
構建 10 萬卡 GPU 集群的技術挑戰
摘要
揭示AI訓練集群關鍵基礎設施挑戰,探討突破現有AI瓶頸的必要性與10萬GPU集群(如OpenAI、Meta)建設所面臨挑戰與需求。
- 構建網絡拓撲,需權衡多層交換機成本、頻寬與維護。本文對比Ethernet與InfiniBand,探討機架最佳化,助您明智選擇。
- 平行計算 - 介紹了數據並列、張量並列和管線並列,以及如何結合使用。
- 深入剖析:揭示InfiniBand、Spectrum-X Ethernet與Broadcom Tomahawk 5等方案的成本對比,助您明智選擇。
自 GPT-4 釋出以來,AI 能力停滯不前。一般來說,這種觀點是正確的,但原因在於還沒有人能夠大規模地增加單個模型的計算量。每個釋出的模型的訓練計算量大致在 GPT-4 的水平(約 2e25 FLOP 訓練計算量)。這是因為用於這些模型的訓練計算量也大致相同。以 Google 的 Gemini Ultra、Nvidia 的 Nemotron 340B 和 Meta 的 LLAMA 3 405B 為例,它們的 FLOPS 甚至比 GPT-4 更高,但由於架構劣勢,這些模型未能解鎖新能力。

OpenAI擴大計算資源,專註於打造更小、更經濟高效的推理模型如GPT-4 Turbo和GPT-4o。雖起步晚,現已開啟下一層級模型訓練。
AI邁向新裏程碑:萬億參數多模態變換器橫空出世,影片、影像、音訊、文本盡收眼底。尚未有人攻克,競爭激烈,未來可期!
多個大型 AI 實驗室,包括但不限於 OpenAI/Microsoft、xAI 和 Meta,正在競相建立超過 10 萬個 GPU 的集群。這些單個訓練集群的伺服器資本支出成本超過 40 億美元,但由於 GPU 通常需要共址以進行高速芯片到芯片的網絡連線,它們還受到數據中心容量和電力不足的嚴重限制。一個 10 萬 GPU 的集群需要超過 150MW 的數據中心容量,並在一年內消耗 1.59 太瓦時的電力,按照標準費率 $0.078/kWh 計算,成本為 1.239 億美元。

今天我們將深入探討大型訓練 AI 集群及其周圍的基礎設施。構建這些集群遠比單純投入金錢復雜得多。實作高利用率更為困難,因為各種元件的高故障率,尤其是網絡故障。我們還將介紹電力挑戰、可靠性、檢查點、網絡拓撲選項、並列方案、機架布局和這些系統的總物料清單。
超過一年前,我們報道了 Nvidia 的 InfiniBand 問題,導致一些公司選擇 Spectrum-X 乙太網路而非 InfiniBand。我們還將介紹 Spectrum-X 的主要缺陷,導致超大規模使用者選擇 Broadcom 的 Tomahawk 5。
為了說明 10 萬 GPU 集群能提供多少計算能力,OpenAI 為 GPT-4 的訓練 BF16 FLOPS 為約 2.15e25 FLOP(2150 萬 ExaFLOP),使用約 2 萬個 A100 進行了 90 到 100 天的訓練。該集群的峰值吞吐量為 6.28 BF16 ExaFLOP/秒。在一個 10 萬 p00 集群上,這個數碼將飆升至 198/99 FP8/FP16 ExaFLOP/秒。這是相對於 2 萬 A100 集群的峰值理論 AI 訓練 FLOPs 增加了 31.5 倍。
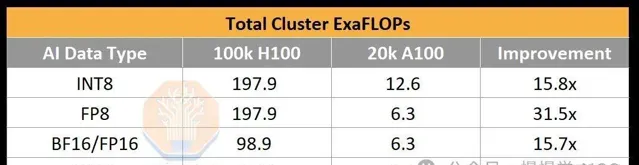
在 p00 上,AI 實驗室在萬億參數訓練執行中達到了高達 35% 的 FP8 模型 FLOPs 利用率(MFU)和 40% 的 FP16 MFU。回顧一下,MFU 是在考慮到開銷和各種瓶頸(如功率限制、通訊不穩定、重新計算、滯後和低效內核)後,峰值潛在 FLOPS 的有效吞吐量和利用率的衡量標準。使用 FP8,10 萬 p00 集群只需四天即可訓練 GPT-4。在一個 10 萬 p00 集群上進行 100 天的訓練執行,可以達到大約 6e26 的有效 FP8 模型 FLOP(600 萬 ExaFLOP)。請註意,硬件的低可靠性顯著降低了 MFU。
電力挑戰
10 萬 p00 集群所需的關鍵 IT 電力約為 150MW。雖然 GPU 本身只有 700W,但在每個 p00 伺服器中,CPU、網絡介面卡(NIC)、電源模組(PSU)每個 GPU 還需要額外約 575W。除了 p00 伺服器外,AI 集群還需要一系列儲存伺服器、網絡交換機、CPU 節點、光學收發器等專案,總共占 IT 電力的 10%。對比而言,最大的國家實驗室超算 El Capitan 只需 30MW 的關鍵 IT 電力。政府的超級電腦與行業相比相形見絀。
現有數據中心無力承載約150MW的新部署需求。提及10萬GPU集群,通常指校園內多個建築,而非單一建築。X.AI不得已在田納西孟菲斯改造舊廠為數據中心,以應對電力挑戰。
光學收發器網絡連線成本隨覆蓋範圍遞增。長距單模DR/FR收發器可靠傳輸達500米至2公裏,成本卻是多模SR/AOC收發器的2.5倍。校園級相幹800G收發器覆蓋超2公裏,成本更是多模收發器的10倍以上。
p00集群,每個GPU高達400G連線速度,透過簡潔的交換機結構實作高效協同。大型集群則需多層交換機,光學器件成本高。網絡拓撲因供應商、工作負載和資本支出而多樣化。
每棟樓配備一個或多個計算單元,以銅線或多模收發器連線。長距離收發器實作「島嶼」間互聯。盡管155MW難以集中供應,但我們正關註超過15個數據中心建設,如Microsoft、Meta、Google等,它們將為AI伺服器與網絡器材提供充足空間。

客戶依據數據傳輸、成本、維護、電力及負載需求,選擇不同網絡拓撲。如Tomahawk 5交換機、InfiniBand和NVIDIA Spectrum-X。本文將揭示其背後的決策動因。
回顧並列性
深入解析網絡設計三大並列性:數據、張量、流水線,理解其拓撲、可靠性及檢查點策略。詳盡解釋,助您掌握萬億參數訓練核心!
數據並列性,即每個GPU持有模型權重副本,處理不同數據子集,通訊量最低,僅需求和梯度。然而,其局限性在於,僅當每個GPU記憶體足夠儲存整個模型權重、啟用和最佳化器狀態時才有效。例如,訓練GPT-4等高達1.8萬億參數的模型,可能需10.8TB記憶體。
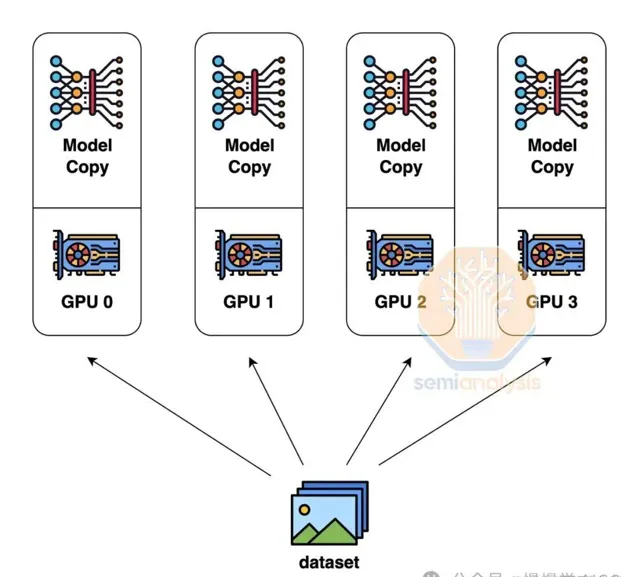
為了克服這些記憶體限制,使用張量並列性。在張量並列性中,每層的工作和模型權重分布在多個 GPU 上,通常跨隱藏維度分布。透過多次在每層的自註意、前饋網絡和層歸一化之間的全規約交換中間工作。
需要高頻寬,特別是非常低的延遲。實際上,域內的每個 GPU 像一個巨大的 GPU 一樣在每層上協同工作。張量並列性按張量並列性等級數量減少每個 GPU 使用的總記憶體。例如,今天通常使用 8 個張量並列性等級在 NVLink 上,因此這將使每個 GPU 的使用記憶體減少 8 倍。
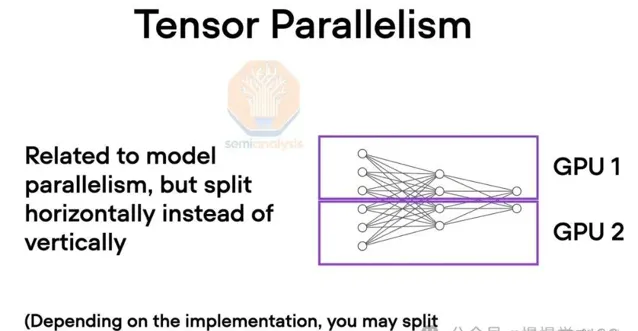
突破GPU記憶體極限,流水線並列技術應運而生。此法將模型分層計算,每GPU分擔部份任務,輸出接力至下一GPU,大幅降低記憶體需求。雖然通訊量較高,但仍輕於張量並列,效率顯著。
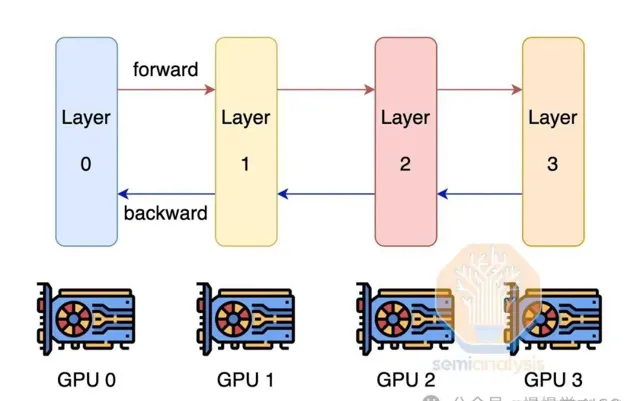
為提升模型FLOP利用率,我們融合張量、流水線與數據並列性,構建3D並列架構。在p00伺服器內,張量並列貫穿,島內節點以流水線並列協作,島間則依托數據並列,最佳化通訊效率。
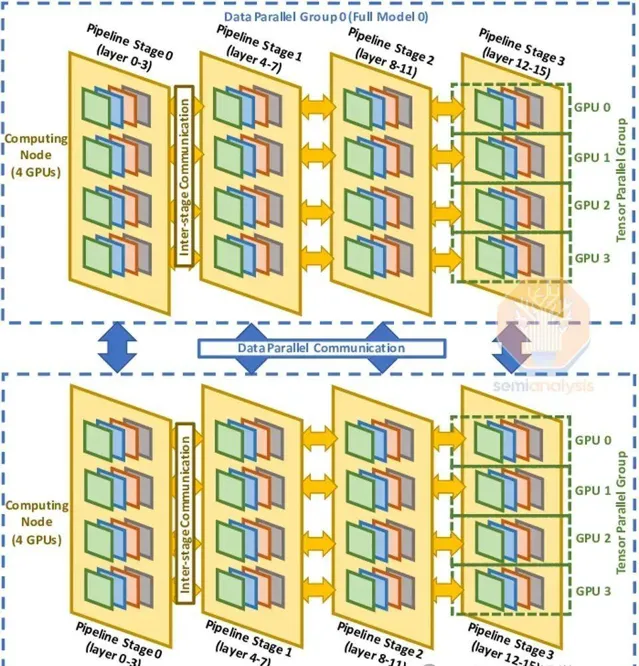
網絡設計考慮因素
網絡架構基於並列設計。若每個GPU以最大頻寬連線至其他所有GPU,將需四層交換機,成本高昂,且每層額外網絡需光學器材,導致光學器件成本激增。
大型GPU集群不采用全樹架構,轉而構建計算島,島間頻寬較小。普遍采用「超額訂閱」策略,如Meta的前代架構,含32,000 GPU,8個島間全頻寬,頂層7:1超額訂閱,島間網絡速度僅島內1/7。
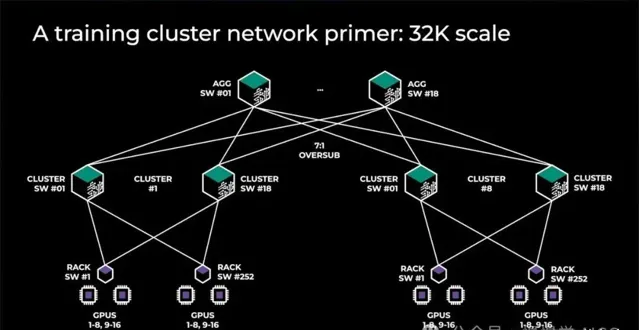
在GPU部署中,前端、後端及NVLink擴充套件網絡各司其職。NVLink網絡獨步快速,勝任張量並列頻寬需求。後端網絡高效處理多數並列任務,但超額訂閱下,僅限數據並列。
混合 InfiniBand 和前端乙太網路結構
這家公司巧妙運用前端乙太網路在InfiniBand島嶼間訓練,成本更低,依托現有數據中心網絡,實作高效擴充套件。
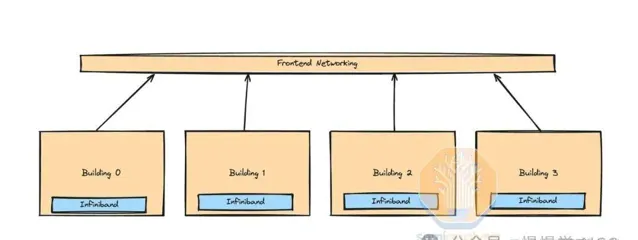
隨著MoE等稀疏技術模型尺寸激增,前端網絡通訊量同步攀升。精妙最佳化權衡至關重要,否則頻寬激增將令成本與後端頻寬齊飛。
Google的多TPU pod訓練全靠前端網絡驅動,其「計算結構」ICI,最大可延伸至8960個芯片,透過昂貴的800G光交換機連線TPU水冷機架。為超越GPU,Google精心打造了更強大的TPU前端網絡。
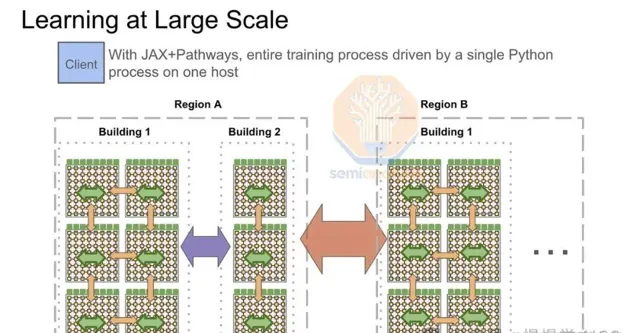
訓練期間,前端網絡操作需進行島間拓撲感知的全規約。每pod在InfiniBand或ICI網絡內完成本地規約散射,匯總GPU/TPU梯度子部份。隨後,透過前端乙太網路網絡在主機等級間進行跨pod all reduce,最終實作每個pod的pod級別全規約。
隨著多模態數據激增,前端網絡頻寬面臨挑戰。載入大型影片與all-reduce競爭,流量不規律加劇滯後,影響建模速度與可預測性。
四層InfiniBand網絡,7:1超額訂閱,每Pod搭載24,576個p00,非阻塞三層系統。相比前端網絡,升級光纖收發器更易增加頻寬,輕松應對未來需求。
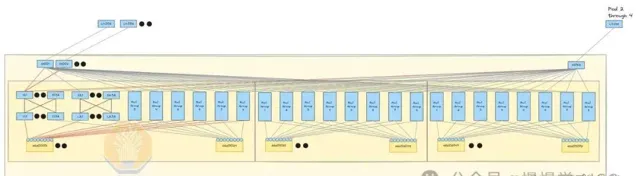
打造穩定網絡新格局,前端聚焦數據載入,後端專註GPU通訊,有效緩解延遲。然四層InfiniBand網絡高昂成本,需額外交換機和收發器支持。
軌域最佳化 vs 機架中部
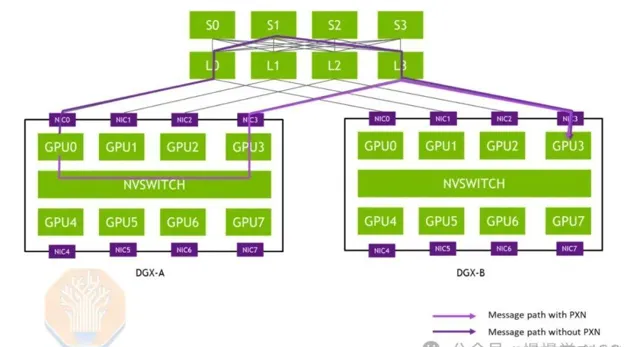
軌域最佳化技術讓p00伺服器直接連線8個葉交換機,實作GPU間單跳通訊,顯著提升all2all集體通訊效率。此技術廣泛套用於混合專家模型(MoE)的專家平行計算。
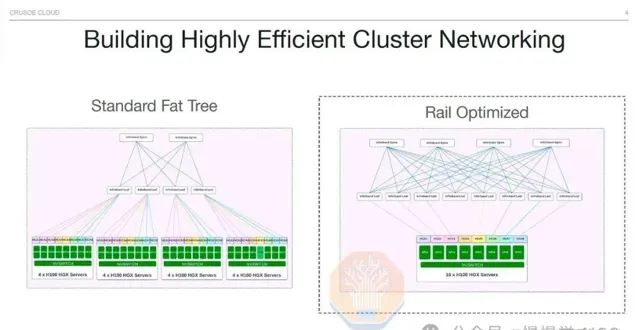
軌域最佳化設計雖高效,卻面臨挑戰:葉交換機分布較散,需借助光學器材,葉脊間最長距離超50米,須采用單模光收發器,確保數據傳輸穩定。
透過非軌域最佳化設計,將98,304個光收發器替換為銅線,讓25-33%的GPU結構采用銅線連線。此舉簡化了GPU與葉交換機的連線,不再需繞行電纜托盤和多個機架,葉交換機直接位於機架中部,每個GPU直接使用DAC銅纜連線,效率提升顯著。
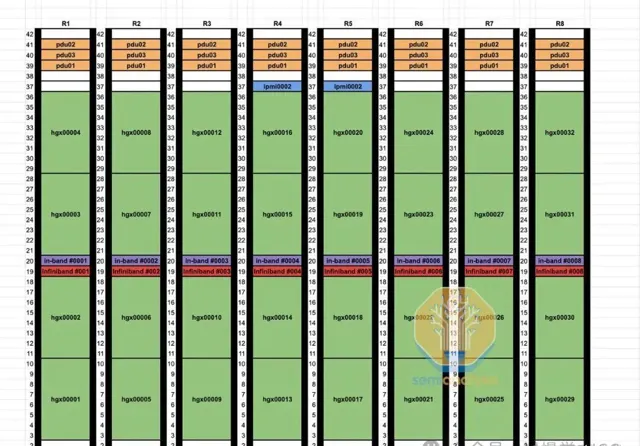
DAC銅纜執行更涼爽,電力消耗低,價格遠低於光學器材。其更可靠的效能顯著降低網絡波動和故障,這是高速互連的常見難題。相比量子-2 IB交換機747瓦的功耗,光收發器功耗最高達1,500瓦。
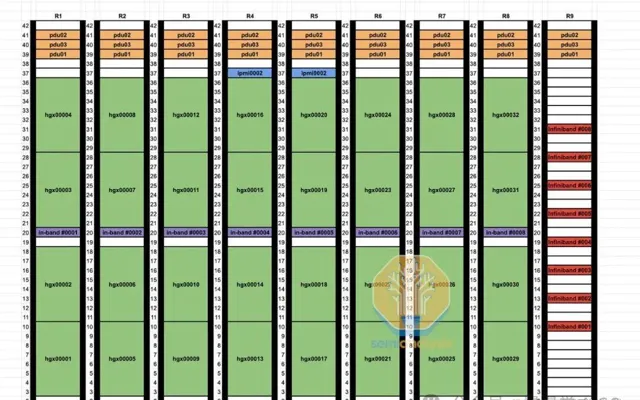
對數據中心技術人員而言,軌域最佳化布線耗時,每鏈路末端相距50米,不同機架。中部設計則簡化流程:葉交換機與GPU同架,整合工廠測試便捷,效率大幅提升。
可靠性與恢復
可靠性成大型集群關鍵挑戰,常見問題包括GPU HBM ECC錯誤、驅動卡頓、收發器故障及NIC過熱,導致節點頻繁宕機或錯誤輸出。
為降低故障恢復時間,數據中心需備有熱備用節點和冷備用元件。故障發生時,迅速切換至備用節點,確保訓練不間斷。停機僅需簡單重新開機,快速解決問題,確保訓練持續高效執行。
簡單重新開機無效,需專業技術人員物理診斷與器材更換。修復損壞GPU伺服器耗時數小時至數天。損壞與備用熱節點雖具理論FLOPS,卻未積極助力模型訓練。
在模型訓練中,定期將檢查點儲存至CPU記憶體或NAND SSD,以防HBM ECC錯誤。若發生錯誤,需重新載入權重重新開機訓練。故障容錯技術如Oobleck,提供使用者級GPU和網絡故障處理方案。
不幸的是,頻繁的檢查點和故障容錯訓練會顯著降低系統整體效能。集群需頻繁暫停保存權重,導致每次重新開機最多損失99步工作。以10萬集群為例,若每次叠代耗時2秒,第99步故障可能造成高達229天GPU工作量的損失。
借助後端結構,備用節點可從其他GPU快速RDMA復制,僅需約1.6秒復制80GB HBM記憶體中的權重。盡管最多可能遺失1步,但整體影響僅限於約3.15GPU天計算時間。
AI領域的先鋒實驗室已普遍采用高效故障恢復技術,而眾多小公司仍依賴低效手段。采用記憶體重構,可令大型AI訓練效率提升數個百分點。
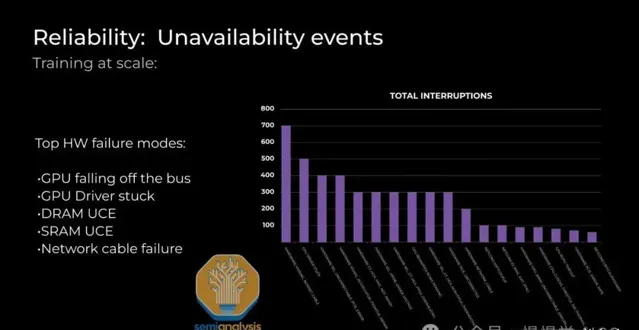
InfiniBand/RoCE鏈路故障頻發,即便平均故障時間長達5年,眾多收發器導致新集群26.28分鐘內首度作業中斷。光學器材故障重新開機10萬GPU集群,恢復耗時或超模型進展。

每個GPU直接連線至ConnectX-7 NIC,網絡架構無故障容錯,故障處理需在使用者程式碼中實作,增復雜度。NVIDIA與AMD網絡結構挑戰顯著,單一元件故障即導致伺服器停機。
正在進行關鍵升級,確保網絡重構,增強節點抗脆弱性。當前狀況下,單點故障如GPU或光學問題可能導致價值百萬的GB200 NVL72全面停機,遠超數十萬美元8GPU伺服器的損失。
Nvidia 註意到了這一重大問題,並添加了一個專用於可靠性、可用性和可維護性(RAS)的引擎。我們相信 RAS 引擎分析芯片級數據,如溫度、恢復的 ECC 重試次數、時鐘速度、電壓等,預測芯片可能何時故障並警告數據中心技術人員。這將允許他們進行主動維護,如使用更高的風扇速度配置檔以維持可靠性,在稍後的維護視窗取出伺服器進行進一步的物理檢查。此外,在啟動訓練作業之前,每個芯片的 RAS 引擎將進行綜合自檢,如執行矩陣乘法以檢測靜默數據損壞(SDC)。
Cedar-7
一些客戶(如 Microsoft/Openai)透過使用 Cedar Fever-7 網絡模組每台伺服器,而不是使用 8 個 PCIe 形式的 ConnectX-7 網絡卡,來進行成本最佳化。使用 Cedar Fever 模組的主要好處之一是只需使用 4 個 OSFP 籠,而不是 8 個 OSFP 籠,從而允許在計算節點端使用雙埠 2x400G 收發器,而不僅僅是在交換機端。這將 GPU 到葉交換機的收發器數量從 98,304 減少到 49,152。

GPU至交換機連線減半,顯著縮短首次作業故障預估時間至4年,相較於單埠400G的5年,提高至42.05分鐘,大幅優於未采用Cedar-7模組的26.28分鐘。

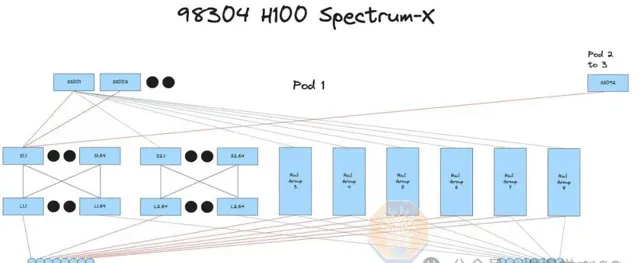
Spectrum-X NVIDIA
我們正構建10萬節點NVIDIA Spectrum-X乙太網路p00集群,年底全面上線,引領高效能計算新紀元!
去年我們報道了 Spectrum-X 在大型網絡中的各種優勢。除了效能和可靠性優勢外,Spectrum-X 還具有巨大的成本優勢。Spectrum-X 乙太網路的每個 SN5600 交換機有 128 個 400G 埠,而 InfiniBand NDR Quantum-2 交換機只有 64 個 400G 埠。值得註意的是,Broadcom 的 Tomahawk 5 交換機 ASIC 也支持 128 個 400G 埠,使當前一代 InfiniBand 處於劣勢。
一個完全互連的 10 萬集群可以是 3 層而不是 4 層。4 層而不是 3 層意味著需要多 1.33 倍的收發器。由於 Quantum-2 交換機的較低徑數,10 萬集群上完全互連的 GPU 數量最多限制為 65,536 個 p00。下一代 InfiniBand 交換機稱為 Quantum-X800,透過具有 144 個 800G 埠解決了這一問題,雖然從「144」這個數碼可以看出,這設計用於 NVL72 和 NVL36 系統,並預計在 B200 或 B100 集群中使用不多。盡管使用 Spectrum-X 可以節省成本,但不幸的是,您仍需購買 Nvidia LinkX 產品線的高價收發器,因為其他收發器可能無法工作或未經過 Nvidia 驗證。
Spectrum-X 擁有先發優勢,NVIDIA 庫(如 NCCL)全力支持,Jensen 邀您成為其新品線先鋒。相較Tomahawk 5,節省內部資源,輕松實作網絡與 NCCL 的最佳效能。
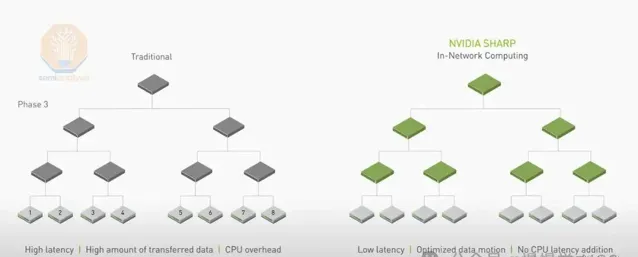
乙太網路雖取代InfiniBand套用於GPU結構,但無法支持SHARP內規約,限制了理論頻寬提升。SHARP內規約透過交換機張量核心簡化GPU間數據傳輸,理論頻寬可翻倍。
Spectrum-X 的另一個缺點是,對於第一代 400G Spectrum-X,Nvidia 使用 Bluefield3 而不是 ConnectX-7 作為臨時解決方案。我們預計在未來幾代 800G Spectrum-X 中,ConnectX-8 將完美工作。
然而,Bluefield-3 和 ConnectX-7 卡之間的價格差異約為 300 美元,其他缺點是 Bluefield-3 卡的功耗增加了 50 瓦。因此,對於每個節點,額外需要 400W 的功率,降低了整體訓練伺服器的「智能每皮焦耳」。使用 Spectrum X 的數據中心現在需要額外的 5MW 電力用於 10 萬 GPU 部署,而與 Broadcom Tomahawk 5 部署使用相同網絡架構相比。
Broadcom Tomahawk 5
為規避Nvidia高昂費用,眾多客戶轉向搭載Broadcom Tomahawk 5的交換機。Tomahawk 5與Spectrum-X SN5600同埠配置,128個400G埠,效能卓越。更佳的是,您可全球采購通用收發器和銅纜,靈活配置。
眾多客戶青睞與Broadcom交換機ASIC的ODM如Celestica合作,同時攜手Innolight和Eoptolink等采購收發器。Tomahawk 5在交換機與收發器成本上均優於Nvidia InfiniBand,且價格低於Nvidia Spectrum-X。
遺憾需具備高超工程實力,以最佳化Tomahawk 5修補程式及NCCL集群。原NCCL集群僅針對Nvidia Spectrum-X和InfiniBand最佳化。然而,若您擁有40億美元投資10萬集群,將能輕松為NCCL編寫客製最佳化,輕松切換離InfiniBand。
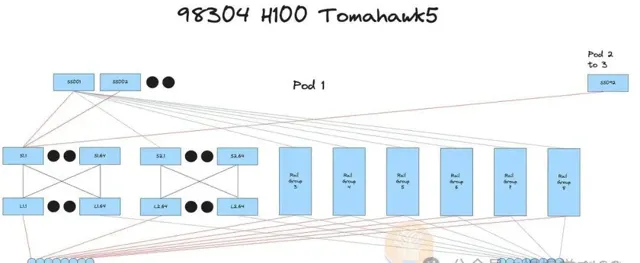
探討四種10萬GPU集群網絡配置及交換、收發器成本,揭示各自優勢,並展示最佳化光學器材的GPU集群物理布局圖。
-對此,您有什麽看法見解?-
-歡迎在評論區留言探討和分享。-











