一、
生成式
AI
推理
需求旺盛
,量化技術升級降低推理門檻
1.1 生成式 AI 模型 持續叠代 , 推理需求旺盛
生成式 AI 模型效能不斷提升, 或處於 更 大規模 放量 前夕, 推理需求 有望高速增長 。 OpenAI 於 2022 年 11 月推出生成式 AI 套用 ChatGPT ,在不到兩個月的時間內,月活躍 使用者數突破 1 億人。以 ChatGPT 為代表的生成式 AI 套用快速叠代、落地,模型推理的 算力需求逐漸顯現。隨著生成式 AI 模型參數和 Token 數量不斷增加,模型 單次 推理 所需 的算力持續攀升。同時, ChatGPT 、 Gemini 、 Kimi 等聊天機器人的使用者數逐步上升, Microsoft Copilot 、 Adobe Firefly 、 WPS AI 等辦公助手持續落地, 使用者側的流量不斷 上 升 , 推理算力需求有望高速增長。
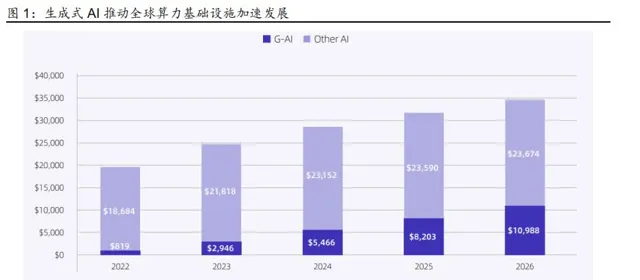
推理算力 未來 有望 超過訓練算力 , 最終 訓練 芯片 與 推理芯片 數量 之比或達到 2 : 8 。 目前 生成式 AI 模型仍處於快速叠代 ,各廠商 相互追趕的階段 ,隨著模型效能的逐步穩定和應 用的陸續落地 , 算力的 推理需求 有望超過訓練 需求。 而 推理需求與訓練需求 在 計算量、 精度要求 以及 部署位置 上存在差異 。 一方面, 訓練需求的 精度要求較推理需求更高, 因 此 訓練芯片 也就要求有更高的精度範圍,在高精度場景下同樣需要具備較強的效能 。 另 一方面 , 訓練芯片主要部署 在 數據中心(雲側),推理芯片則會兼顧雲側與邊緣側的算力 需求 。 根據舒妮達電氣的 測算 , 到 2028 年 人工智能 的 推理負載有望 占比 達到 85% 。 我 們認為: 考慮到雲側和邊緣側巨大的推理需求, 訓練芯片與推理芯片數量之比或 將 達到 2 : 8 。

1.2 量化技術 有助於降低 推理的 算力 門檻
量化技術 ( Quantization ) 是決定 生成式 AI 推理成本的關鍵因素 , 量化技術的叠代升級 有望 降低 推理門檻 。 深度神經網絡模型存在參數冗余 的 問題,所有參數 均 使用 32 位浮點 型數值 ( FP32 ) , 但 神經網絡模型 實際 使用 的精度遠不 到 FP32 所表示的範圍 。 如果 針對 低位寬的數值計算進行最佳化,使用低數值進行大規模矩陣運算, 模型推理過程 會 有 明顯 的 加速效果 。
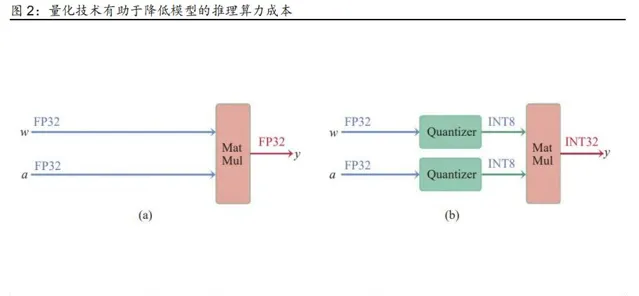
模型量化 指的是 透過降低網絡模型參數數值表示所需的位寬,在不影響模型任務效能情 況下達到降低 精度 和 記憶體容量的效果 。 假設 將一個參數全部是 FP32 的神經網絡的權值 和啟用值全部量化到 16 位整型數值 ( INT16 ) 或 8 位整型數值 ( INT8 ) ,其記憶體占用和 精度理論上均可減少至原 先 的四分之一 , 如果 部署的 處理器 低精度運算較快 ,則能夠 有 效 加速 推理 過程 。 目前 INT8 量化 技術 已 比較 成熟, Google 的 TensorFlow 、 輝達 的 TensorRT 、 Meta 的 PyTorch 等模型部署框架均已支持 INT 8 量化技術 。
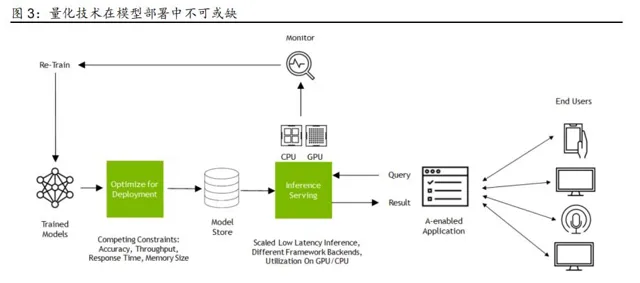
量化技術快速發展 ,為 CPU+ASIC 、 CPU+FPGA 等技術路線 的發展 ,以及國產算力 的 放量 提供了技術基礎 。 人工智能模型 的量化技術 從最初的 FP16 量化 快速發展到 目前應 用最成熟的 INT8 量化 ,再到 正在進一步研究中的 INT4 量化 ,呈現出數據精度逐步降低, 記憶體或視訊記憶體占用不斷減少的趨勢 。 這一趨勢有助於 CPU+ASIC 、 CPU+FPGA 等技術路 線透過 軟硬件 的最佳化提高推理能力 , 也有助於 國產算力 透過增加 低精度 計算單元等方式 , 以 較 成熟的制程 工藝實作 可用的推理算力。
二、 推理芯片 多種 技術路線齊頭並進, 推動生成式 AI 落地
2.1 輝達 、 AMD 長期 關註 GPU 的推理算力
輝達和 AMD 的數據中心 GPU 產品 , 在關註訓練場景的同時,也始終關註推理場景的 技術革新 。 2022 年以來, 輝達 先後推出了 Hopper 、 Blackwell 兩代 GPU 架構,較此 前的 Ampere 架構增強了 FP8 甚至是 FP4 精度下的 吞吐量 ,能夠更高效地完成生成式 AI 模型的推理任務。 AMD 新 推出的 MI300X 也較 p00 提升了 FP 8 精度下的 計算能力 。 以 輝達和 AMD 為代表的 數據中心 GPU 廠商 的 技術發展趨勢,進一步表明 量化技術的叠 代 發展對 模型推理算力需求 有重要的 影響 。
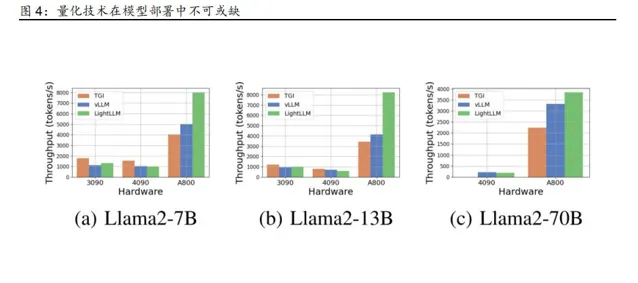
另一方面, 輝達和 AMD 的消費級 GPU 產品,同樣具備 接近 千億參數量級的 生成式 AI 模型的推理能力 ,從側面說明 推理芯片的 門檻相對較低 。 根據 公開資料, Llama - 2 7B 和 13B 模型能夠成功 部署在 8 卡 輝達 RTX 3090 伺服器上, Llama - 2 70B 則能夠在 8 卡輝達 RTX 4 090 伺服器 上 進行部署 。 盡管在推理效能上有一定的損失 ,但消費級 GPU 仍有完成 接近 千億參數量級的生成式 AI 模型 的能力
2.2 海外 CSP 自研 芯片 ,或 將 另辟蹊徑
谷歌、微軟、亞馬遜 、 Meta 等海外 CSP 企業 在 大規模采購 輝達數據中心 GPU 的同 時, 也在積極自研用於 模型訓練和推理 的 芯片 , 有望成為滿足推理算力需求的另一種途 徑 。 與輝達和 AMD 的數據中心 GPU 類似 , 海外 CSP 自研芯片同樣 關註 算力集群的 規模化和擴充套件性。 同時, 由於 面向 AI 場景的 算力 芯片與演算法間 存在 緊密 聯系 , 海外 CSP 重視 演算法 與算力 芯片 間的 協同設計 , 透過 支持新一代量化技術的數據 精度、 部署 模型關 鍵演算法的直接專用加速器 等方法,進一步 提高 推理 效能 。
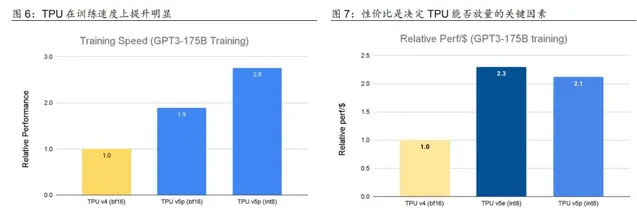
谷歌於 2023 年先後釋出了 TPU ( Tensor Processing Unit ) v5e 和 TPU v5p 兩款 ASIC 芯片,重點提升了訓練 速度 和推理的性價比 , 並 對 PyTorch 、 TensorFlow 等先進 框架 進行了 整合 。 TPU v5e 和 TPU v5p 相較於 TPU v4 , 在 訓練 速度上都有接近 2 倍左 右的 提升, 單位美元的 推理效能 也都 提升 2 倍 以上 。 以 TPU v5p 為例, 每個 Pod 由 8960 塊 芯片組成, 芯片間 以 4800 Gbps 的 傳輸 速率 進行互連。 Gemini 1.0 在訓練時 即 使用 TPU v4 和 TPU v5e 。 我們認為: 隨著 TPU 性價比的進一步提升, 有望在推理芯片 市場擴大份額 ,加速生成式 AI 模型的落地行程 。
微軟、亞馬遜 、 Meta 同樣 發力 自研芯片, 為 生成式 AI 的 訓練和推理提供更多的算力選 擇 。 微軟於 2023 年 11 月推出 Azure Maia 100 , 目前正在 透過 搜尋引擎 Bing 和 Office A I 系列 產品 進行測試 。 Azure Maia 100 采用台積電 5nm 工藝,擁有 1050 億顆晶體管, 能夠支持 低於 8 位數據類別。 亞馬遜於 2023 年 12 月推出了 Amazon Graviton4 和 Amazon Trainium2 兩款自研芯片 , 根據亞馬遜雲科技的測算, Graviton4 與 目前正在使 用的 Graviton3 處理器相比,效能提升 30% ,獨立核心增加 50% 以上,記憶體頻寬提升 75% 以上 。 Meta 也有望 推新款自研推理芯片 Artemis , 或 於 2024 年內完成 Artemis 在 Meta 自有數據中心的部署。 我們認為: 海外 CSP 企業 自研 ASIC 芯片的嘗試 ,也從側面 說明 面對生成式 AI 巨大的訓練和推理需求,海外 CSP 企業 也期望 另辟蹊徑, 探索 更具有性 價比 和計算效率的 算力解決方案 ,從而為多種技術路線的發展創造了可能性 。

2.3 國產推理芯片 市場潛力大 , 有望迎來重大機遇
國產 推理芯片快速發展, 已在推理 和部份訓練 場景 下 落地 ,未來 有望 迎來重大發展機遇 。 以 Kimi 和 WPS AI 為代表的 C 端和 B 端套用 陸續落地 , 國內 的 推理 算力 需求 正在快速 上 升 。 衡量 算力 大小 的維度不僅包括 集群峰值 算力 的 大小, 也 要考慮 到 算力 在 實際 部署中 的使用效率 和最佳化 程度。 實際可使用的 算力 是 工程化 的 結果, 涉及 從芯片 到開發工具包 的多 個 層次, 對 算力 提供者的 工程 能力及案例 經驗都有要求 。 國產推理芯片在多個場景 下的部署, 有助於 國產算力廠商 叠代最佳化自身產品, 根據實際需求最佳化 芯片設計及 對應 的 開發工具包 ,加速形成軟硬件一體的 開發生態 。
以 營運商 和 國內互聯網廠商為 代表 的 需求端正在加速建設 AI 算力, 有望推動 國內推理芯 片市場快速 放量 。 2023 年以來 ,通訊營運商 已集中采購超 1.5 萬台 AI 伺服器, 采購專案 體現了 營運商對智算中心 建設 的重視,同時也反映了國內 推理 和訓練 算力 已加速 部署。 在新建成的 AI 算力基礎設施 中, 國產 AI 芯片的使用率較高 , 中國移動智算中心(呼和 浩特)部署的 AI 加速卡國產化率超 85% , 中國聯通 則基於 華為昇騰 AI 基礎軟硬件 在北 京建立了 的 全國產化的智算中心 。 2023 年 , 百度訂購了 200 台 8 卡 伺服器 , 搭配 1600 塊 昇騰 910B 。
營運商和國內互聯網廠商的 持續部署,有助於 支撐 生成式 AI 套用在國內 落地, 從而在實際運用中 不斷對推理芯片的效能叠代升級 。 寒武紀 面向模型訓練和推理場景推出了 MLU370 , MLU370 采用 7nm 制程工藝 及 芯粒 ( C hiplet )技術, 透過 封裝多顆 AI 計算芯粒( MLU - Die ) 增強計算效能 。 同時, 寒武紀 為 MLU 370 配備了 Cambricon Neuware 軟件棧 和 推理加速引擎 MagicMind , 助力 開發 者 提升部署效率 。 目前 MLU 370 已 向 阿裏雲 等 客戶 進行了批次交付 。 透過 深耕行業客戶, 寒武紀 有望推動 MLU370 等 產品在更多標誌性套用場景 實作商業化 落地,進一步拓展業 務覆蓋範圍和客戶覆蓋領域。
華為 於 2019 年釋出 昇騰 910 芯片, 此後陸續釋出了 升級版本 昇騰 910B 、昇騰 910C , 提升了 NPU 之間交換數據的能力, 對網絡介面 進行了 升級 。 昇騰 910 在設計上 較為關註 低精度的 場景 , FP16 算力達到 256 T FLOPS , INT8 算力達到 512 TOPS 。 同時,華為 還 釋出了 昇騰 Ascend C 程式語言 、 昇思 MindSpore AI 框架 等 配套軟件棧 , 提供系列工 具及套件,支撐模型高效原生開發 ,構建較為完整的 軟件生態 。

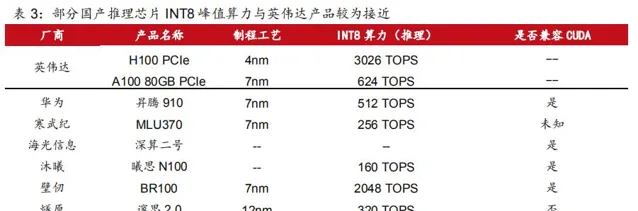
海光資訊 研發的深算二號 已實作批次出貨, 實作 LLaMa 、 GPT 、 Bloom 、 ChatGLM 等 生 成式 AI 模型的全面套用,與包括文心一言 在內的 大模型全面適配 。 沐曦、壁仞、燧原等 廠商也陸續推出了 滿足推理 場景 需求的 計算 芯片 , 部份推理芯片 在 INT 8 精度下的 計算能 力 與 輝達 對應產品較為接近 。 其中 , 部份廠商的推理芯片實作相容 CUDA 架構 ,進一 步降低了 模型移植成本
我們認為: 生成式 AI 的發展是一個不斷叠代升級的過程, 隨著 國內 生成式 AI 模型的質 量持續提升,有望出現 更多 優質套用,從而帶動 推理算力需求快速上升 。 在推理 場景下 , 算 力的性價比 顯得更為重要 。 在供給端 有所 限制的情況下 , 國產推理芯片 有望受益於 國 內生成式 AI 套用的落地,迎來重大發展機遇。
本文僅供參考,不代表我們的任何投資建議。【 幻影視界】 整理分享的資料僅推薦閱讀,如需使用請參閱報告原文。











