AI模型的推理計算,也不會對模型的輸出質素造成影響。
稀疏啟用為降低模型推理的記憶體使用創造了新的機會。為了充分利用稀疏啟用的特性,PowerInfer-2.0把 整個神經網絡中的神經元分成了冷、熱兩種 ,並在記憶體中基於LRU策略維護了一個神經元緩存池。
近期頻繁啟用的」熱神經元」被放置在執行記憶體中,而「冷神經元」只有在被預測啟用的時候,才會被拉進記憶體,大幅降低了記憶體使用量。
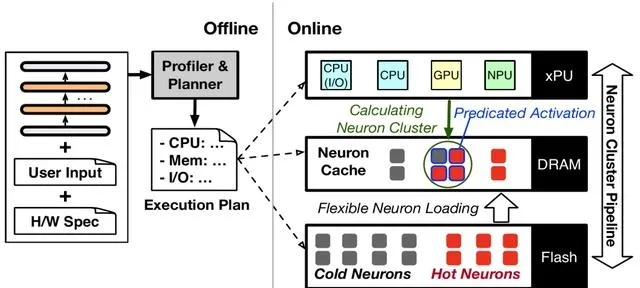
其實冷熱神經元分類,是繼承自PowerInfer-1.0已有的做法。
而在去年12月,蘋果在面向端側的大語言模型推理方案「LLM in a Flash」中提出了和神經元緩存類似的「滑動視窗」技術。但這些工作主要針對的都是PC環境,直接遷移到手機環境,還會遇到新的難題。
首先手機平台的硬件條件遠不及PC,無論是算力、記憶體總量還是儲存頻寬,都與PC存在較大差距。
其次,手機硬件平台存在 CPU、GPU、NPU三種異構的計算單元 ,十分復雜。各大硬件平台宣發時都會強調一個總算力,實際上是把CPU、GPU、NPU提供的算力加起來。然而真正跑起大模型來,能不能高效利用各種異構算力還是個問題。
以神經元簇為粒度的異構計算
針對這一點,PowerInfer-2.0進一步 把粗粒度的大矩陣計算分解成細粒度的「神經元簇」 。
每個神經元簇可以包含若幹個參與計算的神經元。對於不同的處理器,會 根據處理器的特性來動態決定劃分出來的神經元簇的大小 。
例如,NPU擅長於做大矩陣的計算,那麽可以把所有神經元合並成一個大的神經元簇,一起交給NPU計算,這樣就可以充分利用NPU的計算能力。而在使用CPU時,可以拆出多個細粒度的神經元簇,分發給多個CPU核心一起計算。
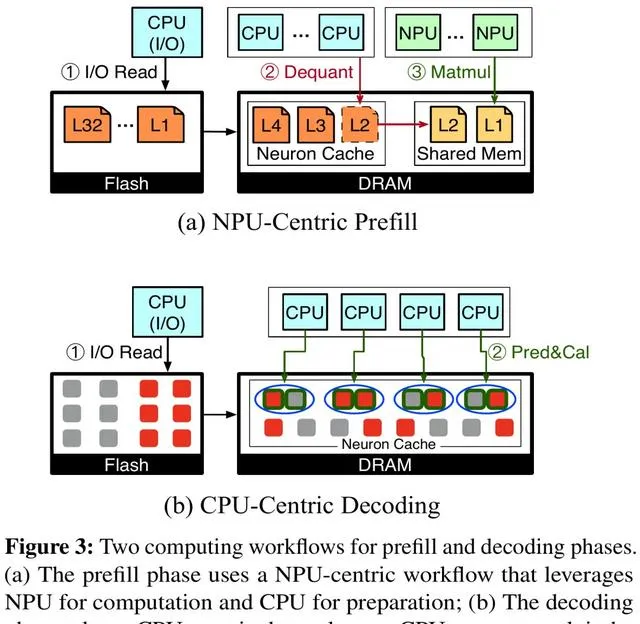
具體而言,PowerInfer-2.0為模型推理的 預填充階段 (Prefill) 和 解碼階段 (Decoding) 分別設計了兩套神經元簇的劃分方案:
預填充階段會一次性輸入很多token,基本上絕大部份神經元都會被啟用,因此選擇使用大神經元簇交給NPU計算。CPU此時也沒有閑著,在後台為NPU執行反量化模型權重的操作。
解碼階段每次只有一個token,具有較高的稀疏性,因此更加適合劃分成若幹細粒度的神經元簇,交給CPU靈活排程和執行計算。
神經元簇這一概念除了能夠更好的適應手機的異構計算環境,還能天然地支持計算與儲存I/O的流水線並列執行。
PowerInfer-2.0提出了 分段神經元緩存和神經元簇級的流水線技術 ,在一個神經元簇等待I/O的同時,可以及時地把另一個已經準備好的神經元簇排程到處理器上進行計算,從而充分隱藏了I/O的延遲。
同時,這種基於神經元簇的流水線打破了傳統推理引擎中逐矩陣計算的方式,可以允許來自不同參數矩陣的神經元簇交錯執行,達到最高的並列效率。

I/O載入神經元的速度對於模型推理也至關重要。
分段緩存會針對不同的權重類別采取不同策略(如註意力權重、預測器權重、前饋網絡權重) 采取不同的緩存策略, 提高緩存命中率,減少不必要的磁盤 I/O 。
緩存還會使用LRU替換演算法動態更新每個神經元的實際冷熱情況,確保緩存中放著的都是最熱的神經元。此外PowerInfer-2.0還針對 手機UFS 4.0儲存 的效能特點,設計了專門的模型儲存格式,提高讀取效能。
最後再來看一下實測成績,使用一加12和一加Ace 2兩款測試手機,在記憶體受限的情況下,PowerInfer-2.0的預填充速度都顯著高於llama.cpp與LLM in a Flash(簡稱「LLMFlash」) :
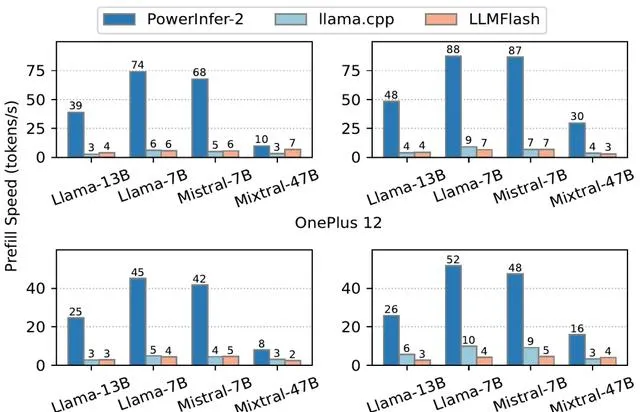
解碼階段同樣是PowerInfer-2.0占據很大優勢。特別是對於Mixtral 47B這樣的大模型,也能在手機上跑出11.68 tokens/s的速度:
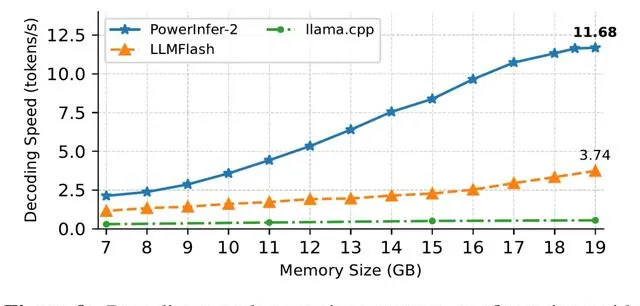
而對於Mistral 7B這種可以放進手機執行記憶體的模型,PowerInfer-2.0可以節約40%記憶體的情況下,達到與llama.cpp和MLC-LLM同水平甚至更快的解碼速度:

PowerInfer-2.0是一個模型-系統協同設計的方案,也就是需要模型中可預測稀疏性的配合。
如何以低成本的形式調整模型以適配PowerInfer-2.0框架,也是一個重大挑戰。
低成本高質素地大幅提升模型稀疏性
傳統簡單的ReLU稀疏化會給模型原本的能力造成不小的影響。
為了克服這個問題,上海交大IPADS聯合清華和上海人工智能實驗室提出一個低成本地稀疏化方法,不僅大幅提升模型的稀疏性,還能保持住模型原本的能力!

首先,論文深入分析了模型稀疏化中的問題:
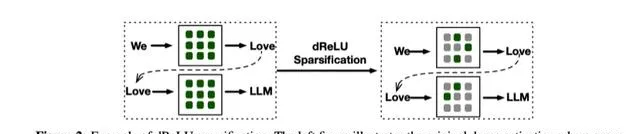
為了提升模型的稀疏度,論文在ReLU基礎上提出 dReLU啟用函數 ,采用替換原有啟用函數後繼續預訓練的方式增加模型稀疏性。
將SwiGLU替換為dReLU一方面直觀地提高了輸出值中的零元素比例,另一方面能更有效地在稀疏化的過程中復用原本模型訓練完成的gate和up矩陣權重。

為了克服模型能力下降的問題,團隊收集了包括網頁、程式碼和數學數據集在內的多樣化繼續訓練語料庫。 高質素、多樣化的訓練數據有助於模型在稀疏化後更好地保持和提升效能。
最後,團隊訓練了2個TurboSparse大模型進行驗證,分別是8x7B和7B的大模型。得益於高質素的繼續訓練語料,TurboSparse系列模型模型的 精度甚至還能反超原版模型 (具體見表6) 。
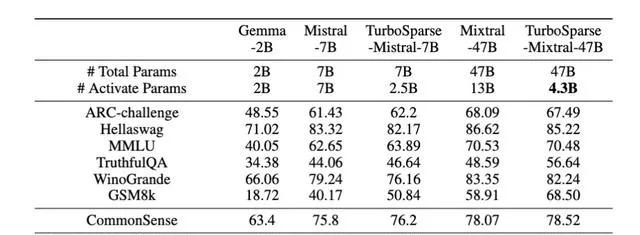
而在稀疏度方面效果也非常顯著。相比於原本的Mixtral模型需要啟用13B參數量,TurboSparse-Mixtral只需要啟用4.3B的參數量, 啟用的參數量是原本模型的三分之一 。
而關於稀疏化過程的成本問題,TurboSparse論文中介紹,改造過程中模型需要 繼續訓練150B tokens ,相比於預訓練(假設3T tokens) 還不到5%,說明其成本是很低的。
讓技術加速走出實驗室
從推理框架和改造模型兩個角度出發,上海交大團隊的成果實作了大語言模型在手機等資源受限場景下的快速推理。
而且這套方案的潛力不止於手機,未來在車載器材、智能家居等方向還有更多套用前景。
最後再正式介紹一下團隊。 上海交通大學並列與分布式系統研究所 (簡稱IPADS) ,由 陳海波教授 領導,現有13名教師,100多名學生。
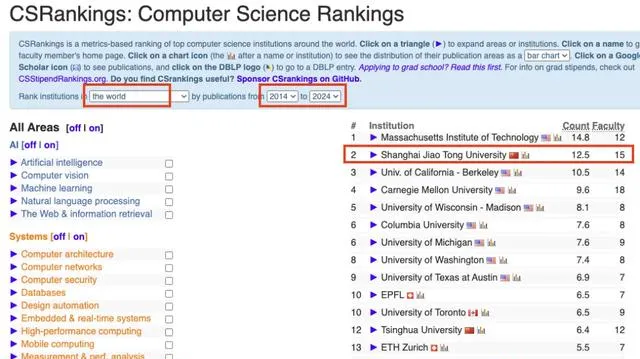
IPADS長期從事電腦系統的研究,近10年在權威榜單CSRankings的Operating Systems領域排名全球前二,僅次於MIT;上海交大也是排名前十中唯一上榜的亞洲高校。
目前,上海交大IPADS已經在Huggingface上開放了稀疏化的模型權重。在未來,如果PowerInfer-2.0能夠與手機廠商進一步緊密合作,相信可以加速相關技術走出實驗室,落地到各種真實場景。
PowerInfer-2論文:https://arxiv.org/abs/2406.06282
TurboSparse論文:https://arxiv.org/abs/2406.05955
模型權重:https://huggingface.co/PowerInfer/TurboSparse-Mixtral
— 完 —
量子位 QbitAI · 頭條號簽約
關註我們,第一時間獲知前沿科技動態











