塞拉菲姆·巴特佐格魯(Serafim Batzoglou)覺得,許錦波應該共享2024年的諾貝爾化學獎。
他轉發了諾貝爾化學獎的貼文並評價說,「並不是要否定哈薩比斯、朱默帕和貝克的貢獻,但還有一個人本應得到諾貝爾獎的認可,那個人就是許錦波。他第一個開發出(精準預測蛋白結構)的深度學習演算法,這一演算法後來被復現和增強到最初版本的AlphaFold中。他本應與哈薩比斯一起獲得諾獎。」

推文截圖
巴特佐格魯是計算基因組學專家,國際計算生物學會會士,曾任史丹福大學電腦教授。
同樣認可許錦波貢獻的另一個行內人,是全球蛋白質結構預測比賽(CASP)的創辦者、馬里蘭大學教授約翰·莫爾特(John Moult)。莫爾特說,「DeepMind這項工作(AlphaFold)背後的概念和方法,並非憑空而來,關鍵技術是深度學習方法的套用。毫無疑問,DeepMind直接建立在許錦波的工作之上。」
CASP號稱蛋白質結構預測的「奧林匹克賽」。後來獲得諾獎的AlphaFold,就是在2018年的第十三屆CASP比賽上初露頭角。再往前推一屆,在第十二屆CASP比賽裏脫穎而出的,正是許錦波的RaptorX-Contact演算法。事實上,第十三屆裏排名靠前的團隊,都用了類似許錦波的演算法。
對許錦波來說,諾獎頒給AI預測蛋白質結構,只是一個開始。他現在專註的,是正在爆發的新領域——AI設計和最佳化蛋白質。
什麽是蛋白質結構預測?
許錦波覺得,自己是個單執行緒的人。
電腦的CPU可以同時執行很多工,但許錦波在一個時間段,只想一個問題。雖然是急性子,但面對難題時,他反而能沈下心來,花很多時間,翻來覆去地琢磨,把問題想深、想透——這又有點像他研究的AI,很多層神經網絡聯合起來,去捕捉數據裏浮現出的復雜模式,最後出色地完成任務。
高中時,許錦波是全國高中數學聯賽的江西組別第一名。大學時,他去了中國科學技術大學的電腦系。博士階段,他出國深造,求教於演算法和現代消息理論的頂級專家李明教授門下。
那是2001年,人類基因組計劃正如火如荼。李明教授也正在思考與之相關的兩個大問題:第一,當時測序技術還不夠好,沒法把一整個染色體直接從頭測到尾,只能切成小碎片來測,電腦怎麽才能快速把一大堆小片段正確拼成完整的基因組?第二,當時的電腦速度也比較慢,用常規方法來分析基因組,可能要花上好幾年時間。怎麽才能快速對比兩個巨大的基因組,找出裏面相似的同源基因,以及不同的變異之處?
當時的研究者、資金、註意力,都集中在DNA和基因組上。不過,許錦波和李明教授討論後,卻選了一個很難的博士課題——蛋白質的結構預測。
蛋白質結構預測,一個60年難題
選這個課題,有兩個原因:第一,它很重要,研究界渴望知道這個問題的答案,且短時間內不可能被其他科研組徹底解決,非常適合作為博士課題。第二,它很困難,這是個被清晰定義的問題——已知蛋白質的序列,也就是胺基酸在一維上的排列順序,要預測出整個蛋白質裏面每個原子的三維座標。這個問題橫亙六十年,進展始終不大,許錦波好奇,自己能不能把這個問題的邊界,向前推進一點點。

許錦波演講【AI預測蛋白質結構,但這只是一個開始】丨我是科學家
蛋白質是什麽?它是細胞中最豐富的生物大分子。生物學的中心法則是,遺傳資訊從DNA流向RNA,又從RNA流向蛋白質。
假如把一個生物體想象成一家工廠,那麽DNA就是最原始的設計藍圖;RNA是根據設計藍圖復寫而來的很多本操作手冊,每本手冊裏包含了制造某個特定產品的具體步驟;而蛋白質則是一個個最終的產品,是工廠的梁柱、門窗以及千形萬狀的結構,是工廠裏自動執行各種功能的「分子機器」。
有些蛋白質是結構性的,有些蛋白質是功能性的。結構性的蛋白質組成生物的身體——頭發和指甲裏的角蛋白,皮膚裏的膠原蛋白,肌肉纖維裏的肌球蛋白,血管裏的彈性蛋白。功能性的蛋白質推動生物體內的機能與反應——幫助消化吸收的澱粉酶、脂肪酶,控制血糖的胰島素,運輸氧氣的血紅蛋白,儲存鐵的鐵蛋白,傳遞訊號的神經遞質……
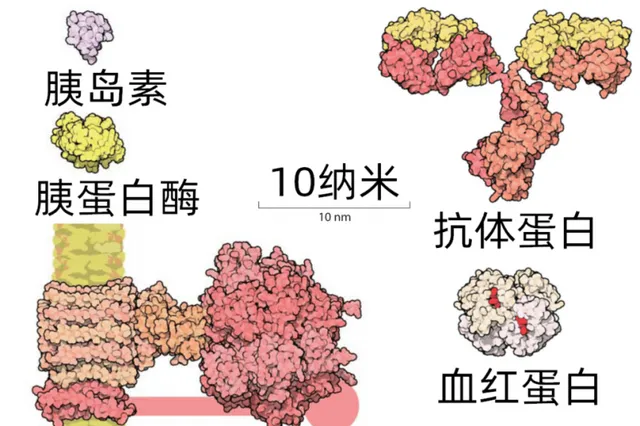
一些蛋白質的大小對比 。蛋白質分子的直徑經常也就幾納米或者幾十納米,胰島素只有51個胺基酸;助消化的胰蛋白酶有281個胺基酸;運氧氣的血紅蛋白有574個胺基酸;再大一點的有免疫系統用來對抗細菌病毒的抗體蛋白(1316個胺基酸),以及線粒體裏提供能量的ATP合成酶(1125個胺基酸)。
蛋白質是由胺基酸構成的。想象一下,你有20種不同形狀和顏色的柔性積木,每種積木可以無限量供應,那就是生物合成蛋白質所普遍使用的20種胺基酸。你能用這些積木搭出的不同形狀,就相當於蛋白質的不同結構。
什麽是蛋白質結構預測?簡單點說,就是已經知道蛋白質用了哪些「胺基酸積木」,知道這些積木誰和誰接在了一起,這些積木在相連後依然可以進行一定的旋轉和移動,那就是蛋白質裏胺基酸殘基的旋轉自由度,要猜出最後拼搭出的形狀。
所有可能的形狀組合,是一個超出日常經驗、以至於難以想象的天文數碼。
舉個例子,假如只是一個用了100塊積木的模型,每個積木和其他積木相連時只有2種不同的拼法,那麽所有可能的形狀組合,就是2的100次方,也就是1.27×1030種。
這個數碼有多大呢?假設有台超級電腦,每秒能算1億種不同的形狀。它把這2100種形狀算一遍,需要4 ×1014年——宇宙誕生至今也就138億年,這個時間足夠宇宙反復誕生29128次。
問題很難,但單執行緒的許錦波依然決定走上蛋白質結構預測這條單行道。這條路,他一走就是24年。
RaptorX演算法誕生,啟發AlphaFold
最開始,許錦波想的是改進當時的主流方法——「能量最佳化」法。
一顆球放在山頂上,輕輕一碰,就會滾到山腳,這就是自然地從「能量高的狀態」轉變為「能量低的狀態」。
對於蛋白質分子來說,科學家也猜測裏面的所有原子會自然地找到能量最低的穩定狀態,那就是蛋白質最後折疊出的結構。
「能量最佳化」法就是這個原理。但「能量最佳化」的問題在於,預測比較小的分子時還好,但分子越大越復雜,得出的結果就會越差。
蛋白質平均會用到幾百個胺基酸,由幾千幾萬個原子組成,結構的可能性迅速增長到天文數碼,找出「最優能量」幾乎是個不可能的任務。事實也證明,與結構生物學家做實驗解出的結構相比,「能量最佳化法」預測出的結構始終誤差較大。
機器學習與深度學習登場
從2006年開始,許錦波逐步轉向新興的機器學習和深度學習方法。

如果說「能量最佳化」還大量依賴於人去手把手指導電腦,那麽機器學習和深度學習就開始鼓勵電腦「自學」了,當然,這種「自學」仍然需要人類的演算法和策略指導。電腦分析已知的蛋白質序列和結構,自己去發現其中蘊藏的規律,然後據此再去預測一個未知蛋白的結構。
相比「能量最佳化」,「機器學習」和「深度學習」無疑是一種顛覆。就像人的大腦可以在極端復雜的環境裏磨煉自己的直覺和反應,電腦也可以透過訓練來不斷改進自己的能力,可以處理混亂的、殘缺的、不完美的資訊。
唯一的問題是,結果還是不夠好,預測出的結構,誤差還是比較大。和老方法相比,提升幾乎可以忽略不計。
能試的路似乎都已經走到了盡頭。很多人開始離開蛋白質結構預測的這個領域,研究基金越來越少,參加CASP比賽的隊伍也越來越少。許錦波回憶說,「在2006年到2016年這10年間,大家都覺得這個問題沒辦法做出來,很多人都離開這個領域去做其他的問題了。
對許錦波來說,突破是在2016年到來的。
決定性突破:利用蛋白質的全域資訊
那個思考良久的問題,在大腦的層層神經回路裏來回碰撞、迴圈、激發,有一天,一個靈感忽然浮現。
「關鍵就是一點,要盡可能地用上蛋白質的全域資訊」,許錦波說,「之前的深度學習還是在使用局部資訊去預測。」
拿一個由300個胺基酸組成的蛋白質來說,以前的預測方法每次只關註某幾個位置的胺基酸資訊,比如第一個胺基酸、第十個胺基酸 或者第一百個胺基酸;也可能只關註某一個局部區域,比如第20個到第30個胺基酸……總之,關註的都是一些局部資訊。
許錦波的想法是,一定要讓AI把從第1到第300個胺基酸的全域資訊全用上,當然,難點就在怎麽收集這些全域資訊,「我盡可能用比較深的神經網絡去做,也是因為多層的網絡更能抓取到蛋白質的全域資訊,它是一個合適的工具。」
就像在玩一個難度極高的拼圖遊戲,許錦波耐心地訓練AI尋找線索:要看有哪些小碎片特別契合、經常一起出現(胺基酸的共前進演化);要對比分析,看哪些小碎片是從其他拼圖裏繼承來的(保守序列);要預測哪幾塊小碎片會互相接觸(胺基酸的接觸預測),任意兩塊碎片之間的距離是多長(胺基酸的相互作用強度);最後把所有資訊匯總成數學上的矩陣,又把矩陣轉換為影像,然後讓AI用辨識影像的方式去辨識「蛋白質全域資訊圖」
許錦波拿這個方法去預測了一個200多個胺基酸的膜蛋白結構,發現誤差只有2.29個埃,大概0.2納米,兩個原子的寬度。
為什麽選擇膜蛋白?許錦波說,「目前的實驗技術去解析膜蛋白結構是很困難的,所以數據庫裏就沒有太多的膜蛋白結構。以前的演算法也就沒有足夠的膜蛋白數據去用於訓練,所以在預測膜蛋白結構時往往會失效。但我的RaptorX演算法在不需要用膜蛋白數據去訓練的情況下,還可以把膜蛋白的結構預測得相當好。這就意味著RaptorX演算法不是依靠簡單地記住訓練數據,不是單純依賴相似的序列而推匯出相似的結構。而是它抓取全域資訊後真正學到了一些底層的規律,於是有了比較好的預測能力。」
那一刻,許錦波知道,這方法成了。

許錦波在芝加哥大學豐田技術研究所任教時,與芝加哥大學的師生多有交流合作。
新思路,啟發2024諾貝爾獎得主
2016年秋天,許錦波在芝加哥參加了一個小型報告會,和同行分享了自己的進展。參加這個會議的人裏,一個正在芝加哥大學生物物理系讀博的娃娃臉年輕人聽完報告,還和許錦波的學生交流了不少。
那個年輕人就是不久前剛剛獲得諾貝爾化學獎的約翰·朱默帕(John Jumper),幾個月後,他從芝加哥大學博士畢業,加入Google的Deepmind團隊——2016年3月,那個團隊做出的AlphaGo剛剛以4:1打敗了人類的冠軍棋手李世石,再過幾年,這個團隊將帶著AlphaFold再度出山。
2017年,許錦波將這個方法寫成論文【透過超深度學習模型精確預測蛋白質接觸圖】[1],發表在國際計算生物學的旗艦期刊PLoS Computational Biology上。這篇論文在2018年被這個期刊評為創新突破獎,至今被參照了1200多次。
諾獎得主哈薩比斯、朱默帕後來發表的關於AlphaFold的論文【基於深度學習的改進的蛋白質結構預測】【使用AlphaFold進行的精準蛋白質結構預測】,以及朱默帕的博士論文,都參照了許錦波的多篇論文。
CASP創辦者莫爾特教授說,在早期,CASP競賽的大多數參賽演算法只能稱之為「隨機」,大多數結構預測都是「看上去就令人痛苦的物體」。那時候,競賽地點定在一個有著木地板的古老教堂裏,如果上去講自己演算法的人講得太亂或者吹噓太過,底下的聽眾就會在木地板上「友好地跺腳」,整個空間裏仿佛回蕩著巨大的鼓聲。
許錦波沒有收到「友好的跺腳」,相反,他的演算法帶來了突破。莫爾特曾經統計過,從CASP競賽創辦以來,對於最困難的蛋白質結構預測任務,參賽演算法得分一直徘徊在30分左右,但後來出現了兩次飛躍。第一次飛躍就是許錦波的RaptorX,作為第一代AI演算法,把預測分從30分拔高到了60分。第二次是AlphaFold2,作為第二代AI演算法,把預測分又拉到了80多分。
資源緊缺
演算法和模型上取得了突破,但許錦波要再進一步提升預測的精度時,發現瓶頸卡在了資源上。
2014年剛開始嘗試深度學習方法時,許錦波甚至沒有GPU,都是用CPU去訓練的,構建不了太多層的神經網絡。到了16年,他終於有了12G視訊記憶體的GPU,能構建出60層的神經網絡,但依然沒法加太多參數,否則就會因為記憶體不夠用而沒法訓練。後來他靠申請來的研究基金一張張攢卡,一台機器安4張GPU卡,是他最好的配置。
除了算力,人手也很緊缺,許錦波自己一行行寫程式碼,帶的團隊一般就在2~3人,即使加上合作者,也從來沒超過5個人。
相比之下,做出AlphaFold的Deepmind團隊,背靠谷歌,算力和人才都充裕得多。2020年附近,AlphaFold團隊就已經拉起了30人的隊伍,裏面有許多專門的AI演算法最佳化工程師,可以用上幾百塊GPU,去實作極耗算力的註意力機制網絡。
對於蛋白質預測,對於深度學習的AI大模型,學術界的資源和進度,越來越落後於有著「鈔能力」和強大算力支撐的工業界。足夠好的工程加上足夠多的資源,堆出來的量變足以引發質變。
許錦波已經在學術界證明了自己,他發表的論文已經被參照了一萬多次,當選為計算生物學會的會士,曾獲美國史隆研究獎、前沿科學獎、美國自然科學基金早期職業獎、【PLoS Computational Biology】創新突破獎、國際計算生物學頂級會議 RECOMB 最佳論文獎和時間檢驗獎等等。
這一次,他想在工程上做得更好更徹底,做出實在的東西,解決真實的工業界問題。
他選擇回國創業。
捧出一顆分子之心
回到國內,2022年,許錦波創立了名為「分子之心」(MoleculeMind)的公司,組起一支「五花八門」的強大團隊,有做生物的、做電腦的、做藥物和臨床的各路學霸專家,整個團隊裏80%是研發,研發團隊裏90%是博士。
AI設計出的分子,不能僅僅在虛擬環境裏跑出一個高分,而是最終要到現實裏去經受生物實驗和工業生產的考驗。許錦波希望團隊裏的人不僅要有很強的技術背景,而且學習能力強,和其他不同背景的人也能很好地交流,「我們在做的事情是交叉學科裏比較大的專案,而且是從零到一,很多專案此前沒有別人做過。這就需要團隊在一起密切合作。如果團隊之間不能互相理解、順暢交流的話,效率就會非常低了,有些事情甚至做不出來了。通常來說,我們很多解決方案都是既需要懂計算、懂AI,也需要懂生物背景。很多事情還需要大家邊做邊學。」
一位分子之心的團隊成員說,在他們團隊裏日常的消遣是做數學題,最難的那種,題目丟進群,一會兒,學霸們紛紛把解題思路和答案發出來,許教授也會參與。
「 中午吃完飯,晚上休息時,大家在一起閑著就會做點題,數學題比較多,有時候也會搞點物理題、人文題、歷史題,」許錦波說,「我們這裏學霸多,喜歡互相挑戰。」
拉起這支精兵強將,許錦波並不打算重做一個AlphaFold,他的野心更大一些——
讓AI「按需設計」蛋白質
自然裏存在的蛋白質不是天上掉下來的,它們必須滿足種種條件,比如要始終適應變化的環境,一次適應不了,它所歸屬的生物就滅絕了。它們有來處、有源頭,是在漫長的演化過程裏逐漸形成的。而演化有路徑依賴,演化喜歡重新利用已有的東西,縫縫補補,略加改動,將就著用。
而AI沒有歷史包袱,AI可以設計出自然界裏從未存在過的全新蛋白質。
人體裏可能有十萬種蛋白質,現實裏能找到的蛋白質可能有幾十億種,看上去很多,但光是一個300個胺基酸的蛋白質理論上就有20300種可能。
如果說理論上可以存在的蛋白質就好比地球上的海洋,那麽大自然迄今制造出的蛋白質,不過是海洋裏的一滴水。
但AI設計出的蛋白,能比大自然設計出的更好嗎?許錦波需要一個「裏程碑」,來證明這件事行得通。
證明來得很快,就在分子之心創立一年多的時候。
佳績頻出
那時候,許錦波這個單執行緒的科學家,正逐漸適應了多執行緒的創業,他一邊組建團隊,一邊繼續開發演算法訓練AI,一邊引入投資方和合作方。
當時,中國的合成生物學的一家龍頭企業找到了分子之心。這家公司遇到的問題是,一個蛋白的最佳化陷入了瓶頸。
那是合成步驟裏的一個關鍵催化酶,極具商業價值又涉及行業瓶頸,它是一個跨膜蛋白,用傳統的實驗方法最佳化了十幾年,現在已經到達了最佳化極限。使用生物方法解析晶體結構需要耗時數月甚至數年,且成功率極低。該酶參與的反應過程異常復雜,需要多步反應,涉及輔酶、電子傳遞等復雜因素。這導致很難用傳統的定向前進演化方法,借助高通量實驗來對這個酶進行最佳化。
用其他AI來最佳化也依然很難,酶的催化反應是一個動態反應的過程,酶的催化反應是一個動態反應的過程,AlphaFold2等工具的功能局限於蛋白質靜態結構預測,也不能產生新的蛋白質序列,與真實的需求差異較大,難以滿足精準的蛋白質設計的需求
要精準最佳化,需要具備預測蛋白質動態結構的能力。
這項最佳化工作原定2~3年內完成,但分子之心綜合運用AI蛋白質技術和量子化學、分子動力學等科學計算方法,實作了蛋白質動態設計,只花了6個月,就設計出了一個活性和特異性更高的新酶。
產業方實驗數據顯示,相對於野生菌,AI設計的這個酶使菌種產率提高了5倍!
AI設計和最佳化的蛋白,有時候的確會走出奇妙的「神之一手」。
有一回,許錦波團隊要最佳化另一個酶,做傳統實驗的科學家建議改動酶的幾個功能區域,畢竟那裏是酶去結合受質、催化反應的地方。然而,AI卻建議改一個距離功能區很遙遠的胺基酸。
「怎麽改這個地方呢?」傳統派科學家覺得太扯了。然而,真的根據AI建議改動後,實驗卻得出了不錯的結果。
後來發現,這個酶在反應時,會把遠處的這個胺基酸給折疊過來,湊到功能區附近,等反應結束,這個折疊又開啟,那個胺基酸就又歸位到距離功能區很遙遠的地方。
有些改動在沒看到AI給出的結果之前,人根本就想不到。但一旦看到AI改動後的結果,再多琢磨一下,就會覺得AI有它的道理。就像不走定式的AlphaGo,在對弈中下出了不少人類棋手不會有的開局和棋步,有些在人類棋手看來甚至像是「惡手」,但最終證明是對全域有利的。
為什麽AI能做出傳統實驗做不到的最佳化?可能是因為AI一開始挑選的余地,就遠遠大於傳統的實驗方式。如果說傳統實驗方法的「搜尋空間」是在幾十萬種可能性裏搜尋,那麽AI的「搜尋空間」是從百億種可能裏去搜尋。
而許錦波訓練的AI演算法,能將這百億種可能,精準地縮減到幾十種可能。在後續的實驗驗證步驟裏,這幾十種可能裏,幾乎總能湧現出不止一種滿足需求的蛋白質分子:增強了一種塑膠降解酶的活性,而且把這種酶在菌株裏的產量提升了400%;改造了一種抗癌細胞因子,在保留了原本的抗腫瘤效果的同時,把它的毒副作用降低到了原本的千分之一;最佳化了一種代糖用酶,讓這種酶的半衰期從2.3小時延長到了將近200小時,大幅降低了生產成本……
分子之心還在做一些嘗試,比如最佳化發酵工藝,設計出一種特別的中間蛋白,把中間的三步反應變成一步反應,減少了中間環節,工藝的可控性會升高,產率也能升高,而且減少了對發酵罐、水電成本的需求,成本可以大幅下降。
有些生物合成公司已經卷到在建立自己的小型發電站,來節省電費成本。相比之下,最佳化生產環節,才是真正釜底抽薪的降本增效。
去年,隨著大語言模型與生成式人工智能的興起,不少科學家認為,基因與蛋白質序列,與語言序列存在相似性,大語言模型也同樣可以套用在蛋白質上,Meta的AI科學家也做了這樣的工作,並且把它發到了【Science】上。
分子之心也將其套用到蛋白質生成領域,推出了名為「NewOrigin」(達爾文)的蛋白質大模型。生物學家透過和「達爾文」進行對話,就能獲得AI輔助設計的蛋白質。
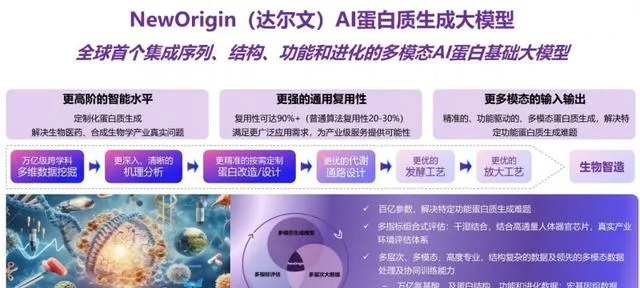
NewOrigin,達爾文,這個名字的意思是,這將是一次AI驅動的新物種起源。蛋白質的前進演化,將從大自然的隨機前進演化,變成AI設計的定向前進演化。
在一項與藥企的合作中,達爾文大模型對野生型蛋白進行突變設計,最佳化蛋白的穩定性、表達量等多個目標,僅僅三天就設計出數十個理想的候選蛋白,動物實驗顯示,疫苗產生中和抗體滴度為已公開專利和相關大型藥企蛋白疫苗的數倍。
如果說傳統的實驗方法是「大海撈針」,許錦波的AI方法就是先「百億裏挑幾十」,然後在幾十種分子裏「優中選優」。
這不僅大幅降低了成本,也大大縮減了研發時間,傳統方法要花幾年、幾個月,許錦波的AI方法只要花幾星期、幾天。
許錦波相信,這個時間還會再縮短——到幾小時,甚至幾分鐘。
對AI和合成生物學來說,這可能是最好的時代。
中國2022年釋出的【「十四五」生物經濟發展規劃】裏,對生物技術與資訊科技融合套用提出了明確的要求,以及建設關鍵共性生物技術創新平台等。
2023年,美國白宮科學技術政策辦公室釋出了一份更具體的報告,呼籲有關部門重視生物制造技術的潛力,以生物技術解決氣候、糧食、供應鏈安全、健康等宏大問題,共21個方向、49個具體目標,其中包括要將AI套用於生物設計與生物工程,目標是在5年之內,實作精確地設計酶或者小分子,可以選擇性結合任何所需的靶點,且設計蛋白質耗時不超過3個星期。
今年5月,AlphaFold 3推出,並由DeepMind子公司Isomorphic Labs開始推進商用,相關技術不再開源。在科研上,AlphaFold仍然是蛋白質預測的AI工具,而在商業上,他們的任務很明顯:設計突破性藥物。2024 年 1 月,Isomorphic Labs 宣布與禮來和諾華達成兩項價值 30 億美元的藥物研發協定。這裏的關鍵問題,還是對蛋白質結構、功能的理解,蛋白質與配體、蛋白質與蛋白質的相互作用等。
對比美國所要走的路線圖,分子之心其實已經在快速解決其中的一些關鍵問題,比如分子之心做出的AI蛋白質最佳化設計平台MoleculeOS,其中融合了十幾項全球領先的演算法,可以進行蛋白質結構預測、蛋白質側鏈結構預測與基於側鏈資訊的序列設計、抗體抗原復合物結構預測,抗體設計、酶穩定性最佳化、酶活性最佳化等工作。
「現在做這個方向的團隊越來越多,但我對我們的演算法有信心,比如在酶的設計改造上,我們團隊肯定是世界領先的。我的長期目標是,別人要一個特定功能的蛋白質,我用我的AI,在電腦上操作幾分鐘,就可以設計出一個現實裏符合要求的分子。」許錦波說,「我希望打造出中國生物經濟時代的基礎設施。」











