P-tuning v1 一文小結
這篇文章介紹了一種名為P-Tuning的新方法,用於改善預訓練語言模型(PLMs)在自然語言理解(NLU)任務中的效能和穩定性。P-Tuning透過將可訓練的連續提示嵌入(continuous prompt embeddings)與離散提示(discrete prompts)結合使用,透過反向傳播進行更新,以最佳化任務目標。文章透過實驗表明,P-Tuning不僅透過減少不同離散提示之間的效能差距來穩定訓練,而且在包括LAMA和SuperGLUE在內的一系列NLU任務上顯著提高了效能。P-Tuning對凍結和微調的語言模型都普遍有效,並且在全監督和少樣本(few-shot)設定下均表現出色。
文章的主要貢獻包括:
- 提出P-Tuning方法,使用連續提示嵌入來增強離散提示,以提高語言模型的穩定性和效能。
- 透過實驗驗證P-Tuning在知識探測(LAMA)和一般自然語言理解(SuperGLUE)基準測試中的有效性。
- 展示了P-Tuning在不同任務和設定下減少不同離散提示之間效能差異的能力,從而提高了語言模型適應力的穩定性。
- 探討了連續提示編碼器(prompt encoder)的不同實作方式,包括LSTM網絡、多層感知器(MLP)等。
此外,文章還進行了一些探索性實驗和分析,比如連續提示的最佳位置、數量對少樣本學習效能的影響,以及P-Tuning與自動搜尋離散提示方法的比較。最後,文章討論了P-Tuning與現有工作的關系,並得出結論,P-Tuning是一個有效的方法,可以提高預訓練語言模型在NLU任務上的效能和穩定性。

0 Abstract
使用自然語言模式對預訓練語言模型進行提示已被證明對自然語言理解(NLU)是有效的。然而,我們的初步研究表明,手動離散提示常常導致不穩定的效能——例如,提示中改變一個詞可能會導致顯著的效能下降。我們提出了一種名為P-Tuning的新方法,它采用可訓練的連續提示嵌入與離散提示相結合。從實證角度來看,P-Tuning不僅透過最小化不同離散提示之間的差距來穩定訓練,而且在包括LAMA和SuperGLUE在內的廣泛NLU任務上顯著提高了效能。P-Tuning對凍結和微調的語言模型都普遍有效,在全監督和少樣本設定下均表現出色。
什麽是連續提示,什麽是離散提示?
連續提示(Continuous Prompts)和離散提示(Discrete Prompts)是在使用預訓練語言模型(PLMs)進行自然語言理解(NLU)任務時,用來改善模型效能的兩種不同的提示方法。
離散提示(Discrete Prompts) :
離散提示通常是由人類專家手動編寫的一系列自然語言詞匯或樣版,它們作為輸入的一部份,用來引導語言模型更好地完成特定的NLU任務。這些提示是靜態的,即它們在模型訓練或推理過程中不會改變。例如,在一個問答任務中,離散提示可能是:
"What is the capital of [X]? The capital is [Y]."
在這個例子中,"[X]" 和 "[Y]" 是占位符,分別代表問題中詢問的國家和預期的答案。
連續提示(Continuous Prompts) :
與離散提示不同,連續提示是一組可訓練的向量,它們與離散提示結合使用,並且在模型訓練過程中會透過反向傳播演算法更新。連續提示提供了一種將學習性融入輸入的方式,能夠適應力地調整模型的行為以最佳化特定任務的效能。例如,在上述相同的問答任務中,連續提示可能被嵌入到離散提示中,形成如下結構:
"What is the [continuous prompt vector] capital of [X]? The [continuous prompt vector] capital is [Y]."
在這裏,"[continuous prompt vector]" 是一個可學習的向量,它在模型訓練過程中會被調整,以幫助模型更好地預測首都。
舉例說明 :
假設我們有一個簡單的NLU任務,即確定一個句子中的主題和評論物件。我們可以使用以下兩種提示方法:
離散提示 :"The [MASK] is a great [MASK]." 這裏的兩個"[MASK]"是離散的占位符,分別代表句子中的主題和評論的內容。在實際套用中,它們將被具體詞匯替換,例如:"The movie is a great masterpiece."
連續提示 :如果我們在這個任務中使用P-Tuning,我們可能會在句子的某些部份添加連續提示,如:"The [continuous prompt vector] movie is a [continuous prompt vector] great [continuous prompt vector] masterpiece." 這些連續提示向量會在訓練過程中學習到最優的表示,以幫助模型更好地理解句子結構和語意。
總的來說,離散提示是固定的語言模式,而連續提示是動態的、可訓練的向量,它們可以適應力地最佳化模型對特定任務的理解和輸出。
1 Introduction
預訓練語言模型(PLMs;Brown等人,2020年)顯著提升了自然語言理解(NLU)的效能。PLMs接受不同的預訓練目標訓練,例如掩碼語言建模(Masked Language Modeling;Devlin等人,2018年)、自回歸語言建模(Autoregressive Language Modeling;Radford等人,2019年)、序列到序列(Seq2Seq;Raffel等人,2019年)以及排列語言建模(Permutation Language Modeling;Yang等人,2019年)。PLMs可以透過提示(Prompting;Brown等人,2020年;Schick和Schütze,2020年)進一步增強,提示使用人工編寫的提示模式作為語言模型的額外輸入。在PLMs進行微調時,可以在一個小的標記數據集上進行微調,或者凍結它們以直接用於下遊任務的推理。提示顯著提高了許多NLU任務的效能(Brown等人,2020年;Schick和Schütze,2020年)。
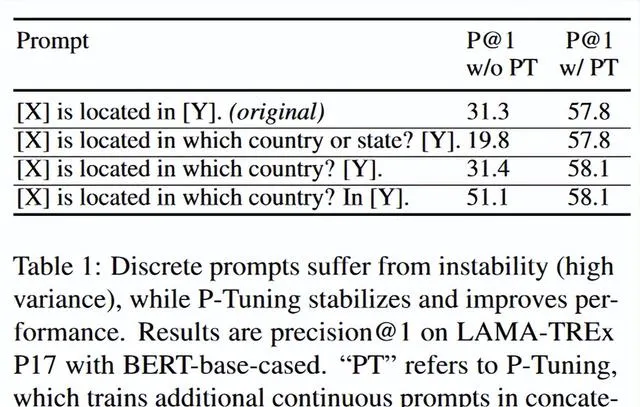
然而,我們觀察到手動離散提示存在相當大的不穩定性。 正如表1所示,使用凍結的語言模型時,提示中改變一個詞可能會導致效能大幅下降 。正如我們將在第3節中展示的,當語言模型被微調時,不穩定性問題有所緩解,但不同提示之間的效能差異仍然很大,特別是在少樣本(few-shot)設定中。這種離散提示的不穩定性問題在實踐中構成了一個關鍵挑戰。最近自動提示的方法嘗試為給定任務搜尋表現更好的提示(Shin等人,2020年;Gao等人,2020年;Jiang等人,2020b),但這些方法並沒有改變離散提示不穩定的本質。
為了減少離散提示的不穩定性,我們提出了一種名為P-Tuning的新方法,該方法使用可訓練的連續提示嵌入與離散提示進行連線。具體來說,給定一個離散提示作為輸入, P-Tuning將連續提示嵌入與離散提示標記連線起來,並將它們作為輸入提供給語言模型。連續提示透過反向傳播進行更新,以最佳化任務目標 。這種直覺是,連續提示將一定程度的可學習能力納入輸入中,這可能學會抵消離散提示中的微小變化,以提高訓練穩定性。為了進一步提高效能,我們采用了使用LSTM或MLP的提示編碼器來模擬連續提示嵌入之間的依賴性。
我們在兩個NLU基準測試中進行了實驗:LAMA(Petroni等人,2019年)知識探測和SuperGLUE(Wang等人,2019a)。在LAMA中,使用凍結的語言模型,P-Tuning在相同的預訓練模型上分別比手動離散提示和搜尋到的提示高出20多分和9分。在SuperGLUE中,使用微調後的語言模型,P-Tuning在全監督和少樣本設定下都優於PET(Schick和Schütze,2020年)的最佳離散提示。除了提高效能外,我們的結果顯示,在廣泛的任務和設定中,P-Tuning大大減少了不同離散提示之間的效能差距,這提高了語言模型適應力的穩定性。
2 Method
2.1 Issues with Discrete Prompts
提示技術采用自然語言模式作為額外的輸入,以使預訓練語言模型適應下遊任務(Brown等人,2020年;Schick和Schütze,2020年)。先前的工作(Zheng等人,2021年)已經指出,提示技術在許多自然語言處理(NLP)任務上取得了一致且顯著的改進。然而,如何編寫高效能的離散提示仍然是一個具有挑戰性的問題。
我們使用不同的手動提示在LAMA知識探測任務(Petroni等人,2019年)上進行了初步實驗,該任務旨在透過預測尾部實體從語言模型中提取三元組知識。表1的結果顯示,手動離散提示導致效能不穩定。例如,如果我們比較表中最後兩個提示,提示中改變一個詞會導致效能下降20個百分點。
面對這一挑戰,近期的研究工作提出自動化離散提示的搜尋過程,透過挖掘訓練語料庫(Jiang等人,2020b)、基於梯度的搜尋(Shin等人,2020)和使用預訓練的生成模型(Gao等人,2020)。 然而,這些工作旨在尋找表現更好的提示,但並沒有改變離散提示不穩定的本質。除了不穩定性問題,離散空間中的搜尋可能無法充分利用反向傳播的梯度,這可能導致次優解 。為此,我們探索了訓練連續提示的可能性,以穩定並提高語言模型適應力的效能。
2.2 P-Tuning
正式地,設M是一個具有隱藏層大小h和詞匯表大小|V|的預訓練語言模型。設{(xi, yi)}i是NLU任務的一個標記數據集,其中x0:n = {x0, x1, ..., xn}是一系列離散標記的輸入序列,y ∈ Y是一個標簽。我們的目標是估計分類的條件概率fM(x) = ˆp(y|x),其中M的參數可以是微調過的或者凍結的。
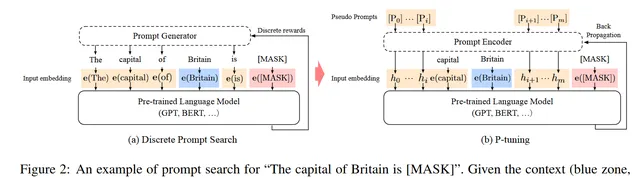
提示在格式上被提出為離散標記的形式(Schick和Schütze,2020年)。設[Di]為一個離散提示標記。每個提示可以被描述為一個樣版T = {[D0:i], x, [D(i+1):j], y, [D(j+1):k]},它可以將標記數據(包括輸入x和標簽y)組織成文本標記序列,使得任務可以被重新表述為填寫輸入文本的空白。例如,在預測一個國家首都的任務(LAMA-TREx P36)中,一個提示可以是「The capital of [INPUT] is [LABEL]。」。給定一個標記數據「(Britain, London)」,重構後的文本將是「The capital of Britain is [MASK]。」,其中「[MASK]」應該預測給定的標簽「London」。離散提示和離散數據一起被對映到輸入嵌入中:

這段內容描述了自然語言理解(NLU)任務中使用預訓練語言模型(PLMs)進行提示(prompting)的過程,以及如何透過提示來改善模型對特定任務的適應力。下面我將逐句解釋並提供詳細的例子。
預訓練語言模型的定義:
"M" 是一個預訓練語言模型,具有隱藏層大小 "h" 和詞匯表大小 "|V|"。這裏的 "h" 表示模型隱藏層的維度,而 "|V|" 表示詞匯表中不同標記的總數。
標記數據集的構成:
"{(xi, yi)}i" 是指NLU任務的一個標記數據集,其中 "xi" 是輸入序列,"yi" 是對應的標簽。"x0:n" 表示從 "x0" 到 "xn" 的一系列離散標記,代表輸入文本經過分詞處理後的標記序列。
任務目標:
目標是估計給定輸入 "x" 下標簽 "y" 的條件概率 "fM(x) = ˆp(y|x)"。這裏的 "fM(x)" 表示模型M對輸入x的分類概率預測。參數 "M" 可以是微調(finetuned)的,也可以是凍結(frozen)的。微調意味著使用特定任務的數據來調整模型參數,而凍結則表示使用預訓練的參數不變。
提示的格式:
提示以離散標記的形式提出,每個提示 "[Di]" 是一個離散的標記,可以是詞匯表中的任何詞或特殊符號。
提示樣版的定義:
"T" 是提示樣版,由一系列離散提示標記和輸入數據組成。"{[D0:i], x, [D(i+1):j], y, [D(j+1):k]}" 表示提示的結構,其中 "[D0:i]" 和 "[D(j+1):k]" 是提示的開始和結束部份,"x" 是輸入序列,"y" 是標簽。
任務的重新表述:
透過提示樣版,可以將NLU任務重新表述為填充輸入文本空白的形式。例如,在預測國家首都的任務中,提示可以是 "The capital of [INPUT] is [LABEL]。"
具體例子:
以LAMA-TREx P36任務為例,給定標記數據 "(Britain, London)",這裏的 "Britain" 是輸入 "x","London" 是標簽 "y"。根據提示樣版,重構後的文本是 "The capital of Britain is [MASK]。",在這種情況下,"[MASK]" 是一個占位符,模型的任務是預測並填充這個占位符,使其成為 "London"。
輸入嵌入:
最後,離散提示和離散數據一起被對映到輸入嵌入中。這意味著所有的文本,包括提示和實際的輸入數據,都會被轉換成模型可以理解的數值型嵌入向量。
總結來說,這段內容討論了如何透過預訓練語言模型和提示技術來處理NLU任務,以及如何透過設計提示樣版來引導模型完成特定任務,例如預測國家首都。透過這種方式,可以提高模型對任務的適應力和準確性。
然而,正如第2.1節所討論的,這樣的離散提示往往是極其不穩定的,並且可能在反向傳播時不是最優的。因此,我們提出了P-Tuning,它使用連續提示嵌入來改進和穩定提示。設[Pi]是第i個連續提示嵌入。P-Tuning的提示樣版如下:
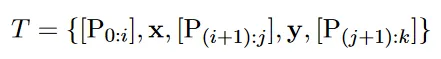
P-Tuning利用一個額外的嵌入函數f : [Pi] → hi來將樣版對映到。

最終,我們更新嵌入 {Pi}k i=1 以最佳化任務損失函數。
值得註意的是,我們也可以將離散提示與連續提示連線起來使用,這種做法表現更好,並在我們的實驗中被采用。P-Tuning適用於凍結和微調過的語言模型。
2.3 Prompt Encoder
在上述框架中,我們采用一個對映函數f來將可訓練的嵌入{Pi}對映到模型輸入{hi}。 直覺上,使用對映函數比使用獨立的可學習嵌入更方便地對不同提示嵌入之間的依賴性進行建模。在我們的實作中,我們使用一個輕量級神經網絡來構建函f 。具體來說,我們在第3節中嘗試使用長短期記憶(LSTM)網絡、多層感知器(MLPs)以及恒等對映函數。
3 Experiments
我們包括了兩個NLU基準測試:LAMA(Petroni等人,2019年)用於知識探測(第3.1節),以及SuperGLUE(Wang等人,2019年a)用於通用自然語言理解。在SuperGLUE上,我們考慮了全監督學習(第3.2節)和少樣本學習(第3.3節)的設定。
在LAMA上,遵循Shin等人(2020年)和Jiang等人(2020b年)的做法,語言模型是凍結的,只調整離散或連續的提示。對於SuperGLUE,遵循Schick和Schütze(2020年)以及Zheng等人(2021年)的做法,語言模型是經過微調的。在我們的設定中,我們同時最佳化語言模型參數和連續提示。這種設定不僅遵循了以往工作中的常見標準設定,而且還可以在經過微調和凍結的語言模型上評估P-Tuning。
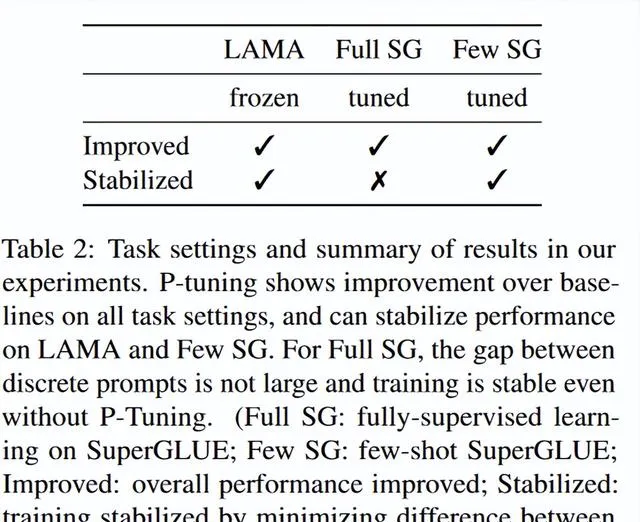
整體任務設定和結果總結如表2所示。
3.1 Knowledge Probing
評估了語言模型從預訓練中獲得的真實世界知識有多少。LAMA(Petroni等人,2019年)數據集透過從知識庫中選取的三元組建立完形填空測試來評估這一能力。
Datasets and vocabulary .LAMA要求所有答案采用單一標記格式。我們首先采用了原始的LAMA-TREx數據集,包含41種Wikidata關系,總共有34,039個測試三元組(即LAMA-34k,涵蓋了所有BERT詞匯表)。由於不同的預訓練模型擁有不同的詞匯表,為了允許直接比較,我們遵循先前的工作(Shin等人,2020年)采用了一個子集,這個子集涵蓋了GPT和BERT詞匯表的交集。這被稱為LAMA-29k。我們再次遵循Shin等人(2020年)來構建訓練、開發和測試數據,以便進行公平的比較。
Setup . LAMA為每種關系提供了一個手工制作的提示,如表1所示,這些提示是有效的,但可能不是最優的。對於雙向掩碼語言模型,我們只需要將「[X]」替換為主題實體,將「[Y]」替換為[MASK]標記;對於像GPT這樣的單向語言模型,遵循LAMA在Transformer-XL(Dai等人,2019年)上的原始設定,我們使用目標位置前的網絡輸出。

提示標記的數量和位置是根據開發集選擇的,為了簡化,我們為雙向模型選擇了(3, 主體, 原始提示, 3, 客體, 3)樣版,以及為單向模型選擇了(3, 主體, 原始提示, 3, 客體)樣版,因為這種配置對大多數關系都表現良好(數碼表示連續提示標記的數量)。連續提示與原始離散提示連線。在提示訓練期間,我們將學習率設定為1e-5,並使用Adam最佳化器。
解釋下上面的內容:
這段話描述的是在自然語言處理任務中,特別是在使用LAMA數據集進行知識探測任務時,如何設定和最佳化提示(prompt)的過程。以下是詳細解釋:
提示標記的數量和位置選擇 :在構建提示時,需要確定提示中應該包含多少個標記(tokens)以及這些標記的具體位置。這些設定是基於開發集(development sets)來決定的,目的是找到在大多數情況下都能表現良好的提示配置。
樣版選擇 :
對於**雙向模型**(如BERT),選擇了一個包含6個部份的樣版:(3, 主體, 原始提示, 3, 客體, 3)。這裏的數碼3表示在主體和客體的前後分別放置3個連續的提示標記。
對於**單向模型**(如GPT),選擇了一個稍微簡化的樣版:(3, 主體, 原始提示, 3, 客體),它與雙向模型的樣版類似,但沒有最後的3個連續提示標記。
配置效能 :所選樣版在大多數關系上表現良好,這意味著這種提示結構能夠有效地引導模型處理各種不同的語言模式。
連續提示與原始離散提示的連線 :連續提示(可能是一些預定義的詞或者特定的標記)被添加到原始的離散提示(手工編寫的提示樣版)中,以增強模型對任務的理解和處理能力。
訓練設定 :在進行提示訓練時,設定了學習率為1e-5,並使用了Adam最佳化器。學習率是控制模型參數更新速度的超參數,而Adam最佳化器是一種自適應學習率的最佳化演算法,常用於訓練深度學習模型。
結果在表3中呈現。P-Tuning顯著提升了知識探測的最佳結果,從LAMA-34k的43.3%提高到50.6%,從LAMA-29k的45.2%提高到64.2%。此外,P-Tuning在同一規模的模型上超越了以前的離散提示搜尋方法,如AutoPrompt(Shin等人,2020年)和LPAQA(Jiang等人,2020b)。 這證實了我們在第2節的直覺,即離散提示可能不是最優的 。
3.2 Fully-supervised Learning
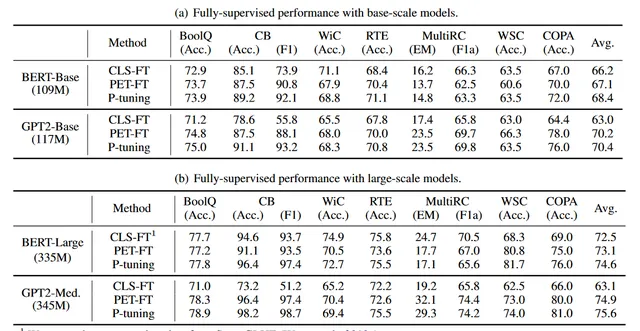
Dataset 。為了在全監督學習任務上評估P-Tuning,我們采用了SuperGLUE基準測試(Wang等人,2019b年),它包含8個具有挑戰性的自然語言理解(NLU)任務。我們關註其中的7個,因為ReCoRD(Zhang等人,2018年)任務不采用離散提示,因此P-Tuning不直接適用。這些任務包括問答(BoolQ(Clark等人,2019a年)和MultiRC(Khashabi等人,2018年))、文本蘊含(CB(De Marneffe等人,2019年)和RTE(Dagan等人,2005年))、共指消解(WiC(Pilehvar和Camacho-Collados,2018年))、因果推理(COPA(Roemmele等人,2011年))和詞義消歧(WSC(Levesque等人,2012年))。
Comparison methods .我們在GPT和BERT這兩種單向和雙向的預訓練模型上進行了P-Tuning的實驗。我們包括了四種變體:BERT-Base、BERT-Large、GPT2-Base和GPT-medium。對於每個模型,我們比較了標準分類微調、PET(Schick和Schütze,2020年)(一種基於手動離散提示的典型微調方法)以及我們的P-Tuning。
Configuration . 我們使用與(Wang等人,2019b年)相同的度量標準。對於全監督學習,我們使用大型訓練集對預訓練模型進行微調,並使用開發集進行超參數和模型選擇。具體來說,我們使用AdamW最佳化器,其學習率呈線性衰減進行訓練。我們使用的學習率為{1e-5, 2e-5, 3e-5},批次大小為{16, 32},預熱比率為{0.0, 0.05, 0.1}。對於小數據集(即COPA, WSC, CB, RTE),我們對預訓練模型進行20個周期的微調。對於較大的數據集(即WiC, BoolQ, MultiRC),我們將訓練周期數減少到10,因為模型更早地收斂。使用早停法(early stopping)來避免過擬合訓練數據。
全監督學習的主要結果在表4中展示。我們觀察到P-Tuning能夠提升BERT和GPT在全監督學習效能上的提升。
(1) 具體來說,在BERT-Base模型上,P-Tuning在7個任務中的5個上取得了最佳效能,而在BERT-Large模型上,P-Tuning在7個任務中的4個上超越了其他方法。例外的是WiC和MultiRC,這兩個任務都有相對較大的訓練集。我們發現在這種高資源任務上,P-Tuning可能不會比CLS-FT獲得更大的提升,而在低資源任務上獲益更多。平均來看,P-Tuning在考慮的基線上有所改進。
(2) 在GPT2-Base和GPT2-Medium模型上,P-Tuning在所有任務上一致地取得了最佳效能。
3.3 Few-Shot Learning
盡管GPT-3在使用手工制作的提示時展示了不錯的少樣本學習能力,它在一些具有挑戰性的任務上(例如,自然語言推理)仍然存在困難(Brown等人,2020年)。我們受到啟發,想要研究P-Tuning是否也能提高預訓練模型在這些具有挑戰性任務上的少樣本學習效能。
Few-shot Evaluation. 少樣本學習效能對許多因素都很敏感(例如,訓練樣本的順序、隨機種子和提示模式),因此存在很大的變異數(Zhao等人,2021a;Lu等人,2021;Zhang等人,2020)。因此,少樣本評估策略應確保改進確實來自於方法的改進而不是變異數。為此,我們遵循FewNLU評估程式(Zheng等人,2021),該程式已經解決了並處理了這個問題。 具體來說,我們使用隨機數據分割,在一個小的標記集上僅進行模型選擇,以防止對大型開發集的過擬合 。
Dataset 。我們使用少樣本SuperGLUE(也稱為FewGLUE)基準測試(Schick和Schütze,2020年),並按照先前工作(Zheng等人,2021年)中的數據分割構造設定進行操作。
Baseline and Hyper-parameter 。在少樣本學習中,我們再次將P-Tuning與PET(Schick和Schütze,2020年)進行比較,PET在一些任務上被證明優於GPT-3。與(Schick和Schütze,2020年)類似,我們使用ALBERT-xxLarge作為基礎模型。對於PET和P-Tuning共享的超參數(例如,學習率、最大訓練步數、評估頻率),我們使用相同的搜尋空間進行公平比較。具體來說,我們在{1e-5, 2e-5}中搜尋學習率,在{250, 500}中搜尋最大訓練步數,在{0.02, 0.04}中搜尋評估頻率。
Construction of Prompt Patterns 。對於PET,我們使用了Schick和Schütze(2020年)報告的相同手動提示。在為P-Tuning構建提示模式時,基於與PET相同的手動提示,我們在不同位置插入不同數量的連續提示標記,從而制定了一系列模式候選。然後我們使用FewNLU(Zheng等人,2021年)的驗證策略為P-Tuning選擇最佳模式。我們還在§3.3.3中對連續提示標記的數量和位置進行了進一步分析。
Few-Shot Performance 。表5展示了少樣本學習的主要結果。我們發現,在ALBERT模型上,P-Tuning平均比PET高出1個多百分點。它比PromptTuning高出超過13個百分點。這證明了透過自動學習連續提示標記,預訓練模型能夠在NLU任務上實作更好的少樣本學習效能。

Type of Prompt Encoder 。先前的工作(Shin等人,2020年)提出簡單地使用一個多層感知器(MLP)作為提示編碼器,我們對提示編碼器的選擇進行了進一步的消融分析,結果如表8所示。我們考慮了長短期記憶網絡(LSTM)、多層感知器(MLP)和直接最佳化詞嵌入(EMB)(即,我們直接最佳化詞嵌入而不使用額外的參數)。從結果中, 我們可以看到LSTM、MLP和EMB都可以作為提示編碼器使用。結果顯示LSTM和MLP通常在這些任務上表現良好,而EMB不穩定,在某些任務上(例如WiC和CB)可能大幅落後於另外兩種方法。總結來說,當處理新任務時,LSTM和MLP都應被考慮在內 。

Location of Prompt Tokens 。為了研究在哪個位置插入連續提示標記,我們進行了如表7所示的實驗。從結果中,我們有以下發現:
1. 透過比較#1(或#2)與#3(或#4), 我們發現如果我們在不分割句子的位置插入連續提示標記會更好 。例如,在案例#1中,「[P]」打破了句子「[Hypothesis]?」的完整性,而在案例#3中,「[P]」位於句子之間。
2. 透過比較#2(或#3)與#4,我們發現對於放置在輸入邊緣或中間沒有特別的偏好。
3. 建議編寫一些模式候選項,然後從中為每個任務搜尋最佳選項。

Number of Prompt Tokens 。我們還研究了提示標記數量的影響,並在表7中展示了結果。透過比較#3、#6、#7和#8, 我們可以得出結論,提示標記的數量對少樣本效能有很大的影響。然而,並不是說提示標記的數量越多越好。我們推測,由於訓練數據有限,當過度增加連續提示標記的數量時,學習參數變得困難。在實踐中,建議透過模型選擇來尋找最佳的提示標記數量 。

3.4 Stabilizing Language Model Adaptation
在上述部份中,我們已經展示了P-Tuning在多個設定中的效能改進。現在我們展示結果以證明P-Tuning還穩定了語言模型的適應力;即減少了不同提示之間的差異。正如我們在表1中所展示的,手動提示對效能有很大的影響。當涉及到少樣本學習時,由於少樣本學習的敏感性(Zheng等人,2021年),不同提示之間的效能差距尤為明顯。表6的結果顯示,P-Tuning提高了表現最差的模式(例如,P#5)的效能,並在多個模式上實作了較小的標準偏差。 與PET-FT相比,P-Tuning在選擇模式方面的穩定性得到了提高 。
在LAMA上,我們觀察到了一個類似的現象:盡管手動提示通常會得到相當不穩定的結果,但在手動提示之上添加可訓練的連續提示可以穩定它們的效能,將標準差從10.1降低到0.46 。
4 Related work
Language Model Prompting 。GPT-3(Brown等人,2020年)使用上下文範例(Liu等人,2021年;Zhao等人,2021b)作為一種提示方式,將知識從預訓練轉移到下遊任務。Schick和Schütze(2020年)提議使用填空模式,這消除了掩碼標記是句子最後一個標記的約束。這進一步縮小了預訓練和下遊任務之間的差距。為了改進NLU的提示,最近的研究工作提出了透過挖掘訓練語料庫(Jiang等人,2020b)、基於梯度的搜尋(Shin等人,2020年)或使用預訓練的生成模型(Gao等人,2020年)自動搜尋高效能提示的方法。我們的方法與這些先前的工作不同,我們采用了連續提示嵌入,在我們的實驗中發現這些嵌入與離散提示互為補充。
最近,一些並列的研究工作也提出了使用連續提示。 Prefix-tuning(Li和Liang,2021年)在每層的序列開頭添加連續提示。與我們的工作不同,Prefix-tuning針對的是自然語言生成任務 。
在自然語言理解(NLU)領域,一些並列的方法基於連續提示被提出,專註於改進知識探測(Qin和Eisner,2021年;Zhong等人,2021年)。Lester等人(2021年)展示了, 使用大型預訓練模型時,僅透過調整連續提示並凍結語言模型就能達到與全模型調整相當的效能 。
與這些在自然語言理解(NLU)上的並列工作相比, P-Tuning得出了一個獨特的結論:連續提示能夠改善效能,並在少樣本和全監督的設定下,無論是凍結還是微調模型,都能穩定訓練 。例如,沒有並列的工作表明連續提示能夠提高微調語言模型的效能。從技術上講,P-Tuning還有幾個獨特的設計,如使用混合連續-離散提示,並采用提示編碼器。
Knowledge in Language Models .自我監督學習(Self-supervised)的預訓練語言模型(Han等人,2021年),包括GPT(Radford等人,2019年)、BERT(Devlin等人,2018年)、XLNet(Yang等人,2019年)、RoBERTa(Liu等人,2019年)被觀察到不僅學習了上下文化的文本表示,還學習了語言和世界知識。Hewitt和Manning(2019年)展示了語言模型產生的上下文化表示可以在嵌入空間中形成一個解析樹。
Vig(2019年);Clark等人(2019b)研究了變換器內的多頭註意力模式,並行現某些註意力頭可能對應於某些語法功能,包括共指和名詞修飾語。LAMA(Petroni等人,2019年,2020年)提出了LAMA任務,該任務利用完形填空測試來預測知識庫中的事實三元組,以檢驗語言模型記憶單標記格式答案的能力。在(Wang等人,2020年)中,作者調查了註意力矩陣,以尋找上下文中包含的知識三元組的證據。Jiang等人(2020a)基於LAMA開發了一個多標記事實檢索數據集。
5 Conclusions
在本文中,我們介紹了一種名為P-Tuning的方法,該方法將連續提示與離散提示連線使用。P-Tuning提高了預訓練語言模型適應力的效能並穩定了訓練。在少樣本和全監督的設定下,P-Tuning對經過微調和凍結的語言模型都同樣有效 。
6 解疑
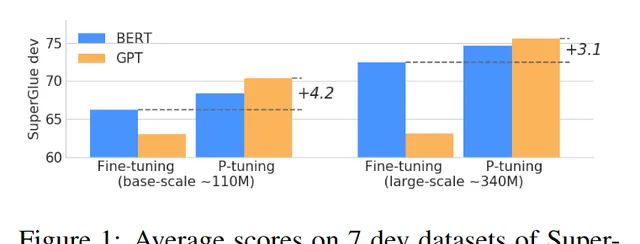
Figure 1 說明了什麽?
Figure 1 展示了使用 P-Tuning 方法在 SuperGLUE 開發數據集上的平均分數。SuperGLUE 是一個包含多個自然語言理解任務的數據集,用於評估模型在這些任務上的表現。
從 Figure 1 的描述來看,它沒有直接給出圖表的具體數據點或趨勢圖,而是提到了 P-Tuning 在 SuperGLUE 數據集上的套用情況。根據提供的資訊,我們可以推斷出以下幾點:
P-Tuning 的效果 :P-Tuning 不僅穩定了訓練過程,而且還顯著提高了模型在多種 NLU 任務上的表現,包括 LAMA 和 SuperGLUE。
離散提示的問題 :離散提示(即手動編寫的提示樣版)容易受到不穩定性的影響,即改變提示中的單個詞可能會導致效能大幅下降。例如,當使用一個固定的模型時,如果將提示從「[X] is located in [Y]」改為「[X] is located in which country? In [Y]」,準確率會從 31.3 提高到 51.1,這表明即使是微小的變化也會引起效能的巨大波動。
P-Tuning 的作用 :P-Tuning 透過引入可訓練的連續提示嵌入來解決上述問題,這些嵌入與離散提示相結合,然後作為輸入餵給語言模型。透過這種方式,連續提示可以透過反向傳播進行更新,從而最佳化特定任務的目標。這種方法不僅減少了離散提示之間效能的差異,還提高了整體的效能。
因此,Figure 1 可能展示了在不同的提示變化下,P-Tuning 如何幫助穩定模型的表現,並且提高了模型在 SuperGLUE 的各個子任務上的平均得分。
Figure 2 說明了什麽?
Figure 2 透過兩個子圖(a)和(b)說明了如何使用不同的方法來生成提示(prompt),並解釋了P-Tuning是如何工作的。
子圖 (a) - 離散提示搜尋(Discrete Prompt Search)
這個子圖展示了一個典型的離散提示搜尋過程。在這個過程中,提示生成器只接收離散獎勵,即基於模型對特定輸入的預測是否正確來更新提示。具體來說:
藍色區域表示上下文("Britain");
紅色區域表示目標("[MASK]");
橙色區域代表需要最佳化的提示部份。
離散提示搜尋的過程通常涉及手動建立一系列候選提示,然後選擇最優的一個。
子圖 (b) - P-Tuning
這個子圖解釋了P-Tuning的工作原理。與離散提示搜尋不同,P-Tuning使用的是連續提示嵌入,這意味著提示可以被最佳化為一個連續值,而不是固定的一組離散選項。具體來說:
連續提示嵌入和提示編碼器可以以可微分的方式進行最佳化;
提示樣版由連續提示嵌入組成,這些嵌入透過一個對映函數\(f\)轉換成模型輸入;
對映函數\(f\)將連續提示嵌入\([P_i]\)對映到模型輸入\(h_i\)。
P-Tuning的關鍵優勢在於它可以更方便地建模不同提示嵌入之間的依賴關系,並且可以透過反向傳播來最佳化提示嵌入,從而提高模型在特定任務上的效能。
總結
離散提示搜尋 :這種方法基於離散獎勵進行提示最佳化,可能存在不穩定性,因為提示的選擇是基於離散選項的。
P-Tuning :這種方法透過使用連續提示嵌入和一個對映函數來最佳化提示,從而提高了模型的效能,並且在訓練過程中更加穩定。
透過使用P-Tuning,研究人員能夠在多個自然語言理解任務上獲得更好的效能,同時減少由於離散提示選擇帶來的不穩定性。
P-Tuning具體使用範例:
為了更好地理解P-Tuning及其如何改進自然語言理解(NLU)任務中的提示(prompting)機制,我們可以考慮一個具體的例子。
原始的離散提示方法
假設我們有一個自然語言推理(NLI)任務,其中給定一對句子(前提和假設),模型需要判斷前提是否支持假設。例如,給定的前提句子是「John is reading a book.」,假設句子是「John is reading.」,我們需要判斷前提是否支持假設。
離散提示的例子
一個簡單的離散提示可能設計為:「[Premise] therefore [Hypothesis]?」。如果使用一個具體的例子,「John is reading a book. therefore John is reading?」。在這種情況下,模型會預測問號後面的位置(也就是標簽位置)的答案。
P-Tuning方法
P-Tuning引入了連續提示嵌入,這些嵌入可以被最佳化以改善模型的效能。我們可以在原始的離散提示中添加連續提示令牌,例如「[Premise] [P] therefore [Hypothesis]?」,其中[P]代表一個或多個連續提示令牌。
構造連續提示
選擇基線模型 :使用ALBERT-xxLarge作為基礎模型。
構建提示模式 :基於手動編寫的離散提示「[Premise] therefore [Hypothesis]?」,我們在其中插入不同數量的連續提示令牌[P],形成多個候選模式。
超參數設定 :對於學習率,最大訓練步數以及評估頻率等共享超參數,使用相同的搜尋空間,比如學習率在{1e−5, 2e−5}之間,最大訓練步數在{250, 500}之間,評估頻率在{0.02, 0.04}之間。
驗證策略 :使用隨機數據劃分來進行模型選擇,僅在一個小的標記數據集上進行,以避免在大的驗證集上過擬合。
選擇最佳模式 :從多個候選模式中選擇最佳模式,這通常透過在驗證集上進行效能測試來完成。
最佳化過程
連續提示嵌入初始化後,它們成為可訓練的參數,可以隨模型一起進行最佳化。
在訓練過程中,連續提示嵌入透過反向傳播更新,以最小化損失函數。
這種最佳化過程有助於模型更好地適應任務,即使是在數據量較小的情況下。
實驗結果
提高效能 :在多項NLU任務中,如SuperGLUE基準測試上,P-Tuning顯著提高了模型的表現。特別是在少量數據(few-shot)場景下,P-Tuning相比其他方法(如PET)取得了超過1點的平均效能提升,相比於PromptTuning則提高了超過13點。
增強穩定性 :P-Tuning不僅提高了效能,還減少了不同離散提示間的效能差異。例如,在SuperGLUE數據集上,P-Tuning能夠提高最差表現模式的效能,並且在不同模式間實作了更小的標準偏差。
位置影響 :實驗發現,將連續提示令牌放置在不會打斷句子完整性的地方效果更好。另外,連續提示令牌放置在輸入序列的開頭還是中間沒有明顯偏好。
提示數量的影響 :連續提示令牌的數量對few-shot效能有重要影響。然而,並不是提示令牌越多越好;過多的連續提示令牌可能會導致訓練困難,尤其是在數據有限的情況下。
綜上所述,P-Tuning透過引入連續提示嵌入解決了離散提示的不穩定性問題,並透過實驗驗證了其在NLU任務上的有效性。











