
今年5月的一場釋出會上,火山引擎總裁譚待表示,「豆包比行業價格低了99.3%,大模型從此以厘計價」。
對於人工智能產業而言,這實際上釋放了一個明顯訊號——隨著基礎設施成本下降,套用爆發期即將來臨。
深度學習泰鬥吳恩達曾在一次公開演講中表示,AI是一系列工具的集合。這些工具包括了監督學習、非監督學習、強化學習,以及現在的生成式人工智能—— 它們 都是通用技術,意味著 AI 與電力 、 互聯網等其他通用技術,並沒有什麽區別。
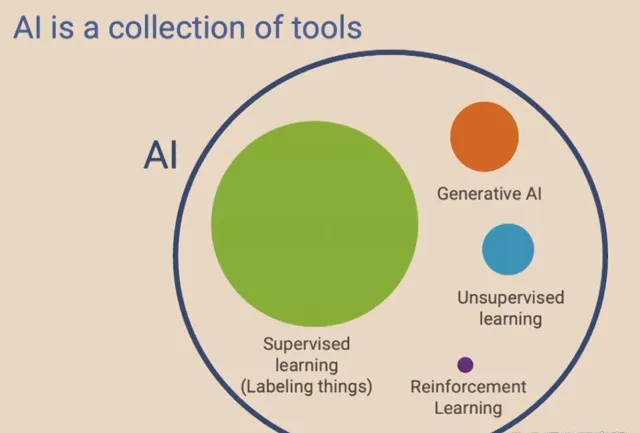
電力本身並沒有創造價值,但它驅動了電燈、冰箱和空調,後者誕生的基礎是低廉的電力成本。與之對應,把大模型看作電力,它的繁榮取決於能夠帶動多少下遊的套用,組成一個生機勃勃的生態。
如果一定要用一個指標衡量生態的繁榮程度,那顯然不是模型本身的參數和效能,而是什麽樣的人在呼叫它,有多少人正在使用它。
在8月21日舉辦的火山引擎AI創新巡展上公布的數據顯示,最新版豆包大語言模型的綜合能力相比三個月前首次釋出時提升了20.3%,同時日均Tokens使用量超過5000億,釋出2個月以來,平均每家企業客戶日均Tokens使用量增長了22倍,是國內使用量最大的大模型之一。

每一次API呼叫,都是在為技術大廈添磚加瓦,逐步搭建出豐富多樣的套用樓宇。
套用之辯
金沙江創投朱嘯虎曾在朋友圈吐槽: 「當年看不起(互聯網的)商業模式創新,覺得沒有壁壘:百團大戰、百車大戰、百播大戰;沒想到硬科技大模型創業,依然是百模大戰...」
這種對商業化有著執著信仰的投資人被稱作是「市場派」,而在他的另一邊,則是高舉scaling law大旗的技術派,其信條是人工智能的市場會隨著模型能力的飛躍而自然形成,更應該不計成本的投入模型的訓練。
這場爭論背後的分歧,也在谷歌和國內大模型的更新頻率中體現。
今年2月,谷歌推出了Gemini1.0、Gemini Advanced、Gemini 1.5 pro、Gemma、Genie一系列模型,還有一堆Ultra、Pro、Nano這種不同參數量的版本,不光看的使用者眼花繚亂,谷歌員工看著既熟悉又陌生的大模型軍團,也難免迷惑。

中國公司自然也不遑多讓,各家大模型在參數和排名上輪番打破紀錄,聊天繪畫和吟詩作對無所不能。但高頻更新的模型能力,和大規模商業化套用場景之間的落差,就構成了紅杉研報中一連串的數據:
全球的科技公司每年預計將花費2000億美元,用於大模型基礎設施建設,相比之下,大模型每年最多只能產生750億美元的收入,中間存在著至少1250億美元的缺口。
國聯證券統計A股上市公司2023年財報顯示,AIGC整體滲透率不足20%,在超過一半的一級行業滲透率不到10%[1],由此帶來了諸多類似「朱嘯虎之問」的爭論與質疑。
種種爭論與質疑往往會被引向對大模型價值的懷疑,但事實上,對模型效能的追逐,與套用和商業化的成長並不矛盾。
舉例來說,iPhone並非第一台觸屏手機,蘋果真正的開創性是基於「觸摸」這個場景,開發了一系列互動方式。而輕觸式熒幕的分辨率、感應精度等指標,與觸控操作並不矛盾,反而相輔相成。
與之對應,模型本身的能力與套用的落地也不是非黑即白。橫空出世的ChatGPT既是GPT模型效能的體現,也是OpenAI的產品團隊基於「聊天」這個場景的產品化能力。
只不過,面對各行各業細分又復雜的需求,大模型的套用很難用程式碼推匯出來,只能躬身入局,深入具體的業務場景。
有了這個背景,便不難理解火山引擎牽頭搭建包括零售、汽車、智能終端等行業大模型生態聯盟的用意。其核心思路在於,讓一部份企業先將大模型嵌入業務場景,在這個過程中,探索各行各業融入AI的參考教材。
換句話說, 豆包把握企業需求的方式, 嘗試 和企業使用者一起去探索未來更新方向。
從零售開始,到千行百業去
零售行業最顯著的特點是非標。相比高度標準化的生產環節,零售存在大量的非標環節,比如商品組合設計、直播數據復盤、售後服務響應等等。同時,零售行業雖然資訊化/數碼化底子不俗,但智能化空間依然很大。
真實的銷售場景中,促成消費者「購買」動作的核心要素很多時候是「說不清道不明」的,單純的數碼化工具,很難學會用「嘮家常」、「喚起共情」來賣產品。但這恰恰是大模型與智能化能夠滲透的業務空間。
一套經典培訓話術
零售大模型生態聯盟成立的背景,一方面是零售業借助AI提升經營效率,在存量中創造增量;另一方面對豆包和火山引擎來說,這也是與行業夥伴協同探索業內真實需求,以進一步完善豆包服務能力的機會。
截至目前,零售大模型生態聯盟釋出了七種核心解決方案,基本覆蓋零售行業「人、場、貨」三大核心要素。
「人」指消費者需求,解決方案包括: VOC ,多維度挖掘消費者需求,洞察流失原因; 零售客服質檢, 實作全量智能質檢和即時預警,統一服務標準,對所有會話進行智能監控,一旦發現異常,立即標記並告警。
「場」指渠道以及銷售場景(比如直播),解決方案包括: 零售客服陪練, 模擬買家與客服的對話,加快客服水平提升速度; 練播房, 教-學-練-考-評全面融入豆包大模型,提升主播帶貨水平; 直播洞察, 結合抖店授權精準數據,輔以豆包大模型及抖音同源的技術復盤歸因,提升抖音直播間表現。
「貨」指產品及服務,也被認為是三大要素中,AI附加值最高的環節。
以豆包大模型為基礎的 商城導購助手, 可以實作 會籍知識問答、大模型推薦商品資訊列表、基於購物偏好購買清單、基於購物清單給出商品連結、智能回復 等核心場景,提高顧客的體驗和滿意度。
在一系列解決方案中,不難看出火山引擎在其中扮演的角色:
一是將一些非標的環節盡可能標準化。比如售後服務和直播復盤歸因,大量數據歸集、指標篩選的「Excel式」工作可以交由大模型完成,將人的決策能力釋放出來。二是在數碼化的基礎上智能化,比如直播洞察、企業商品知識庫這類套用,本質上利用的是大模型對非標數據的處理能力。
在與零售行業的合作中,豆包扮演的其實是一個「修鐵路」的角色——即針對行業的需求,針對性開發一系列作為基礎設施的套用,並在實際的行業套用過程中逐漸去粗取精。
在零售之外,火山引擎的工具箱正在一個又一個行業中復制。
今年5月,火山引擎正式釋出「汽車大模型生態聯盟」,成員除了吉利、長城、一汽紅旗、東風本田、智己等車企外,還包括中國電動汽車百人會等行業組織,同時最新入會成員包括領克、吉利銀河、上汽榮威、上汽名爵等。
在本月火山引擎與梅賽德斯-奔馳的合作中,可以窺見前者扮演的角色——提升智艙資訊檢索能力、提升智艙系統反應速度、擴充套件智能套用場景等。
在與領克汽車的合作中,在豆包大模型幫助下,領克實作了智慧邀約坐席、AI 對練&內訓、AI 銷售助手、智慧經營報表以及 AI 用車說明書等多項基於模型能力的功能。
除此之外,在教育、金融、遊戲、智能終端等行業,大模型套用也取得積極進展。
比如在教育領域,據浙江大學求是特聘教授、資訊科技中心主任陳文智介紹,在自研 OpenBuddy 模型,以及豆包大模型等極具性價比的營運模式及智能體的共同賦能下,浙大建立了「浙大先生」智能體套用開發平台,並搭建了AI科學家、慧學外語、AI百事通、數碼教師等多個大模型校園套用場景。
在大模型的參數指標不斷突破極限的同時,它的套用案例,也在一個又一個常被忽視的業務場景中不斷積累。
從科學到商業
SuperCLUE在今年4月釋出的【中文大模型基準測評報告】中,將豆包大模型劃入了「實用主義者」象限[3],點出了豆包大模型區別於國內許多大模型的特質: 更加重視實用性。
大模型的效能和參數,更多是一種學術意義的指標,但讓各行各業用上大模型,則是一個有關成本、效率和價值的商業問題。
從學術角度看,生成式AI的終極目標是一個超級模型解決所有問題。但放在具體的商業套用中,顯然更看重模型與業務的適配,這也是火山引擎在通用模型之外,針對細分場景開發專用模型的核心因素。
今年的春季火山引擎FORCE原動力大會上,字節跳動釋出了豆包模型家族,包含大語言模型、語音模型、視覺模型等九大模型,到今年7月,家族又迎來新成員豆包圖生圖模型,為更細分的需求進行了針對性開發。
在8月21日的創新巡展上,豆包再次宣布重磅更新,效能方面,豆包大模型在角色扮演、語言理解、長文任務、數學等維度,綜合能力提升20.3%。

在垂類模型方面,比如語音辨識模型,在辨識率上,與國內公開釋出的語音辨識大模型相比,錯誤率降低了 10%-40%;在上下文感知上,帶來超過15%的召回率提升;同時在保持高準確率後,豆包語音辨識支持包括上海話、粵語、四川話、陜西話、閩南語等方言辨識。
語音合成模型重點升級了 流式語音合成能力 , 即時生成語音,讓大模型「邊想邊說」,接近人類語音互動方式,大模型理解文本語意和情感的能力的升級,實作精準斷句,同時有26種超自然音色可供選擇。
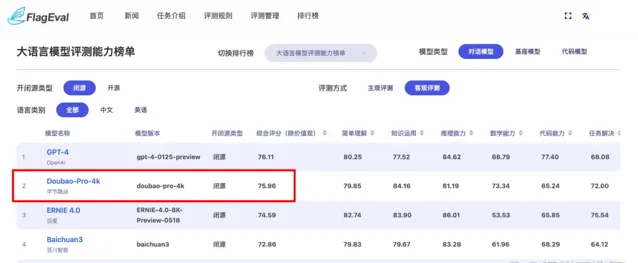
FlagEval6月釋出的評測榜單顯示,在閉源大模型的「客觀評測」中,豆包大模型以綜合評分75.96分排名國產大模型第一。
在模型落地環節,火山引擎推出了火山方舟、扣子專業版、HiAgent等一系列平台和工具。以火山方舟為例,企業可以透過火山方舟進行模型精調、推理、評測等,也可以透過豐富的外掛程式生態,進行AI原生套用開發。
扣子是「工具箱」諸多套用中非常出圈的,其本質是「低程式碼」構建AI Bot,使用者不懂編程知識也可以構建各種AI Bot,並釋出到市集,還能分享到豆包、微信、飛書等平台。
扣子專業版主要面向企業需求,在原版基礎上提供了企業級SLA和多種高級特性,使AI套用更易落地,驅動業務增長。
HiAgent則是企業專屬的AI套用創新平台,高度適配企業個人化需求,企業業務人員可以像搭積木一樣低程式碼搭建智能體,讓業務創新不受生產技能的限制。
一系列高強度開發的目的,就是從價格到易用性等多個方面,全面降低模型的使用排程成本。
在承載力方面, 豆包提供了業內最高標準的初始 TPM (每分鐘Tokens)和 RPM (每分鐘請求數),每分鐘處理Tokens限額最高可達同梯隊模型數倍。
而在價格上, 在各家 大模型 最強版本價格對比中,豆包比行業價格低98%以上。
在解決了成本問題後,大模型落地到行業內的難題,就只剩下大模型與企業的協同。換句話說,就是模型要「懂」行業。
何為「懂」?法律條文教育出的大模型會在法考中拿高分或是提供法律條文註釋,但更多案件例項的投餵和專業律師不斷反饋的意見,才能「培養」出一個AI律師。在更多行業,一些「只可意會不可言傳」的know-how,需要大模型公司與行業更多的協作和磨合。
對大模型企業來說,這就不僅要求其本身有足夠強的「技術能力」,更依賴在無數行業實踐中積累的「工程能力」。火山引擎大神雲集的研發團隊常被輿論提及,但其多年的成功實踐中,不斷完善的「工程能力」,同樣舉足輕重。
從零售大模型生態聯盟到汽車大模型生態聯盟,再到火山引擎與多家頭部智能終端廠商一同成立的智能終端大模型聯盟,一個個行業的智能化重塑和人工智能真正的革命性,正在這些行業落地中一點點展露。
尾聲
AIGC產業的評價體系向來和數碼強相關,去年是各大參數效能,今年則是各大公司的盈虧額。
上個月,行業媒體the Information發表長文【How does OpenAI Survive】,估算OpenAI今年的營運虧損將到50億美元。這意味著柯曼的化緣之路尚且漫漫,短時間內看不到盡頭。
OpenAI的最大競爭對手Anthropic情況也不好。今年早些時候,公司高管曾預測,2024年的年化收入在與亞馬遜分成後在4億美元到6億美元之間,但同時全年耗費資金將達到27億美元。
這似乎進一步驗證了一個歷史規律:技術革命的最大受益者,通常不是率先做出突破的拓荒者,而是那些率先將技術擴散出去的一方。
中國有句老話叫「要想富先修路」,AI時代,技術與實際生產生活的融合迎來全新的高度,也給「修路」帶來了新的挑戰。
超級工程向來不是拔地而起,技術的變革總是厚積薄發。今天,火山引擎通車了高速公路的一條快車道。

參考資料
[1] 千家公司年報,看AI在A股的「滲透率」,國聯證券
[2] Andrew Ng: Opportunities in AI - 2023,Stanford Online
[3] 中文大模型基準測評2024年度4月報告,SuperCLUE
作者:何律衡
編輯:張澤一
視覺設計:疏睿
責任編輯:張澤一











