編輯:潤
【新智元導讀】 由Transformer論文作者創立的Adept AI推出了號稱僅次於GPT-4V和Gemini Ultra的多模態大模型Fuyu-Heavy。它不但有精準辨識圖片,特別是UI的能力,數理推理能力也非常強。
2024年果然是大模型的多模態之年。
又有一家獨角獸Adept AI推出了他們的多模態大模型Fuyu-Heavy。
這家由兩位從谷歌出走的Transformer論文作者創立的Adept AI,目標是開發一個提升打工人工作效率的AI智能體。
而Fuyu-Heavy就是驅動他們未來即將推出的智能體產品的基礎多模態大模型。
他們宣稱,Fuyu-Heavy是除了GPT-4V和還沒有面世的Gemini Ultra之外,是目前最強大的多模態大模型。
而且它的尺寸大小還不到前面兩者的10%。
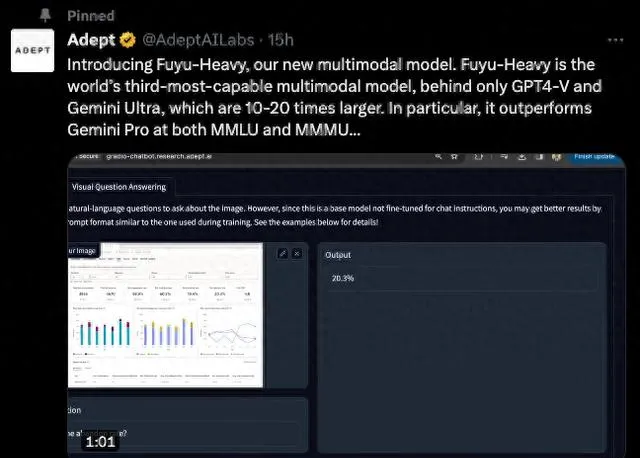
-它擅長多模態推理。對我們來說,殺手級功能是UI理解,但它在更傳統的多模式基準測試中也表現良好。特別是,Fuyu-Heavy 在 MMMU 基準測試中的得分比Gemini Pro還要高。
-在標準的基於文本的基準測試中,盡管Fuyu-Heavy必須將其部份能力空間留給影像模組,但它的效能仍可以超過同級別模型的效能。
因為Adept AI最優先的產品目標受眾是企業使用者,他們致力於開發一個能在辦公場所大大提高工作效率的AI智能體,所以他們專門還訓練了Fuyu-Heavy的UI理解能力。
而且按照Adept的說法,Fuyu-Heavy有非常強的數理推理能力,能夠在多模態的任務中充分發揮數理能力,為此他們專門展示了一道「行測」題:
提示詞:
根據下表,哪些食物最有可能引發食物中毒

Fuyu-Heavy輸出:
該表顯示了吃了不同食物的人數以及吃了這些食物而生病的人數。為了確定哪種食物最有可能導致食物中毒爆發,我們正在尋找食用該食物並患病的人比例最高的食物。
讓我們計算一下吃了每種食物並生病的人的百分比:
涼拌雞:34 / 86 = 0.395,即39.5%
薯仔沙拉:38 / 54 = 0.704,即70.4%
雞蛋三明治:40 / 76 = 0.526,即 52.6%
水果派和鮮奶油:12 / 32 = 0.375,即 37.5%
芝士:12 / 48 = 0.25,即 25%
吃了該食物而生病的人比例最高的食物是薯仔沙拉,占70.4%。因此,薯仔沙拉是最有可能引發食物中毒的原因。
Fuyu-Heavy是如何誕生的
在去年10月份,Adept推出了自己的基礎模型Fuyu-8B,是一個非常簡潔高效,而且能力強大的原生多模態模型。
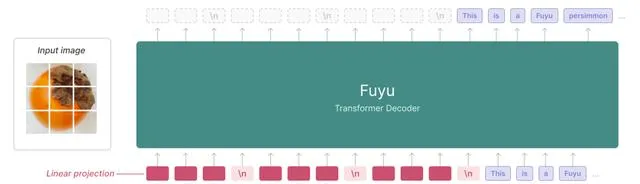
在Fuyu-8B的基礎之上,Adept花了4個月的時間不斷擴大模型的規模和能力。
除了模型縮放定律有關的標準問題之外,他們還必須處理原生的多模態大模型在文本和影像數據上與構架相關的各種問題。
影像數據給模型帶來壓力——給多模態模型餵數據會很困難:記憶體使用量激增,雲端儲存入口/出口受到限制;即使在訓練和推理之間一致地處理影像格式/座標也是很麻煩的問題。
影像模型是出了名的不穩定——所以他們不得不對Fuyu的架構和訓練過程進行了大幅調整,來應對這個問題。
而且,高質素的影像預訓練數據是非常稀缺的,他們投入了大量的精力來收集、整理甚至建立這些數據。文本和影像任務之間也存在微妙的平衡,文本數據太多,影像效能就會下降,反之亦然——必須找到合適的方法來大規模地實作這種平衡。
透過4個月的努力,在解決了這些問題之後,Adept推出了Fuyu-Heavy,同時很快將會推出基於這個模型的產品。
測評成績
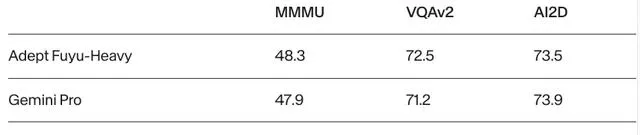
按照Adept的說法,Fuyu-Heavy的效能是僅次於GPT-4V和Gemini Ultra的多模態大模型。
如果單純評估文本能力,它的效能和Gemini Pro大致相當。

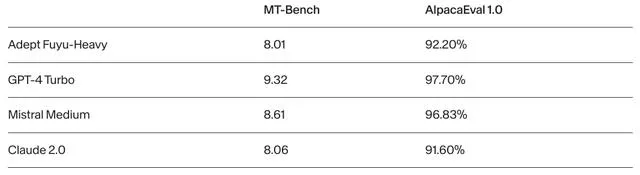
在評估長對話能力的MT-Bench和AlpacaEval 1.0上,Fuyu-Heavy的效能超過了Claude 2。
而在評估模型多模態效能的MMMU上,Fuyu-Heavy表現出了超過Gemini Pro的能力。
驚人的多模態推理能力
Adept還分享了Fuyu-Heavy回答MMMU問題的案例。
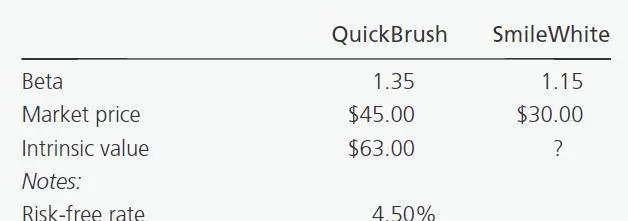
Janet Ludlow的公司要求所有分析師使用兩階段股息貼現模型 DDM和資本資產定價模型 CAPM來對股票進行估值。
Ludlow使用CAPM和DDM對QuickBrush公司的估值為每股63美元。
她現在必須重視 SmileWhite 公司。使用下表中的資訊計算 SmileWhite 要求回報率:
Adept回復:
SmileWhite的所需回報率可以使用資本資產定價模型(CAPM)計算,即:
要求回報=無風險利率+Beta x(預期市場回報-無風險利率)
表中提供了無風險利率和預期市場回報,SmileWhite 的Beta值為 1.15。
讓我們計算一下 SmileWhite 所需的回報率:
要求回報率 = 4.50% + 1.15 x (14.50% - 4.50%)
要求回報率 = 4.50% + 1.15 x 10%
要求回報率 = 4.50% + 11.50%= 16%
Fuyu-Heavy還可以執行更加復雜的計算:
表 11.47 提供了最近對凈資產估計為 100 萬美元或以上的最年輕線上企業家的調查。他們的年齡範圍從17歲到30歲。表中的每個單元格說明了與年齡別組相對應的企業家數量及其凈資產。我們想知道年齡和凈資產是否獨立。
求出$$\ch$$^2 test statistic為多少?
Adept回復:
為了回答這個問題,我們需要進行獨立性的chi-square測試。
該檢驗的原假設是年齡和凈資產是獨立的,而備擇假設是它們不是獨立的。
chi-square獨立性檢驗的檢驗統計量為:
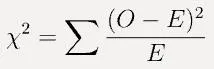
其中 O 是觀察到的頻率,E 是預期頻率,並且對關連表中的所有單元格進行求和。
每個空格的預期頻率計算如下:
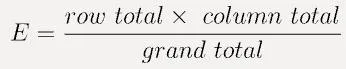
chi-square的獨立性檢驗的自由度為:

在給定顯著性水平(例如 0.05)下具有 df 自由度的chi-square分布的臨界值可以在chi-square表中找到或使用統計軟件包計算。
如果計算出的chi-square值大於臨界值,我們拒絕零假設並得出年齡和凈資產不獨立的結論。如果計算出的chi-square值小於或等於臨界值,我們就無法拒絕零假設並得出結論:年齡和凈資產是獨立的。
讓我們計算表中每個單元格的預期頻率:
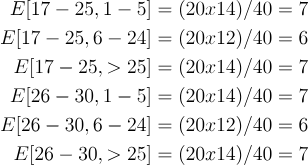
現在,我們來計算chi-square檢驗統計量:
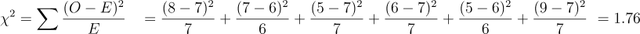
該測試的自由度為:
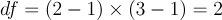
具有 2 個自由度、顯著性水平為 0.05 的chi-square分布的臨界值約為 5.99。
由於我們計算出的chi-square值 (1.76) 小於臨界值 (5.99),因此我們無法拒絕零假設並得出結論:年齡和凈資產是獨立的。

這驚人的計算能力和識圖準確度,讓人實在是期待他們未來的智能體產品!











