專案背景
因此在工業上,對於手機行為的檢測需求日益增多,目前主要采用檢測進行手機的定位輔助分析。
本專案針對這一特點,實作思路如下:
利用PaddleX快速訓練輕量化檢測模型PP-YOLO Tiny,並透過一個辨識模型MobileNet進行檢測矯正。- 保證即時性的同時,也保證較高的精確度。
一、數據樣式(數據說明)
本專案的數據分為 檢測數據(8000張) 與 辨識數據(16683張) 兩類:
1.檢測數據
檢測數據位於數據集: 違規使用手機辨識.zip
解壓後,封包含在train.zip中,還需再次解壓數據,最後解壓完成後,數據如下:

最終用於訓練的檢測數據位於 0_phone 中,檢測數據格式為VOC 格式——可直接使用PaddleX進行數據劃分,並直接用於PPYOLO-Tiny模型的訓練。
用於檢測的數據在當前專案中僅僅包含 0_phone 下的數據,該數據均為包含手機的圖片,因此,後期專案訓練過程中,可以適當的添加1_no_phone 中的圖片作為背景圖片加入到模型的訓練數據中。

2.辨識數據
辨識數據位於數據集: recognize_phonedata.zip
解壓後,數據如下:

其中, 0_recognize_phone資料夾 中包含手機的辨識圖片,1_recognize_nophone 中包含非手機的辨識圖片。
辨識數據中的 0_recognize_phone資料夾圖片 均來自檢測數據中0_phone中標註的手機(裁剪)數據 ,而1_recognize_nophone資料夾圖片 均來自1_no_phone中隨機裁剪的數據 作為非手機的類別。

本專案中的非手機圖片數據集由 隨機裁剪 獲得,受限於原始1_no_phone中存在一些大小不均勻的圖片,因此固定大小尺寸進行裁剪後,有的非手機圖片為人或者衣服等。
但按照該辨識數據集,對於該任務已經有了一個不錯的提高——後期透過完善辨識模型的數據以及泛化精度的提高,將更好的提升該串聯方案的效果。
二、模型選擇(套用場景考慮)
考慮到工業套用上,通常要求即時性與部署成本的問題,選擇輕量化化檢測模型PP-YOLO Tiny作為檢測模型——同時,為了保證一個手機辨識的較高準確率,訓練一個辨識是否為手機的辨識模型,對檢測後的目標進行二次辨識,保證檢測的準確性。
因此,模型的架構為: PP-YOLO Tiny(目標檢測) + MobileNet(影像辨識)

之所以外加MobileNet作為精度提升的一個元件,是因為PP-YOLO Tiny在追求輕量化時,骨幹網絡相對較弱,在辨識精度上有一定的錯誤率(可能來源骨幹網絡辨識能力不夠,也可能因為定位能力不夠導致辨識受影響);
三、模型訓練
首先下載PaddleX2.0用於後期的專案開發。
pycocotools: 是為了提供COCO數據集的載入功能——以輔助Paddlex實作數據的自動劃分、數據格式轉換等

(3)載入數據
https://github.com/PaddlePaddle/PaddleX/blob/release/2.0.0/docs/apis/transforms/transforms.md
train_transform:
VOC格式數據自動載入介面


(4)生成檢測模型的anchors
由於不同的數據集的套用場景等不同,因此模型在使用時,往往針對特定數據進行anchor的聚類生成會更容易擬合數據集。
一般來說,聚類後的anchors僅適用於訓練時特定的大小,部署時不宜改動,否則精度損失較大

(5)訓練模型

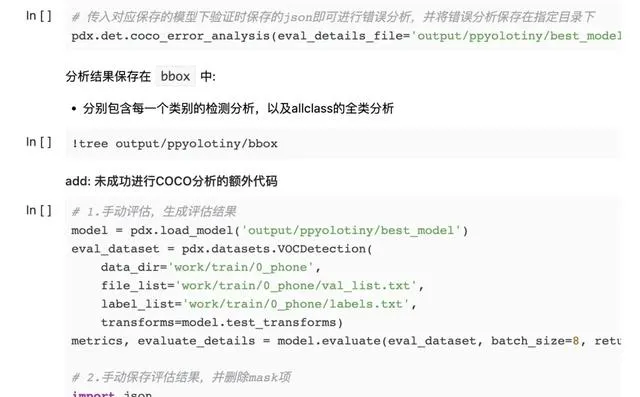
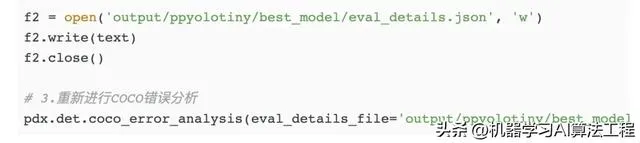
(6)模型錯誤分析——COCO錯誤分析
如果直接執行coco_error_analysis失效(及以下程式碼),可手動重新生成json再進行分析(後續程式碼)

(7)檢測視覺化
用於展示模型檢測效果




五、PaddleX-SDK串聯部署
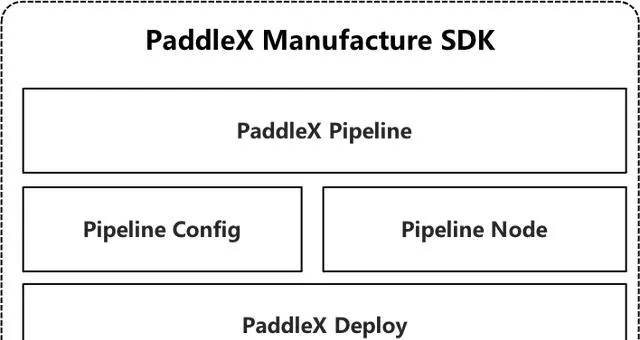
SDK 是指:
PaddleX Manufacture 基於PaddleX-Deploy 的端到端高效能部署能力,將套用深度學習模型的業務邏輯抽象成Pipeline ,而接入深度學習模型前的數據前處理、模型預測、模型串聯時的中間結果處理等操作都對應於Pipeline中的節點PipelineNode,使用者只需在Pipeline配置檔中編排好各節點的前後關系,就可以給Pipeline發送數據並快速地獲取相應的推理結果。
以PaddleX匯出後的單一檢測模型(無數據前處理、無中間結果處理)為例,配置好流程配置檔後使用簡單幾行程式碼就可以完成預測:
而對於本專案的SDK部署不再采用 單模型的Pipeline ,而是透過SDK實作更便捷的模型串聯——即多模型Pipeline 。
檢測+辨識的模型部署串聯Pipeline
在測試時,請註意使用存在目標的圖片進行串聯測試——因為當前SDK版本下,檢測與辨識串聯時,如果檢測無目標,在傳入辨識模型時會報錯終止。
檢測與分割串聯時,如檢測無目標,傳入分割模型不會報錯終止!
節點相關內容可參考下圖
2.節點表











