來源:市場資訊
(報告出品方/作者:華泰證券,謝春生、袁澤世)
大模型復盤:全球格局與模型特點基本明晰
2023 年是大模型(LLM)技術和套用快速叠代的一年。重要催化劑是 22 年 11 月底釋出的 ChatGPT。ChatGPT 雖然在技術基座上是之前已經問世的 GPT-3 和 InstructGPT,但它給 了全球使用者一個與 LLM 互動的自然語言界面,極大拉近了 LLM 與普通大眾的距離,引起了 資本的關註,成為大模型技術加速叠代的導火索。微軟、Google、Meta、Nvidia 等龍頭大 廠,OpenAI、Anthropic、Mistra 等初創公司,以及史丹佛、清華、上交等學術機構,引領 了 23 年的 LLM 發展。LLM 技術也從模型本身擴充套件到端側、AI Agent、具身智能等更廣泛 的領域。此外,在大模型技術套用上,一方面,雲 SaaS 廠商將 AI 賦能於傳統 SaaS 軟件, 如微軟 Copilot 和 Adobe Firefly;另一方面,以 AI 為核心的套用興起,如 AI 搜尋 Perplexity, 文生圖 Stable Diffusion、Midjourney、DALL-E,文生影片 Runway、Pika、Sora 等。
全球格局:海外技術收斂,國內百花齊放
海外閉源大模型已經形成 OpenAI 為首,Google、Anthropic 等模型緊隨的格局。閉源模 型中,雖然 Google Gemini 和 Anthropic 分別於 24 年 2 月和 3 月更新了 1.5 Pro(Gemini 1.0 是在 23 年 12 月)和 Claude 3,在上下文長度、數學、編碼、專業領域等能力測評上超過 了 GPT-4,但是考慮到:1)GPT-4 和 4 Turbo 實質上為 23 年 3 月 GPT-4 系列的叠代,比 Gemini 和 Claude 3 早推出近一年;2)ChatGPT 對多模態、App 語音互動、工具呼叫(聯 網、高級數據分析)、智能體(GPTs)等能力進行了有機整合;3)根據 UC 柏克萊大學 Chatbot Arena 的榜單(該榜單為使用者盲測模型評價的結果,較為客觀),GPT-4 的使用者體驗仍是頭 部頂尖水平;4)GPT-5 已在訓練中;5)GPT-4o 的端到端能力再次提升。因此,我們認 為,OpenAI 的技術仍處於暫時領先。
Meta 的 Llama 系列作為開源模型,具有格局上的特殊性和分界性。海外模型廠商如果在 模型效能上無法超越同代的開源 Llama 模型(據 Meta 官網 4 月 18 日資訊,Llama 3 的 8B 和 70B 先行版小模型已經釋出,最大的 400B 參數正在訓練),則很難在海外基礎模型中占 據一席之地,除非模型具有差異化套用場景,典型的如陪伴類套用 Character.ai。此外,除 了頭部大參數模型,能夠超過同代 Llama 的較小參數或者有獨特使用體驗的模型,也會得 到使用者青睞,典型的如:1)馬斯克旗下 xAI 的 Grok-1(已開源)、Grok-1.5(未開源),能 夠獨家使用 X 平台上的數據,較好的響應使用者即時資訊查詢需求;2)法國大模型初創公司 Mistral,開源了 Mistral 7B、Mixtral 8x7B-MoE 小模型,適配算力受限的端側等平台,隨後 又轉入閉源模型,更新了效能更強的 Mistral-medium 和 large,並與微軟合作,在 Azure 上為使用者提供 API。

國內模型百花齊放,互聯網大廠、初創公司、科技企業均有代表性模型產品。國內模型技 術辨識度不高,據 SuperCLUE 測評結果榜單,頭部的國內模型在得分上相差並不顯著。在 國內主流的模型中,互聯網廠商和科技企業在大模型上起步較早,如百度在 GPT-4 釋出的 後一天即 23 年 3 月 15 日釋出文心一言,23 年 3 月 29 日 360 智腦 1.0 釋出,23 年 4 月通 義千問上線,23 年 5 月 6 日訊飛星火 1.0 釋出。進入 24 年,初創公司的大模型產品得到 了更廣泛的關註,例如 24 年 3 月月之暗面更新 Kimi 智能助手 200 萬字的上下文支持能力, 直接引發了百度、360 等廠商對長上下文的適配。同月階躍星辰 STEP 模型釋出,其 STEP 2 宣稱為萬億參數 MoE 模型,直接對標 GPT-4 的參數(一般認為是 1.8 T 參數的 MoE), 在大多數國內模型以千億參數為主的環境下,將參數量率先提升到萬億級別。4 月,MiniMax 也釋出了萬億參數 MoE 架構的 abab 6.5。
特點#1:大模型與小模型同步發展
根據 Scaling Law,更大參數、更多數據和更多算力能夠得到更好的模型智能。2020 年 1 月,OpenAI 釋出論文【Scaling Laws for Neural Language Models】,奠定了 Scaling Law (縮放定律)的基礎,為後續 GPT 的叠代指明了大參數、大算力方向。Scaling Laws 是一 種經驗性質的結論,並非完備的數學理論推導。OpenAI 在 decoder-only Transformer 架構 的特定配置下進行了詳盡的實驗,摸清了模型效能(用模型 Loss 衡量,Loss 越小效能越 好)與參數(N)、數據集 token(D)和投入訓練算力(C)的關系——N、D、C 是影響 Loss 最顯著的因素,三者增加將帶來更好的模型效能。Transformer 架構中的層數、向量 寬度等其它參數並不構成主要影響因素。
根據 Scaling Law 論文,可以用 6ND 來估算模型所需要的訓練算力(以 FLOPs 為單位)。 Transformer 架構涉及了多種參數,包括層數(nlayer)、殘留誤差流維數(dmodel)、前饋層維數 (dff)、註意力機制輸出維數(dattn)、每層註意力頭數(nhead)、輸入上下文 token 數(nctx) 等。在訓練數據進入 Transformer 解碼器後,每一步運算都會涉及相應的參數,並對應有需 求的算力。據 OpenAI 測算,單個 token 訓練時在 Transformer 解碼器中正向傳播,所需 FLOPs(每秒浮點運算數)為 2N+2nlayernctxdattn。由於在論文寫作於 2020 年,當時模型上 下文長度 nctx並不長,滿足 dmodel> nctx/12,因此 2N+2nlayernctxdattn可約等於 2N。在訓練中 反向傳播時,所需算力約為正向的 2 倍(即 4N),因此單個 token 訓練全過程需要算力總 共 6N FLOPs,考慮全部的訓練 token 數 D,共需算力近似 6ND FLOPs。在推理時,為了 計算方便,通常采用正向訓練算力需求 2ND 來計算所需 FLOPs。 值得註意的是,目前 Claude 3、Gemini 1.5 Pro、Kimi 智能助手等大模型支持的上下文 長度遠超當年,dmodel > nctx/12 不再滿足,因此 2nlayernctxdattn 應予以考慮。即上下文長度 更長時,訓練需求的算力是高於 6ND 的。
在 Scaling Law 指導下,OpenAI 延續了大參數模型的路線。2020 年 1 月 Scaling Laws 論文發表後不久,2020 年 5 月 GPT-3 系列問世,將參數從 GPT-2 的 15 億提升到 1750 億, 訓練數據大小從 40G 提升到 570G(數據處理後,處理前數據量更大),分別提升了 100+ 倍和 14 倍。到了 GPT-4,雖然 OpenAI 官方未公布參數大小,但是根據 SemiAnalysis 的 資訊,目前業界基本預設了 GPT-4 是 1.8 萬億參數的 MoE 模型,訓練數據集包含約 13 萬 億個 token,使用了約 25,000 個 A100 GPU,訓練了 90 到 100 天,參數量、數據集和訓 練所需算力相比 GPT-3 又有數量級的提升。OpenAI 在不斷踐行 Scaling Law,將模型的參 數以及模型的智能提升到新的層級。
從 Google 和 Anthropic 的模型布局看,印證了大參數能帶來模型效能的提升。Google 的 Gemini 和 Anthropic 的 Claude 3 系列均分別提供了「大中小」三款模型,雖然兩家廠商並 未給出模型參數、訓練數據細節,但是均表示更大的模型智能更強, 推理速度相對較慢,所需的算力和訓練數據也相應更多,是對 Scaling Law 的印證。此外, 我們梳理了全球主流模型廠商的參數情況,同樣發現旗艦模型的參數量仍在變大。
我們認為,全球頭部閉源模型的參數目前呈現的規律是:跨代際更新,模型參數進一步加 大;同代際更新,隨著模型技術架構最佳化和軟硬件資源協同能力提高,在模型性效能不降 的情況下,參數或做的更小。Google 和 OpenAI 的最新模型都呈現了這個趨勢。24 年 5 月 13 日,OpenAI 釋出了 GPT-4o 模型,在多模態端到端的架構基礎上,實作了更快的推 理速度,以及相比於 GPT-4 Turbo 50%的成本下降,我們推測其模型參數或在下降。5 月 14 日 Google 釋出了 Gemini 1.5 Flash,官方明確指出 Flash 是在 Pro 的基礎上,透過線上 蒸餾的方式得到,即 Flash 的參數小於 Pro。
大參數並不是唯一選擇,小參數模型更好適配了終端算力受限的場景。Google 的 Gemini 系列是典型代表,其最小的 Nano 包括 1.8B 和 3.25B 兩個版本,並且已經在其 Pixel 8 Pro 和三星 Galaxy S24 上實作部署,取得了不錯的終端 AI 效果。此外,Google 在 24 年 2 月 開源了輕量級、高效能 Gemma(2B 和 7B 兩種參數版本),與 Gemini 模型技術同源,支 持商用。Google 指出,預訓練和指令調整的 Gemma 模型可以在筆記電腦、工作站、物 聯網、流動通訊器材或 Google Cloud 上執行。微軟同樣在 23 年 11 月的 Ignite 大會上提出了 SLM(小語言模型)路線,並將旗下的 Phi 模型升級到 Phi-2,參數大小僅 2.7B,效能超過 7B 參數的 Llama 2。24 年 4 月 Phi-3 釋出,最小參數僅 3.8B,其效能超過參數量大其兩倍 的模型,5 月微軟 Build 大會上,Phi-3 系列參數為 7B 和 14B 的模型釋出。
Mistral釋出的 7B和 8x7B 模型也是開源小模型的典型代表。法國人工智能初創公司 Mistral AI 成立於 2023 年 5 月,其高管來自 DeepMind、Facebook 等核心 AI 團隊。2023 年 9 月 和 12 月,Mistral 分別開源了 Mistral-7B(73 億參數)和 Mixtral-8x7B-MoE(467 億參數, 8 個 專 家 )。 Mistral-7B 在多項測試基準中優於 130 億 參 數 的 Llama 2-13B 。 Mixtral-8x7B-MoE 在大多數測試基準上超過 Llama 2,且推理速度提高了 6 倍;與 GPT-3.5 相比,也能在多項測評基準上達到或超過 GPT-3.5 水平。在小參數開源模型中,Mistral 的 競爭力很強。Mistral 推出的平台服務 La plateforme 也支持模型的 API 呼叫。
小參數模型的訓練算力需求仍在變大,定性看,訓推算力需求空間可觀。雖然模型參數較 小,但是為了提高效能,模型廠商均投入了大量的訓練數據。如Phi-2有1.4T訓練數據tokens, Phi-3 為 3.3T tokens,Gemma 為 6T/2T tokens(分別對應 7B 和 2B 模型)。24 年 4 月 Meta 率先開源的兩個 Llama 3 系列小模型 8B 和 70B,對應的訓練 token 已經達到了 15T,並且 Meta 表示,即使已經使用了 15T 的訓練數據,仍能看到模型效能的持續提升。我們認為, 雖然單個小模型相比於大模型訓練算力需求並不大,但是一方面小模型本身的訓練數據集 在不斷增加,另一方面,未來在終端 AI PC 和手機,甚至車機和機器人上,都有可能部署 終端模型,因此定性看,小模型總體的訓練和推理算力需求仍然可觀。
特點#2:原生多模態逐步成為頭部大模型的標配能力
OpenAI 的 GPT 系列在全球閉源大語言模型廠商中率先適配多模態能力。拋開專門的多模 態模型/產品,如文生圖 Stable Diffusion / Midjourney / DALL-E,文生影片 Sora / Runway / Pika / Stable Video Diffusion 外,在頭部閉源 LLM 中,OpenAI 的 GPT-4 最先引入多模態 能力。23 年 3 月,GPT-4 技術報告中即展示了 GPT-4 支持文本和影像兩種模態作為輸入。 9 月 25 日,OpenAI 官方 Blog 宣布 GPT-4 的 Vision(視覺)能力上線,支持多圖和文本的 交錯推理,同時宣布 ChatGPT App 支持語音互動(語音轉文本模型為 Whisper,文本轉語 音模型為 Voice Engine)。23 年 10 月 19 日,OpenAI 旗下新一代文生圖模型 DALL-E 3 在 ChatGPT 中實裝上線,可以透過與 ChatGPT 對話來實作文生圖。
透過模型間非端到端協作,ChatGPT 網頁端和 App 實作了完備的多模態能力支持。隨著 OpenAI 的 GPT-4V、DALL-E 3、Whisper、Voice Engine 等模型的上線和更新,OpenAI 將所有的模型協同整合成 pipeline 形式,使得 ChatGPT 能夠實作:1)推理文本;2)理解 影像;3)生成影像;4)語音轉文本;5)文本轉語音。ChatGPT 成為 2023 年支持模態最 多的 LLM 產品。
Google 從 PaLM 模型開始即在探索 LLM 向多模態領域的拓展。PaLM 是 Google Gemini 的前一代主要模型系列。2022 年 4 月,Google 的 PaLM 模型問世。PaLM 自身為大語言 模型,僅支持文本模態,但是在 PaLM 的能力之上,Google 將影像、機器人具身數據轉化 為文本 token 形式,訓練出多模態模型 PaLM-E。此外,還將音訊模態與 PaLM 模型結合, 釋出 AudioPaLM。在醫療領域,Google 先基於 PaLM 訓練出醫療語言模型 Med-PaLM, 隨後在 Med-PaLM 基礎上將醫療影像知識增加到訓練數據中,訓練出醫療領域多模態模型 Med-PaLM M。
Gemini 模型問世後,端到端原生多模態能力成為頭部模型廠商的「標配」能力。2023 年 5 月的 I/O 大會上,Google 宣布了下一代模型 Gemini,但未透露細節。12 月,Gemini 1.0 模型釋出,配備了 Ultra/Pro/Nano 三種參數大小依次遞減的型號。Gemini 同樣支持文本、 影像、影片、音訊等多模態,但是其範式和 OpenAI 的 ChatGPT 有很大區別:ChatGPT 屬於多種不同模型的集合,每個模型負責不同的模態,結果可以串聯;而 Gemini 具備端 到端的原生多模態能力,Gemini 模型自身可以處理全部支持的模態。據 The Decoder 信 息,23 年 OpenAI 內部已經在考慮一種代號為「Gobi」的新模型,該模型同樣從一開始就 被設計為原生多模態。我們認為,這種端到端的原生多模態範式將成為未來頭部大模型廠 商實作多模態的主流範式。
Anthropic Claude 模型多模態能力「雖遲但到」,Claude 3 模型科研能力優異。Anthropic 的 Claude 系列模型在 2024 年 3 月更新到 Gen 3 後,全系適配了多模態影像辨識能力,並 在科學圖表辨識上大幅超越 GPT-4 和 Gemini 1.0 Ultra。此外,Claude 3 Haiku 有著優秀 的成本控制和推理速度優勢,據 Anthropic 官方,Haiku 的速度是同類產品的三倍,能夠在 一秒內處理約 30 頁的內容(21K token),使企業能夠快速分析大量文件,例如季度備案、 合約或法律案件,且一美元就能分析 400 個最高法院案例或 2500 張圖片。
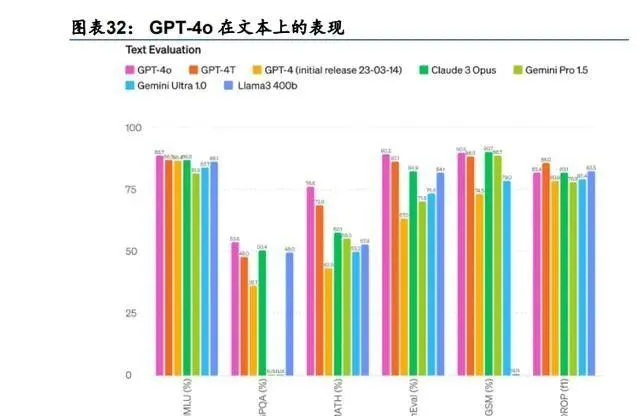
GPT-4o 在 GPT-5 釋出之前實作了端到端的多模態支持,驗證了原生多模態的技術趨勢。 24 年 5 月 14 日 Google I/O 大會前夕,OpenAI 釋出了新版模型 GPT-4o(omni),棄用了 之前 ChatGPT 拼接 GPT-4V、Whisper、DALL-E 的非端到端模式,統一了文本、影像、音 頻和影片模態,以端到端的方式,實作了輸入文本、影像、音訊和影片,輸出文本、影像 和音訊,追上了 Google Gemini 的原生多模態進度,並且模態支持更加全面(4o 支持音訊 輸出,Gemini 不支持)。4o 在文本、影像、音訊等各項指標上均超越了同等級現有模型。
Claude 3.5 Sonnet增強了UI互動體驗,與GPT-4o的語音互動相比朝著差異化路徑發展。 6 月 21 日,Anthropic 宣布了 Claude 3.5 Sonnet 模型,在價格相比於 Claude 3 Sonnet 不 變的情況下,在研究生水平推理、程式碼等能力(文本層面),以及視覺數學推理、圖表問答 等能力(視覺層面)上超過了 GPT-4o。Claude 3.5 Sonnet 另一個突出的效能是 UI 互動能 力的增強,主要由 Artifacts 功能實作。當使用者要求 Claude 生成程式碼片段、文本文件或網站 設計等內容時,對話旁邊的專用視窗中將即時出現相應的展示,例如編寫的遊戲、網頁等。 Anthropic 指出,Artifacts 互動方式未來將會從個人拓展到團隊和整個組織協作,將知識、 文件和正在進行的工作集中在一個共享空間中。我們認為,GPT-4o 和 Claude 3.5 Sonnet 均在最佳化使用者互動上下功夫,但是兩者的方向存在差異化,GPT-4o 更註重語音互動,而 Sonnet 更註重 UI 界面互動。
國內模型廠商積極適配多模態,以影像理解能力為主。在 GPT-4 宣布支持多模態後,國內 廠商也積極適配多模態圖片的辨識、理解和推理。截至 2024 年 4 月,國產主流模型多模態 支持情況如下:1)百度文心一言,說圖解畫支持單張影像推理,支持影像生成。2)阿裏 通義千問,支持單張圖片推理,支持影像生成。阿裏開源的模型 Qwen-VL 支持影像推理。 3)騰訊混元助手,支持影像生成,以及單張影像推理。3)訊飛星火,支持單張影像推理, 支持影像生成。4)智譜 ChatGLM 4,支持單張影像推理,支持影像生成。5)360 智腦, 支持影像生成。6)字節豆包,支持影像生成。7)Kimi 智能助手,支持圖片中的文字辨識。 月之暗面官方表示 24 年下半年將支持多模態推理。8)階躍星辰基於 Step 模型的助手躍問, 支持多圖推理。
特點#3:上下文作為 LLM 的記憶體,是實作模型通用化的關鍵
國外 LLM 廠商較早實作長上下文,國內廠商透過長上下文找到差異化有利競爭。國外較早 實作長上下文的廠商是 Anthropic,旗下 Claude 模型在 23 年 11 月,將支持的上下文從 100K tokens 提升到 200K,同時期的 GPT-4 維持在 128K。24 年 2 月,Google 更新 Gemini 到 1.5 Pro 版本,將上下文長度擴充套件到 1M(5 月更新中擴充套件到 2M),並在內部實作了 10M, 是目前已知最大上下文長度。國內方面,23 年 10 月由月之暗面釋出的 Kimi 智能助手(原 名 Kimi Chat),率先提供 20 萬字的長上下文,並在 24 年迎來了使用者存取量的大幅提升。 24 年 3 月,阿裏通義千問和 Kimi 先後宣布支持 1000 萬字和 200 萬字上下文,引發國內百 度文心一言、360 智腦等廠商紛紛跟進長上下文能力叠代。我們認為,國內 LLM 廠商以長 上下文為契機,尋找到了細分領域差異化的競爭路線,或有助於指導後續的模型叠代。
長上下文使得模型更加通用化。據月之暗面官方資訊,長上下文能夠解決 90%的模型微調 客製問題。對於短上下文模型,在執行具體的下遊任務前,其已具備的能力往往仍有欠缺, 需要針對下遊任務進行微調。微調的基本步驟包括數據集的準備、微調訓練等,中間可能 還涉及微調結果不理想,需要重新梳理微調過程。而上下文長度足夠的情況下,可以將數 據作為提示詞的一部份,直接用自然語言輸入給大模型,讓模型從上下文中學習,達到微 調效果,使得模型本身更具有通用性。以 Google Gemini 1.5 Pro 為例,將 250K token 的 Kalamang 語(全球使用人數小於 200 人,幾乎不存在於 LLM 的訓練集中)直接作為上下 文輸入給模型,實作了接近人類的轉譯水平。而 GPT-4 和 Claude 2.1 由於上下文支持長度 不夠,無法透過上下文學習到全部的知識。
長上下文還能很好的適配虛擬角色、開發者、AI Agent、垂類場景等需求。1)虛擬角色 Chatbot:長文本能力幫助虛擬角色記住更多的重要使用者資訊,提高使用體驗。2)開發者: 基於大模型開發劇本殺等遊戲或套用時,需要將數萬字甚至超過十萬字的劇情設定以及遊 戲規則作為 prompt 輸入,對長上下文能力有著剛性需求。3)AI Agent:Agent 智能體運 行需要自主進行多輪規劃和決策,且每步行動都可能需要參考歷史記憶資訊才能完成。因 此,短上下文會導致長流程中的資訊遺忘,長上下文是 Agent 效果的重要保障。4)垂直場 景客戶需求:對於律師、分析師、咨詢師等專業使用者群體,有較多長文本內容分析需求, 模型長上下文能力是關鍵。
實作長上下文有多種方法,最佳化 Transformer 架構模組是核心。拆解 Transformer 解碼器, 可以透過改進架構中的各個模組來實作上下文長度的拓展。1)高效註意力機制:高效的註 意力機制能夠降低計算成本,甚至實作線性時間復雜度。這樣在訓練時就可以實作更長的 序列長度,相應的推理序列長度也會更長。2)實作長期記憶:設計顯式記憶機制,如給予 外部儲存,解決上下文記憶的局限性。3)改進位置編碼 PE:對現有的位置編碼 PE 進行 改進,實作上下文外推。4)對上下文進行處理:用額外的上下文預/後處理,在已有的 LLM (視為黑盒)上改進,確保每次呼叫中給 LLM 的輸入始終滿足最大長度要求。5)其他方 法:以更廣泛的視角來增強 LLM 的有效上下文視窗,或最佳化使用現成 LLM 時的效率,例如 MoE(混合專家)、特殊的最佳化目標函數、並列策略、權重壓縮等。
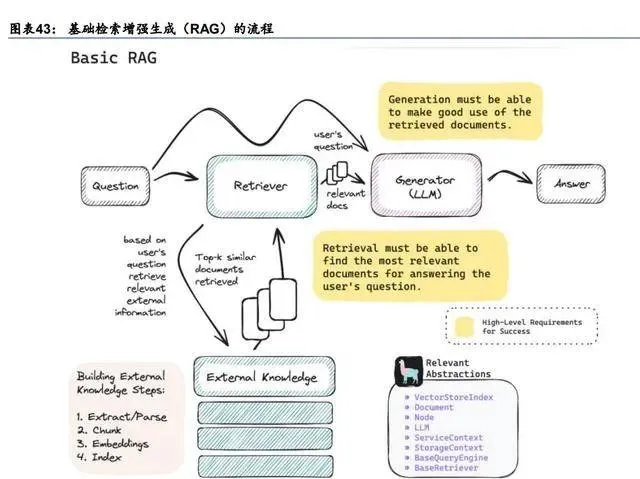
RAG 與其他長文本實作方法相比,並沒有顯著的優劣之分,要結合場景進行選擇。RAG 基本原理是,在使用者提問時,retriever(檢索器)會從外部的知識庫中檢索最相關的資訊傳 遞給大模型,作為大模型推理所需知識的補充。RAG 更像是大模型本身的「外掛」幫手。 而最佳化註意力機制等其他長上下文實作方法,則是大模型的「內生」能力,是模型本身能 夠支持輸入更長的資訊,並透過註意力機制掌握序列全域關系。「內生」似乎比「外掛」更 高級,因為模型會捕捉到使用者提出的所有歷史資訊,更適用於 C 端資訊量有限場景。但是 對於 B 端使用者,其企業 Know-How 積累量巨大,且很多知識也是結構化的 QA(如客服), 而模型上下文長度不可能無限延長(受制於演算法、算力、推理時間等各種因素),因此 RAG 這種「外掛」的形式更加適合。例如,主要面向 B 端的大模型廠商 Cohere,將 RAG 作為 模型重要能力以適配 B 端檢索場景,其 Command R+模型本身上下文長度僅 128K。 我們認為,「內生」長文本技術是從根本上解決問題,是發展趨勢,但是受制於算力等因素 (未來或將逐步解決),短期內將與 RAG 共存,選擇上取決於使用場景。
特點#4:MoE 是模型從千億到萬億參數的關鍵架構
MoE 架構有利於預訓練和推理效率的提升,方便模型 scale up 到更大的參數。據 Hugging Face 資訊,在有限的計算資源預算下,用更少的訓練步數訓練一個更大的模型,往往比用 更多的步數訓練一個較小的模型效果更佳。MoE 的一個顯著優勢是它們能夠在遠少於稠密 模型所需的計算資源下進行有效的預訓練,當計算資源有限時,MoE 可以顯著擴大模型或 數據集的規模,更快地達到稠密模型相同的質素水平。MoE 的引入使得訓練具有數千億甚 至萬億參數的模型成為可能。MoE 特點在於:1)與稠密模型相比,預訓練速度更快;2) 與具有相同參數數量的模型相比,具有更快的推理速度(因為只需要呼叫部份參數);3) 需要大量視訊記憶體,因為所有專家系統都需要載入到記憶體中,而 MoE 架構的模型參數可達到上 萬億;4)MoE 進行指令調優具有很大的潛力,方便做 Chatbot 類套用。
MoE 由稀疏 MoE 層和門控網絡/路由組成。MoE 模型仍然基於 Transformer 架構,組成部 分包括:1)稀疏 MoE 層:這些層代替了傳統 Transformer 模型中的稠密前饋網絡層,包 含若幹「專家」(例如 8、16、32 個),每個專家本身是一個獨立的神經網絡。這些專家甚 至可以是 MoE 層本身,形成層級式的 MoE 結構。稀疏性體現在模型推理時,並非所有參 數都會在處理每個輸入時被啟用或使用,而是根據輸入的特定特征或需求,只有部份參數 集合被呼叫和執行。2)門控網絡/路由:決定將使用者輸入的 tokens 發送到哪個具體的專家。 例如下圖中,「More」對應的 token 被發送到第二個專家處理,而「Parameters」送到第一 個專家。一個 token 也可以被發送到多個專家進行處理。路由器中的參數需要學習,將與 網絡的其他部份一同進行預訓練。
專家數量存在邊際遞減效應,MoE 的選擇也要考慮模型的具體套用場景。據 Hugging Face 資訊,增加更多專家可以加速模型的運算速度和推理效率,但這一提升隨著專家數量的增 加而邊際遞減,尤其是當專家數量達到 256 或 512 之後更為明顯。另外,雖然推理時只需 要啟用部份參數,但是推理前仍然需要將全量的模型參數載入到視訊記憶體中。據 Switch Transformers 的研究結果,以上特性在小規模 MoE 模型下也同樣適用。在架構的選擇上, MoE 適用於擁有多台機器(分布式)且要求高吞吐量的場景,在固定的預訓練計算資源下, 稀疏模型往往能夠實作更優的效果。在視訊記憶體較少且吞吐量要求不高的場景,傳統的稠密模 型則是更合適的選擇。
Google 是 MoE 架構的早期探索者之一,OpenAI 實作了 MoE 的商業化落地。MoE 的理 念起源於 1991 年的論文【Adaptive Mixture of Local Experts】。在 ChatGPT 問世之前, Google 已經有了較深入的 MoE 研究,典型代表是 20 年的 Gshard 和 21 年的開源 1.6 萬億 Switch-Transformer 模型。23 年 3 月 GPT-4 問世,OpenAI 繼續走了閉源路線,沒有公布 模型參數。但是據 SemiAnalysis 資訊,GPT-4 的參數約 1.8 萬億,采用 MoE 架構,專家 數為 16,每次推理呼叫兩個專家,生成 1 個 token 約啟用 2800 億參數(GPT-3 為 1750 億參數),消耗 560 TFLOPs 算力。在 GTC 2024 演講上,黃仁勛展示了 GB200 訓練 GPT 模型示意圖,給出的參數也是 GPT-MoE-1.8T,交叉印證。
Mistral 引發 MoE 關註,Google 掀起 MoE 浪潮,國內廠商跟隨釋出 MoE 模型。23 年 12 月,Mistral 開源 Mixtral-8x7B-MoE,以近 47 億的參數在多項測評基準上達到或超過 1750 億參數的 GPT-3.5 水平,引發了全球開發者對 MoE 架構的再次關註。輝達的研究主管 Jim Fan 指出 MoE 將成為未來模型發展的重要趨勢。24 年 2 月,Google 將其最先進模型 系列 Gemini 更新到 1.5 Pro,並指出架構上從稠密架構切換到 MoE 架構,實作了 1.5 Pro 模型效能的大幅提升,核心能力超過 Gemini 1.0 Ultra。國內外模型廠商隨即跟進釋出 MoE 相關模型,包括 xAI 開源的 Grok-1(23 年 10 月已實作 MoE,24 年開源)、MiniMax abab6、 Databricks DBRX、AI21 Jamba、阿裏 Qwen-1.5 MoE、昆侖萬維天工 3.0、階躍星辰 STEP 2、商湯日日新 5.0 等。
大模型展望:Scaling Law + AI Agent + 具身智能
展望 24 年及之後的大模型發展方向,我們認為,1)Scaling Law 雖然理論上有邊界,但 是實際上仍遠未達到;2)雖然有 Mamba、KAN 等新的架構挑戰 Transformer,但是 Transformer 仍是主流,短期內預期不會改變;3)以 Meta Llama 為首的開源模型陣營日 益強大,占據了整個基礎模型的超半數比重,且與閉源模型差距縮短;4)AI Agent 是實 現 AGI 的重要加速器。5)具身智能隨著與 LLM 技術的融合,將變得更加可用。
展望#1:Scaling Law 理論上有邊界,但是目前仍未到達
Scaling Law 的趨勢終將會趨於平緩,但是目前公開資訊看離該邊界尚遠。OpenAI 在 2020 年 1 月的 Scaling Law 論文中明確指出,整個研究過程中 OpenAI 在大算力、大參數和大訓 練數據情況下,並沒有發現 Scaling Law 出現邊界遞減的現象。但也提到,這個趨勢終將趨 於平緩(level off),因為自然語言具有非零熵。但是實際上,根據史丹福大學 2023 年的 AI Index 報告,2012-2023 年,頭部模型訓練消耗的算力仍然在持續增大。
可預期的時間內,Scaling Law 的上限尚未看到,self-play 是趨勢。我們認為,雖然 OpenAI 從理論上預測了 Scaling Law 的趨勢會區域平緩,但是目前全球頭部模型廠商依然遵循更大 的參數等於更高的智能。Gemini 和 Claude 3 釋出的模型產品矩陣即驗證了這一觀點,例如 更小的 Claude 3 Haiku 輸出速度快於最大的 Claude 3 Opus,價格更低,智能情況和測評 得分也更低。清華大學教授、智譜 AI 的技術牽頭人唐傑教授在 24 年 2 月北京人工智能產業創新發展大會上發表演講【ChatGLM:從大模型到 AGI 的一點思 考】,也指出了目前很多大模型還在 1000 億參數左右,「我們還遠未到 Scaling law 的盡頭, 數據量、計算量、參數量還遠遠不夠。未來的 Scaling law 還有很長遠的路要走。」此外, 唐傑教授還認為,「今年的階段性成果,是實作 GPT 到 GPT Zero 的進階,即大模型可以 自己教自己」,類似於 AlphaGo 到 Alphazero 的轉變,實作模型 self-play。
展望#2:模型幻覺短期難消除但可抑制,CoT 是典型方法
大模型的幻覺來源包括數據、訓練過程、推理過程等。LLM 的幻覺(hallucination),即 LLM 輸出內容與現實世界的事實或使用者輸入不一致,通俗說就是「一本正經胡說」。幻覺的來源 主要分為 3 類:1)與訓練數據相關的幻覺;2)與訓練過程相關的幻覺;3)與推理過程相 關的幻覺。 根據幻覺來源的不同,針對性的有各種解決方法。1)數據相關的幻覺:可以在準備數據時, 減少錯誤資訊和偏見,擴充套件數據知識邊界,減少訓練數據中的虛假相關性,或者增強 LLM 知識回憶能力,如使用思維鏈(CoT)。2)訓練過程相關的幻覺:可以避免有缺陷的模型 架構,例如改進模型架構或最佳化註意力機制;也可以透過改進人類偏好,減輕模型與人類 對齊時的奉承性。3)推理過程相關的幻覺:主要是在解碼過程中,增強解碼的事實性和忠 誠性,例如保證上下文和邏輯的一致等。
展望#3:開源模型將在未來技術生態中占據一席之地
2023 年開源模型在全球基礎模型中所占的比重大幅提高。根據史丹福大學 2023 年的 AI Index 報告,2021-2023 年全球釋出的基礎模型數量持續增多,且開源模型的占比大幅提高, 21-23 年占比分別為 33.3%、44.4%和 65.7%。此外,4 月 OpenAI CEO 和 COO 在接受訪 談時,指出「開源模型無疑將在未來的技術生態中占據一席之地。有些人會傾向於使用開 源模型,有些人則更偏好於托管服務,當然,也會有許多人選擇同時使用這兩種方式。」
Meta 持續開源 Llama 系列模型,證明了開源模型與閉源模型差距持續縮小。4 月 19 日, Llama 3-8B 和 70B 小模型釋出,支持文本輸入和輸出,架構和 Llama 2 基本類似 (Transformer decoder),上下文長度 8K,15T 訓練 token(Llama 2 是 2T)。評測結果看, Llama-70B 與 Gemini 1.5 Pro 和 Claude 3 Sonnet 相比(這兩個閉源模型參數都預期遠大 於 70B),在多語言理解、程式碼、小學數學等方面領先。Llama 3 繼續堅持開源,可商用, 但在月活超 7 億時需向 Meta 報備。根據 Mata 官方資訊,Llama 3 將開源 4000 億參數版 本,支持多模態,能力或是 GPT-4 級別。目前訓練的階段性 Llama 3-400B 已經在 MMLU 測評集(多工語言理解能力)上得分 85 左右,GPT-4 Turbo 得分是 86.4,差距很小,且 Llama 3 400B 仍將在未來幾個月的訓練中持續提升能力。基於 Llama 1 和 2 帶來的繁榮開 源模型生態,我們認為,正式版 Llama 3 釋出後,或將進一步縮小開源模型與閉源模型的 差距,甚至在某些方面繼續趕超。

大模型的開源閉源之爭尚未有定論。開源和閉源在各個領域中誰占主導,並沒有定數。復 盤來看,閉源在作業系統、瀏覽器、雲基礎設施、數據庫等領域占據了主導地位,開源在 內容管理系統、網絡伺服器等領域優勢地位明顯。反觀大模型領域,開源閉源誰將最終勝 出尚未有定論。當下,閉源模型的優勢在於:1)資源集中:大模型訓練屬於計算資源密集 型行業,在當前各大雲廠商算力儲備爬坡階段,只有閉源才能實作萬卡級別的大規模分布 式集群;2)人才集中:OpenAI、Google、Anthropic、Mata 等大模型頭部廠商,集中了目 前全球為數不多的大模型訓練人才,快速形成了頭部效應。那我們的問題是,這種優勢持 續性有多長?資源方面,未來隨著算力基礎設施的逐步完善、單位算力成本的下降、推理 占比逐步超過訓練,大廠的資源密集優勢是否還會顯著?人才方面,全球已經看準了 LLM 的方向,相關人才也在加速培養,OpenAI 的相關人才也在快速流失和叠代,人才壁壘是否 也在降低?
展望#4:數據將成為模型規模繼續擴大的瓶頸,合成數據或是關鍵
Epoch 預測,未來訓練數據的缺乏將可能減緩機器學習模型的規模擴充套件。據 Epoch 預測, 2030 年到 2050 年,將耗盡低質素語言數據的庫存;到 2026 年,將耗盡高質素語言數據的 庫存;2030 年到 2060 年,將耗盡視覺數據的庫存。由於大參數模型對數據量需求的增長, 到 2040 年,由於缺乏訓練數據,機器學習模型的擴充套件大約有 20%的可能性將顯著減慢。 值得註意的是,以上結論的前提假設是,機器學習數據使用和生產的當前趨勢將持續下去, 並且數據效率不會有重大創新(這個前提未來可能被新合成技術打破)。
合成數據是解決數據缺乏的重要途徑,但目前相關技術仍需要持續改進。理論上,數據缺 乏可以透過合成數據來解決,即 AI 模型自己生成訓練數據,例如可以使用一個 LLM 生成的 文本來訓練另一個 LLM。在 Anthropic 的 Claude 3 技術報告中,已經明確提出在訓練數據 中使用了內部生成的數據。但是目前為止,使用合成數據來訓練生成性人工智能系統的可 行性和有效性仍有待研究,有結果表明合成數據上的訓練模型存在局限性。例如 Alemohammad 發現在生成式影像模型中,如果在僅有合成數據或者真實人類數據不足的 情況下,將出現輸出影像質素的顯著下降,即模型自噬障礙(MAD)。我們認為,合成數據 是解決高質素訓練數據短缺的重要方向,隨著技術演進,目前面臨的合成數據效果邊際遞 減問題或逐步解決。
展望#5:新的模型架構出現,但是 Transformer 仍是主流
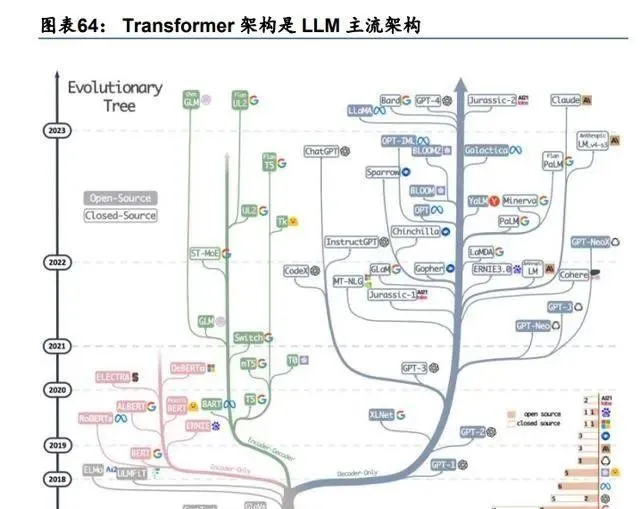
Transformer 架構主流地位未被撼動。截止 23 年 5 月,LLM 絕大部份仍然以 Transformer 為基礎架構,包括當前最先進的 GPT-4 系列、Google Gemini 系列、Meta Llama 系列,均 是以 Transformer 的解碼器架構為主。雖然有研究者提出了 Mamba 等基於狀態空間模型 (SSM)的新模型架構,實作了:1)推理時的吞吐量為 Transformer 的 5 倍;2)序列長 度可以線性擴充套件到百萬級別;3)支持多模態;4)測試集結果優於同等參數規模的 Transformer 模型。但從工程實作來看,暫時未得到大範圍的使用。Google 也探索了迴圈 神經網絡的遞迴機制與局部註意力機制的結合;KAN 的提出也從底層替換了 Transformer 的基礎單元 MLP(多層感知機)。但我們認為,以上方法都缺乏大量的工程實踐和成熟的工 程工具,短期內替換掉 Transformer 可能性不大。
全球首個基於 Mamba 架構的生產級模型釋出,Mamba 開始得到落地驗證。24 年 3 月, AI21 釋出世界首個 Mamba 的生產級模型 Jamba,融合了 Mamba+Transformer+MoE 等不 同類別的大模型技術。Jamba 基本資訊如下:1)共 52B 參數,其中 12B 在推理時處於激 活狀態;2)共 16 位專家,推理過程中僅 4 個專家處於活躍狀態;3)模型基於 Mamba, 采用 SSM-Transformer 混合的架構;4)支持 256K 上下文長度;5)單個 A100 80GB 最 多可支持 140K 上下文;6)與 Mixtral 8x7B 相比,長上下文的吞吐量提高了 3 倍。從測評 結果看,Jamba 在推理能力上優於 Llama 2 70B、Gemma 7B 和 Mixtral 8x7B。Mamba 架 構開始得到驗證。
Google RecurrentGemma 架構也與 Transformer 不同,是另一種新的路線探索。 RecurrentGemma 基於 Google 開源的小模型 Gemma,在此基礎上,引入了迴圈神經網絡 (RNN)和局部註意力機制來提高記憶效率。由於傳統的 Transformer 架構中,需要計算 兩兩 token 之間的註意力機制,因此時間和空間復雜度均隨著 token 的增加而平方級增長。 由於 RNN 引入的線性遞迴機制避免了平方級復雜度,RecurrentGemma 帶來了以下幾個優 勢:1)記憶體使用減少:在記憶體有限的器材(例如單個 XPU)上生成更長的樣本。2)更高 的吞吐量:由於記憶體使用量減少,RecurrentGemma 可以以顯著更高的 batch 大小執行推 理,從而每秒生成更多的 token(尤其是在生成長序列時)。更重要的是,RecurrentGemma 展示了一種實作高效能的非 Transformer 模型,是架構革新的重要探索。
展望#6:AI Agent 智能體是 AGI 的加速器
電腦科學中 Agent 指電腦能夠理解使用者的意願並能自主地代表使用者執行任務。Agent (中文轉譯智能體、代理等)概念起源於哲學,描述了一種擁有欲望、信念、意圖和采取 行動能力的實體。將這個概念遷移到電腦科學中,即意指電腦能夠理解使用者的意願並 能自主地代表使用者執行任務。隨著 AI 的發展,AI Agent 用來描述表現出智能行為並具有自 主性、反應性、主動性和社交能力的人工實體,能夠使用傳感器感知周圍環境、做出決策, 然後使用執行器采取行動。 AI Agent 是實作人工通用智能(AGI)的關鍵一步,包含了廣泛的智能活動潛力。2020 年, Yonatan Bisk 在【Experience Grounds Language】中提出 World Scope (WS),來描述自 然語言處理到 AGI 的研究進展,包括 5 個層級:WS1. Corpus (our past);WS2. Internet (most of current NLP);WS3. Perception (multimodal NLP);WS4. Embodiment;WS5. Social。據復旦大學 NLP 團隊,純 LLM 建立在第二個層次上,即具有互聯網規模的文本輸 入和輸出。將 LLM 與 Agent 技術架構結合,並配備擴充套件的感知空間和行動空間,就有可能 達到 WS 的第三和第四層。多個 Agent 可以透過合作或競爭來處理更復雜的任務,甚至觀 察到湧現的社會現象,潛在地達到第五 WS 級別。
AI Agent 主要由 LLM 大腦、規劃單元、記憶單元、工具和行動單元組成。不同研究中的 AI Agent 框架組成略有差別。比較官方的定義是 OpenAI 安全系統負責人 Lilian 提出的,她 將 Agent 定義為 LLM、記憶(Memory)、任務規劃(Planning Skills)以及工具使用(Tool Use)的集合,其中 LLM 是核心大腦,Memory、Planning Skills 以及 Tool Use 等則是 Agents 系統實作的三個關鍵元件。此外,復旦大學 NLP 團隊也提出了由大腦、感知和動作三部份 組成的 AI Agent 框架。
吳恩達教授指出,LLM 加上反思、工具使用、規劃、多智能體等能力後,表現大幅提升。 史丹福大學教授、Amazon 董事會成員吳恩達在紅杉美國 AI Ascent 2024 提出,如果使用者 圍繞 GPT-3.5 使用一個 Agent 工作流程,其實際表現甚至好於 GPT-4。其中,反思指的是 讓模型重新思考其生成的答案是否正確,往往會帶來輸出結果的改進;工具使用包括呼叫 外部的聯網搜尋、行事曆、雲端儲存、程式碼直譯器等工具,補充模型的能力欠缺;多智能體協 作指的是多種智能體互相搭配來完成一個復雜任務,每種智能體會負責自己所擅長的一個 領域,類似人類社會之間的協作,實作超越單個智能體能達到的效果。
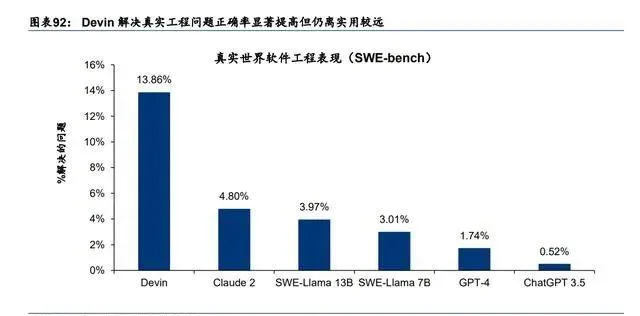
Agent 相關研究處於爆發期。伴隨 LLM 的快速叠代發展,基於 LLM 的 AI Agent 湧現,典 型的如 Auto-GPT、微軟的 HuggingGPT、史丹佛小鎮 Generative Agent、Nvidia Voyager 等。24 年 3 月,AI 初創公司 Cognition 釋出第一個 AI 軟件工程師自主智能體 Devin,能夠 使用自己的 shell、程式碼編輯器和 Web 瀏覽器來解決工程任務,並在 SWE-Bench 基準測試 上正確解決了 13.86%的問題,遠超之前方法的正確率。我們認為,2024 年基於 AI Agent 的套用和產品仍將會繼續湧現,其效果也將持續受益於大模型能力的提升,AI Agent 將成 為實作 AGI 的重要助推器。
展望#7:具身智能與 LLM 結合落地加速
AI 龍頭公司在具身智能領域有模型、框架層面的豐富研究成果。23 年 5 月,Nvidia CEO 黃仁勛指出,AI 的下一個浪潮將是具身智能。各個 AI 頭部廠商均有相關的研究成果。23 年年初,微軟的 ChatGPT for Robotics 初次探討了 LLM 代替人工編程,來對機器人實作控 制。Google 延續了 2022 年的具身智能成果,將 RT 系列模型升級到視覺動作語言模型 RT-2, 將 Gato 升級到能自我叠代的 RoboCat,並開源了迄今最大的真實機器人具身智能數據集 Open X-Embodiment。Nvidia 也有 VIMA 和 OPTIMUS 等具身智能研究,並在 24 年 2 月 成立了專門研究具身智能的小組 GEAR。史丹佛李飛飛教授的 VoxPoser 結合視覺模型和語 言模型優勢,建模了空間 Value Map 來對機器人軌跡進行規劃。Meta 也釋出 RoboAgent, 並在訓練數據集收集上利用了自家的 CV 大模型 SAM。
2024 年,具身智能仍是 LLM 重要的終端落地場景,技術仍在持續叠代。1)24 年 1 月, 史丹福大學釋出 Mobile ALOHA 機器人,利用模仿學習,在人類做出 50 個範例後,機器人 即能自行執行下遊任務。2)同月,Google 一次性釋出了三項具身智能成果。Auto-RT 解 決機器人數據來源問題,透過 LLM 和 VLM(視覺語言模型)擴充套件數據收集;SARA-RT 顯 著加快了 Robot Transformers 的推理速度;RT-Trajectory 將影片轉換為機器人軌跡,為機 器人泛化引入了以運動為中心的目標。3)AI 機器人公司 Figure 推出了 Figure 01,采用端 到端 AI 神經網絡,僅透過觀察人類煮咖啡即可在 10 小時內完成訓練。4)從目前 Tesla Optimus 釋出影片情況看,Optimus 的神經網絡已經能夠指導機器人進行物品分揀等動作, 且控制能力進一步提高。
OpenAI 與 Figure AI 率先合作,實作了大模型對具身智能的賦能。24 年 3 月,OpenAI 官方宣布與 Figure AI 機器人公司合作,將多模態模型擴充套件到機器人感知、推理和互動。宣 布合作 13 天後,Figure 01 已經與 OpenAI 的視覺語言模型結合,並釋出了演示影片。 ChatGPT 從頂層負責使用者互動、環境感知(依靠 vision 視覺能力)、復雜問題拆解,而 Figure 01 自身的神經網絡和控制系統負責底層的自主任務執行,實作了強互動的自主任務執行。 隨後,國內大模型廠商百度與機器人整機廠商優必選也宣布合作,「復刻」了 OpenAI+Figure 的合作路線,由文心大模型負責互動推理、優必選 Walker X 負責底層任務實作。我們認為, 多模態大模型和機器人結合的路線已經走通,隨著 24 年模型能力持續叠代(GPT-4o 的出 現),以及人形機器人自主和控制能力的加強,LLM+具身智能落地加速,並將更加可用、 好用。
GPT-5 的幾個預期
OpenAI 從 GPT-3 開始實行閉源商業化路線,相關的模型技術幾乎不再公布細節。我們基 於對全球大模型發展趨勢的研究和把握,提出幾個 GPT-5 可能的預期和展望,並給出相應 的推測邏輯。
預期#1:MoE 架構將延續,專家參數和數量或變大
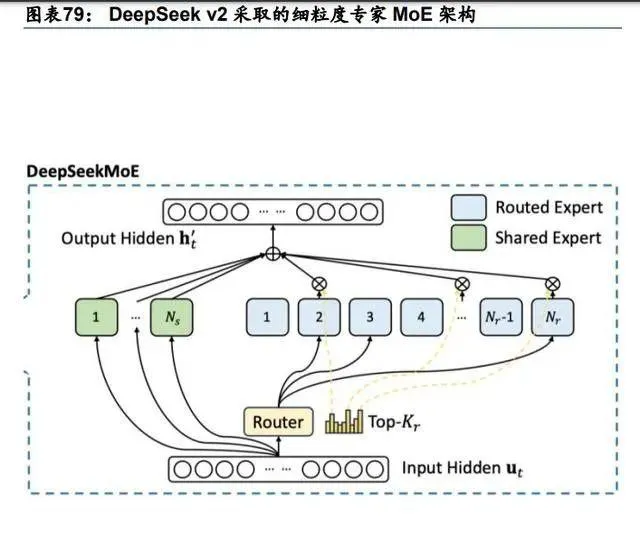
MoE 是現階段實作模型效能、推理成本、模型參數三者最佳化的最佳架構方案。1)MoE 將 各種專家透過路由(router)機制有機整合,在各種下遊任務上,能夠充分利用每個專家的 專業能力,提高模型表現;2)MoE 天然的稀疏架構,使得 MoE 模型與同參數稠密模型在 推理成本上有較大節省;3)同理,在推理成本固定的情況下,MoE 模型相比稠密模型,能 夠把模型參數堆到更大,同樣能夠提升模型效能。 我們認為,OpenAI 在 GPT-5 模型叠代時仍將采用 MoE 架構,或有部份改進。相比 GPT-4, GPT-5 的 MoE 架構或將有以下改進:1)每個專家的參數更大,例如每個專家大小與 GPT-4 相同,近 2T 參數。即使 OpenAI 無法將單個 2T 參數專家做成稠密架構,也可以使用 MoE 巢狀 MoE 的方式實作。2)專家數量變多,例如幻方旗下 DeepSeek V2 模型即使用改進的 DeepSeekMoE 架構,采取了更細粒度的專家結構,將專家數擴充套件到 160+,以適應更加豐 富和專業的下遊任務。3)MoE 架構本身可能有改進,例如 Google DeepMind 提出了 Mixture of Depth(MoD)架構,向 Transformer 的不同層(layer)引入類似 MoE 的路由機制,對 token 進行選擇性處理,以減少推理成本。MoD 可以和 MoE 混合使用,相當於對 MoE 進 行了改進。OpenAI 或也會有類似的改進技術。
預期#2:GPT-5 及之後模型的訓練數據集質素更高、規模更大
OpenAI 不斷加速與私有高質素數據公司的合作進度,為訓練大模型做數據儲備。2023 年 11 月,OpenAI 即官宣推出數據合作夥伴計劃,將與各類組織合作生成用於訓練 AI 模型的 公共和私有數據集,包括冰島政府、非營利法律組織「Free Law Project」等。2024 年, OpenAI 在 4-5 月先後與英國金融時報、程式設計師交流網站 Stack Overflow、論壇網站 Reddit 宣布合作,相關數據覆蓋了新聞、程式碼、論壇交流等場景。我們認為,OpenAI 在早期的數 據儲備中,已經將網絡公開可獲得的數據進行了充分的開發,根據 OpenAI 的 Scaling Law 和 Google Chinchilla 的結論,隨著模型參數的增大,想要充分訓練模型,必須增大訓練數 據規模,這也從 OpenAI 的廣泛數據合作關系中得到印證。我們認為,GPT-5 及之後模型 的訓練數據集,將有望吸納更多高質素的私域數據,數據規模也將變得更大。
預期#3:在思維鏈 CoT 的基礎上,再加一層 AI 監督
思 維 鏈 能 夠 在 不 改 變 模 型 的 情 況 下 提 高 其 表 現 性 能 。 2022 年 , Jason Wei 在 【Chain-of-Thought Prompting Elicits Reasoning in Large Language Models】中首次提出 思維鏈(chain of thought,CoT)概念,使模型能夠將多步驟問題分解為中間步驟。透過 思維鏈提示,足夠規模(~100B 參數)的語言模型可以解決標準提示方法無法解決的復雜 推理問題,提高各種推理任務的表現。以算數推理 MultiArith 和 GSM8K 為例,當使用思維 鏈提示時,增加 LaMDA 和 PaLM 模型參數可以顯著提高效能,且效能大大優於標準提示。 此外,思維鏈對於模型的常識推理任務(如 CommonsenseQA、StrategyQA 和 Date Understanding 等)同樣有明顯的效能提升作用
OpenAI 探索了過程監督對模型的效能提升,有望與 CoT 結合,進一步提高推理能力。23 年 5 月,OpenAI 官方 blog 宣布訓練了一個獎勵模型,透過獎勵推理的每個正確步驟(「過 程監督」),而不是簡單地獎勵正確的最終答案(「結果監督」),來更好的解決模型的數學推 理能力和問題解決能力。與結果監督相比,過程監督有優勢:1)過程監督相當於直接獎勵 了模型遵循對齊的 CoT,流程中的每個步驟都受到精確的監督;2)過程監督更有可能產生 可解釋的推理,因為它鼓勵模型遵循人類思考的過程。最終的 MATH 測試集結果中,過程 監督能夠提升相對於結果監督 5pct 以上的正確率。我們認為,這種基於 CoT 的過程監督方 法,有可能幫助 GPT-5 進一步提高模型推理的正確性,壓制模型幻覺。
預期#4:支持更多外部工具呼叫的端到端模型
GPT-5 有望在 GPT-4 少量的外部工具基礎上,增加更多的可呼叫工具,擴充套件能力邊界。目 前基於 GPT-4 系列的 ChatGPT,能夠呼叫 Bing 搜尋、高級數據分析(原程式碼直譯器)、 DALL-E 文生圖等外部工具,並且在 23 年 11 月推出 All Tools 能力,讓 ChatGPT 在與使用者 對話時自主選擇以上三種工具。外部工具呼叫使得模型在效能基本保持不變的情況下,能 力邊界得到擴充套件,其實質與 Agent 呼叫工具類似。此外,曾在 23 年 3 月推出的 ChatGPT Plugins 功能,本質也是外部工具,但是由於 GPT-4 能力的有限,導致能夠在單個對話中使 用的 Plugins 只有三個,因此 Plugins 逐漸被 GPTs 智能體取代。我們認為,隨著 GPT-5 推理能力的進一步提高,將有能力更好的自主分析使用者需求,以更合理的方式,呼叫更多 的外部工具(100-200 個),如小算盤、雲端儲存等,從而進一步擴充套件 GPT-5 的模型能力邊界。
GPT-4o 已經打下多模態端到端的基礎,GPT-5 將延續。我們認為,GPT-4o 驗證了頭部廠 商大模型原生多模態的發展趨勢,這一趨勢不會輕易改變,因為端到端的原生多模態,很 好的解決了模型延時(如 GPT-4 非端到端語音響應平均時間超 5s,而 4o 端到端語音響應 時間平均僅 320ms)、模型誤差(由於誤差是不可避免的,級聯的模型越多,誤差累計越大, 端到端僅 1 份誤差)等問題,因此 GPT-5 將延續端到端多模態結構,或將有部份改進。如 進一步降低端到端的響應延遲,最佳化使用者使用體驗;加入更多的模態支持,如深度、慣性 測量單位(IMU)、熱紅外輻射等資訊,以支持更復雜的如具身智能等場景。
預期#5:多種大小不同的參數,不排除推出端側小模型
Google 和 Anthropic 均在同代模型中推出參數大小不同的版本,GPT-5 有望跟進。Google 和 Anthropic 均采取了同代模型、不同大小的產品釋出策略,以平 衡使用者的成本和效能體驗。據海外開發者 Tibor Blaho 資訊,ChatGPT 安卓版安裝包 1.2024.122 版本中發現了三個新的模型名稱:gpt-4l,gpt-4l-auto,gpt-4-auto,其中 l 代表 「lite」(輕量),或是 OpenAI 開始考慮布局大小不同的模型矩陣。由於 Google 官方已經實 現了最小參數的 Gemini Nano 模型在 Pixel 8 Pro 和三星 Galaxy S24 系列實裝,且據 Bloomberg 資訊,OpenAI 與 Apple 正在探索端側模型上的合作,我們預測,GPT-5 也有可 能推出端側的小參數模型版本。
預期#6:從普通作業系統到 LLM 作業系統
LLM 作業系統是 Agent 在系統層面的具象化。LLM OS 是前 OpenAI 科學家 Andrej Karpathy 提出的設想,其中 LLM 將替代 CPU 作為作業系統核心,LLM 的上下文視窗是 RAM,接受使用者指令並輸出控制指令,在 LLM 核心外部有儲存、工具、網絡等各種「外設」 供 LLM 呼叫。我們認為,從結構上看,LLM OS 和圖表 67 所示的 Agent 架構十分相似, 可以看做 Agent 在作業系統領域的具象化。LLM OS 的核心就是模型能力,隨著 GPT-5 推 理效能的不斷提升,我們認為 LLM 和 OS 結合的範式將更有可能實作,屆時人類和 OS 的 互動方式將不再以鍵鼠操作為主,而會轉向基於 LLM 的自然語言或語音操作,進一步解放 人類雙手,實作互動方式的升級。
預期#7:端側 AI Agent 將更加實用和智能
OpenAI 和 Google 已經將模型的重點使用場景定位到端側 AI Agent。24 年 5 月 13-14 日, OpenAI 和 Google 分別召開釋出會和開發者大會,其中最值得關註和最亮眼的部份就是端 側 AI Agent。OpenAI 基於最新的端到端 GPT-4o 模型打造了新的 Voice Mode,實作了更 擬人、更個人化、可打斷、可即時互動的 AI 助手,並能夠使用 4o 的視覺能力,讓助手針 對使用者看到的周圍環境和PC場景進行推理;Google的Project Astra也實作了類似的效果, 並且能夠根據模型「看到」的場景進行 recall。我們認為,頭部模型廠商遵循了模型邊叠代、 套用邊解鎖的發展路徑,目前已經將模型的使用場景聚焦到了端側。結合 OpenAI 與 Apple 的合作進展看,端側 AI 或將在 24 年下半年成為重點。
更加智能的 GPT-5 能夠將 AI Agent 能力推上新的台階。我們認為,OpenAI 在第四代 GPT 的大版本下,已經透過端到端的 4o 實作了 AI Agent 更即時、更智能的多模態互動。但是基 於目前模型的推理效能,AI Agent 在實作多工、多步驟的自主任務執行時成功率仍不夠 高。以 PC 端基於 GPT-4 的 AI 軟件工程師智能體 Devin 為例,在 SWE-Bench 基準測試(要 求 AI 解決 GitHub 上現實世界開源專案問題)上進行評估時,Devin 在沒有人類協助的情況 下能正確解決 13.86%的問題,遠遠超過了之前最好方法對應的 1.96%正確率,即使給出了 要編輯的確切檔,Claude 2 也只能成功解決 4.80%的問題。但是 13.86%的成功率,仍 然距離實用較遠,究其原因還是模型的智能能力「不夠」。我們認為,隨著 GPT-5 核心推理 能力進一步提高,或能將「類 Devin」產品正確率提升到 80%以上,AI Agent 將變得更加 實用和智能。
理想 vs 現實:從 AI+到+AI
據 Ericsson 白皮書【Defining AI native】,AI 與系統可以分為非原生和原生兩類。對於 非 AI 原生(None AI-native)系統,又可根據 AI 元件的部署方式細分為:1)替換已有部 件。即在現有的系統元件中,將其中的一部份用基於 AI 的元件進行替換或增強。2)增加 新的部件。即不改變現有系統中元件的情況下,增加一部份基於 AI 的元件。3)增加 AI 控 制。同樣不改變現有系統的元件,增加基於 AI 的控制元件部份,來對已有元件進行控制, 在傳統功能之上提供自動化、最佳化和額外功能。對於 AI 原生(AI-native)系統,系統中所 有的元件均基於 AI 能力構建,整個 AI 原生系統擁有內在的、值得信賴的 AI 功能,AI 是設 計、部署、操作和維護等功能的自然組成部份。
AI+指的是 AI 原生形式,是理想的 AI 套用和硬件構建方法,但是目前的大模型能力還無法 很好的支持這一實作。 在 AI+套用方面,典型的如 AI 原生搜尋類套用 Perplexity。據 SimilarWeb 數據,2023 年 1 月-2024 年 5 月,Perplexity 每月的網站存取量不斷提升,截至 24 年 5 月,月網站存取 量已經達到了近 9000 萬,較大振幅領先於同樣做 AI 原生搜尋的 You.com。但是從搜尋引 擎的全球市占率看,據 Statcounter 數據,Google 的搜尋引擎市占率從 23 年 1 月的 92.9% 僅微降到 24年 5月的 90.8%,Bing的市占率從 23年 1月的 3.03%微升到 24年 5月的 3.72%。 我們認為,目前為止,AI 原生的搜尋套用並未對傳統搜尋產生本質影響。
在 AI+硬件方面,代表產品為 Ai Pin 和 Rabbit R1。23 年 11 月,智能穿戴器材公司 Humane 釋出基於 AI 的智能硬件 Ai Pin,由 GPT 等 AI 模型驅動,為 AI 原生的硬件,支持激光屏、 手勢、語音等操作。24 年 4 月,Rabbit 推出 AI 驅動的硬件 R1,大小約為 iPhone 的一半。 R1 使用者無需應用程式和登入,只需簡單提問,就能實作查詢、播音樂、打車、購物、發信 息等操作。R1 內部執行 Rabbit OS 作業系統,基於「大型動作模型」(Large Action Model, LAM)打造,而非類似於 ChatGPT 的大型語言模型。LAM 可以在電腦上理解人類的意 圖,借助專門的 Teach Mode,使用者可以在電腦上演示操作,R1 將進行模仿學習。但是 以上兩款產品釋出後,據BBC 和 Inc 等資訊,產品的使用者體驗一般,問題主要包括 AI 模型 響應過慢、對網絡通暢性要求過高、無法端側推理、電池發熱嚴重等。
+AI 指的是非原生 AI 形式,在成熟的軟硬件系統上疊加一定的 AI 功能,更符合當前模型 的能力,或成為近期的叠代重點。 在+AI 套用方面,微軟的 Copilot 系列是典型的成熟 SaaS+AI 套用。從功能覆蓋來看,微 軟基於成熟的作業系統、企業辦公、客戶關系管理、資源管理、員工管理、低程式碼開發等 業務環節,上線了 Copilot 相關功能,並初步實作各套用間的 Copilot 聯動。據微軟 24Q1 財報數據,Github Copilot 使用者數已超 50000 家,付費使用者人數 180 萬人,Windows 系統 層面的 Copilot 裝機量約 2.3 億台。
另一個+AI 的典型套用是 Meta 的推薦演算法+AI 大模型賦能。據 4 月 19 日朱克伯格訪談, Meta 從 22 年即開始購入 p00 GPU,當時 ChatGPT 尚未問世,Meta 主要利用這些算力 開發短影片套用 Reels 以對抗 Tiktok,其中最核心的就是推薦演算法的改進。2024 年 4 月, Meta 釋出生成式推薦系統論文【Actions Speak Louder than Words: Trillion-Parameter Sequential Transducers for Generative Recommendations 】, 開 創 性 提 出 了 基 於 Transformer 的生成式推薦(Generative Recommenders ,GRs)架構(更具體細節可以參 考華泰電腦 5 月 23 日報告【雲廠 AI 算力自用需求或超預期】)。據 Meta 24Q1 電話會, 截至 24Q1,Facebook 上約有 30%的貼文是透過 AI 推薦系統釋出的,在 Instagram 上看 到的內容中有超過 50%是 AI 推薦的,已經實作了推薦引擎+AI 對推薦和廣告業務的賦能。
在+AI 硬件方面,在成熟的 PC 和手機上已經探索出了硬件+AI 的演進道路。雖然原生的 AI 硬件如 Ai Pin 和 Rabbit R1 並未取得巨大成功,但是微軟、聯想的 AI PC 布局,以及 Apple 的 AI 手機布局已經清晰。從目前各廠商終端側模型布局看,有以下特點:
1)端側模型參數量普遍在 100 億參數以下。端側能夠支持的模型參數大小,重要的取決因 素是 NPU(神經處理單元)的算力多少,以及記憶體 DRAM 的大小。端側最先進的芯片 NPU 算力基本在 40TOPS 左右,支持的參數一般在百億級別。
2)端雲協同模式將長期存在。由於端側模型參數量有限,導致無法處理較復雜的任務,因 此還需要依賴雲端或伺服器端的模型配合。高通於 23 年 5 月釋出白皮書【混合 AI 是 Al 的 未來】,指出 AI 處理能力持續向邊緣轉移,越來越多的 AI 推理工作負載在手機、筆記本電 腦、XR 頭顯、汽車和其他邊緣終端上執行。終端側 AI 能力是賦能端雲混合 AI 並讓生成式 AI 實作全球規模化擴充套件的關鍵。此外,以 Apple Intelligence 的模型布局為例,其中的編排 層(Orchestration)會根據任務難易決定推理使用終端模型還是雲端模型。我們認為,這 種端雲協同的方式在端側+AI 的形式下有望長期存在。
3)Arm 架構芯片布局略快於 x86 架構。微軟的第一批 Copilot+ PC 搭載的高通驍龍 X Elite 芯片和 Apple 自研的 M 系列芯片,均是基於 Arm 架構打造。AMD 和 Intel 的 x86 架構 AI PC 芯片在時間上略有落後。我們認為,Arm 架構有望在終端+AI 領域提高市場份額,但是最終 Arm 和 x86 的格局尚需觀察。
(本文僅供參考,不代表我們的任何投資建議。如需使用相關資訊,請參閱報告原文。)
(轉自:未來智庫)











