前言
自從 Llama3 模型釋出以來,它在多個領域引起了極大的關註,並激發了眾多基於該模型的演示應用程式的開發。這些應用程式的表現和效果不僅依賴於 Llama3 模型自身的對話能力、邏輯推理和上下文理解等核心特性,而且在實際部署和執行中,它們的表現也極大地受到計算資源的制約。
在現實世界的套用場景中,一定規模的語言模型,尤其是像 Llama3 這樣復雜的模型,需要大量的計算資源來支持其執行。這包括但不限於處理能力(CPU 或 GPU)、記憶體、儲存空間以及網絡頻寬。訓練一個規模較大的模型,尤其是在深度學習和自然語言處理領域,不可避免地會對這些計算資源提出巨大的需求。
這種對計算資源的高需求不僅增加了經濟成本,也帶來了一系列工程上的挑戰。例如,為了有效地訓練和部署這些模型,需要設計高效的演算法來最佳化資源使用,開發更強大的硬件加速器,以及構建更健壯的分布式計算系統。此外,還需要考慮模型的可延伸性和容錯性,確保在面對硬件故障或其他意外情況時,模型的訓練和套用不會受到太大影響。
測試指標
我們選擇了在 LLM 推理領域炙手可熱的 4090 作為平台,對 Llama3 在 4090 上的表現進行了詳細的測試。
透過控制變量法,以輸入/輸出長度作為變量,測試 Llama3 在 4090 平台執行時的延時與總吞吐量,以及 QPS 和耗時。
測試結果
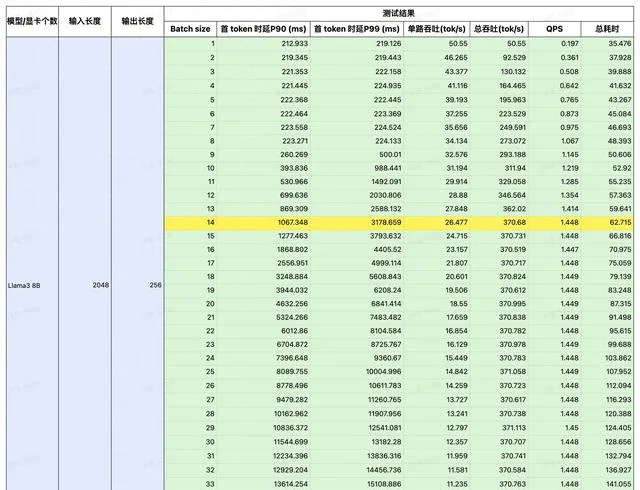
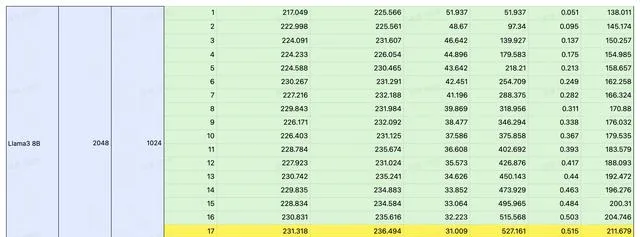
註:黃色部份為效能極限,在此基礎上若再增加並行,吞吐量也不會提升。若想獲取更詳細的數據,請掃碼聯系。
總結
經過測試,我們將 Llama3 8B 在 4090 平台上的表現總結成這一張圖。可以看到在不同 IO 場景下,Llama3 QPS 的極限如何。

掃描下方二維碼,立即試用~












