金磊 假裝發自 維也納量子位 | 公眾號 QbitAI
機器學習三大頂會之一的ICLR 2024,正在維也納如火如荼地舉行。
雖然首個時間檢驗獎、傑出論文獎等「重頭戲」已經陸續頒布,但在其它環節中,我們卻發現了一件更有意思的事情。

同樣是作為ICLR重要組成部份的特邀演講(Invited Talk),每年都會邀請在機器學習領域有突出貢獻和影響力的專家學者進行演講。
而今年,中國只有一位!
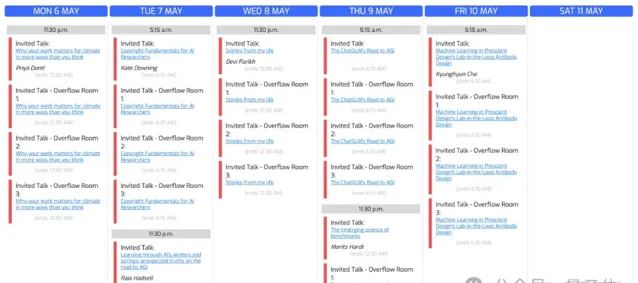
並且僅從他的演講主題The ChatGLM’s Road to AGI中,我們就能挖到更多的線索——
ChatGLM,正是由清華系初創智譜AI所推出的千億參數大語言模型。

那麽被ICLR官方唯一「翻牌」的智譜AI團隊,又在長達1個小時的特邀演講中說了些什麽?
我們繼續往下看。
唯一受邀的中國大模型團隊
在「大模型之戰」開啟以來,智譜AI的ChatGLM不誇張地說,是一直處於國內第一梯隊的玩家之一。
事實上,智譜AI從2019年就已經入局LLM的研究;從目前的發展來看,智譜AI與OpenAI在AIGC的各個模態上均已呈現出生態對標之勢:
ChatGPT vs ChatGLM
DALL·E vs CogView
Codex vs CodeGeex
WebGPT vs WebGLM
GPT-4V vs GLM-4V
雖然生態對標得很緊密,但從技術路線上來看,智譜的GLM與GPT是截然不同的。
當下基於Transformer架構的模型大致可以分為三類:
僅編碼器架構(Encoder-only)、僅解碼器架構(Decoder-only)、編碼器-解碼器架構(Encoder-Decoder)。
GPT是屬於「僅解碼器架構」的玩家,而GLM則是借鑒「編碼器-解碼器架構」的思路去發展;因此也有一番獨樹一幟的味道。
而作為此次唯一被ICLR邀請做演講的中國大模型公司,智譜AI團隊在現場先分享了自己是如何從ChatGLM一步步走向GLM-4V,即從LLM邁向VLM。
我們可以從下面這張發展時間線中,先有一個整體脈絡上的感知。
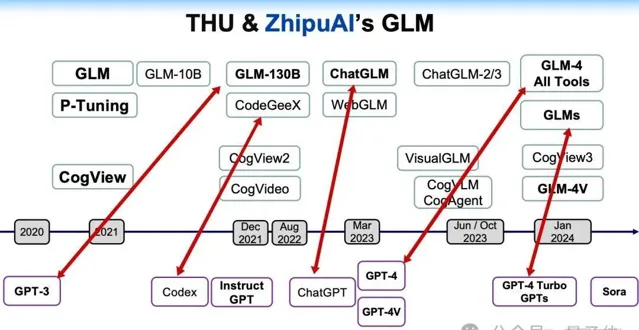
具體到技術上的實作,比較關鍵的節點便是CogVLM的提出,主打讓大模型帶上視覺。

CogVLM模型主要包含四個元件,分別是ViT編碼器、MLP介面卡、大型預訓練語言模型和視覺專家模組。
這個方法可以說是改變了視覺語言模型的訓練範式,從淺層對齊轉向深度融合。
值得一提的是,CogVLM還被Stable Diffufion 3用來做了影像標註。

基於此,智譜AI團隊在本次特邀演講環節中,更多地介紹並亮出了近期的前沿成果。
例如CogView3,是一個更快、更精細的文生圖模型。
其創新之處便是提出了一個級聯框架,是第一個在文本到影像生成領域實作級聯擴散的模型。
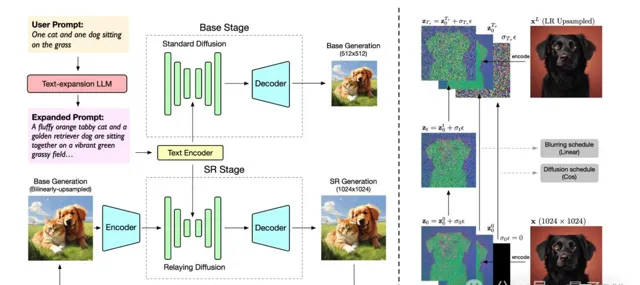
從實驗結果來看,CogView3在人類評估中比當前最先進的開源文本到影像擴散模型SDXL高出77.0%,同時只需要大約SDXL一半的推理時間。
CogView3的蒸餾變體在效能相當的情況下,只需SDXL的1/10的推理時間。
同樣是基於 CogVLM,智譜AI所做的另一項研究CogAgent,則是一款具有視覺Agent能力的大模型。
CogAgent-18B擁有110億的視覺參數和70億的語言參數, 支持1120*1120分辨率的影像理解。在CogVLM的能力之上,它進一步擁有了GUI影像Agent的能力。
據了解,CogAgent-18B已經在9個經典的跨模態基準測試中實作了最先進的通用效能;並且在包括AITW和Mind2Web在內的GUI運算元據集上顯著超越了現有的模型。
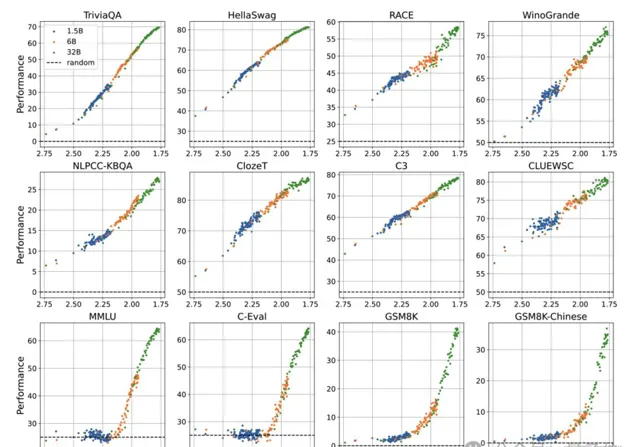
除此之外,智譜AI團隊還提出:AI大模型的智能湧現,關鍵在於Loss,而並非模型參數。

為此,團隊提出了Pre-training Loss作為語言模型「湧現能力」的指標,訓練了30多個不同模型參數和數據規模的語言模型,並評估了他們在 12 個英文和中文數據集上的表現:
Pre-training Loss 與下遊任務效能呈負相關,即預訓練損失越低,下遊任務效能越好。這一結論適用於不同參數尺寸的語言模型,不受模型大小、訓練數據量的影響。
對於一些下遊任務,當 Pre-training Loss 低於某個閾值時,效能才會超過隨機猜測水平,呈現出「湧現能力」。這些任務的效能閾值大致相同,約在2.2左右。
即使使用連續指標評估,仍觀察到「湧現能力」的存在。這表明湧現能力並非由非線性或離散指標導致。
再如針對LLM解決數學問題,提出了Self-Critique的叠代訓練方法,透過自我反饋機制,幫助LLM同時提升語言和數學的能力。

對於ChatGLM通向AGI的後續計劃,智譜AI在本次特邀演講中也亮出了自己的「三步走」。
首先是GLM-4的後續升級版本,即GLM-4.5。
據了解,新升級的模型將基於超級認知SuperIntelligence和超級對齊SuperAlignment技術,同時在原生多模態領域和AI安全領域有長足進步。
團隊表示:
通向通用人工智能之路,文本是最關鍵的基礎。但下一步則應該把文本、影像、影片、音訊等多種模態混合在一起訓練,變成一個真正原生的多模態模型。
其次,為了解決更加復雜的問題,團隊將引入GLM-OS的概念。
GLM-OS是指以大模型為中心的通用計算系統,具體實作方法如下:
基於已有的All-Tools能力,再加上記憶體記憶memory和自我反饋self-reflection能力,GLM-OS有望成功模仿人類的PDCA機制,即Plan-Do-Check-Act迴圈。首先做出計劃,然後試一試形成反饋,調整規劃然後再行動以期達到更好的效果。大模型依靠PDCA迴圈機制形成自我反饋和自我提升——恰如人類自己所做的一樣。
最後,是GLM-zero。
這項技術其實智譜AI從2019年以來便一直在鉆研,主要是研究人類的「無意識」學習機制:
當人在睡覺的時候,大腦依然在無意識地學習。「無意識」學習機制是人類認知能力的重要組成部份,包括自我學習self-instruct、自我反思self-reflection和自我批評self-critics。
團隊認為,人腦中存在著反饋feedback和決策decision-making兩個系統,分別對應著LLM大模型和Memory記憶體記憶兩部份,GLM-zero的相關研究將進一步拓展人類對意識、知識、學習行為的理解。
而這也是GLM大模型團隊第一次向外界公開這一技術趨勢。
當然,除了這場特邀演講之外,回顧本屆ICLR其它亮點,可以說大模型著實是頂流中的頂流。
ICLR 2024,大模型贏麻了
首先是斬獲本屆ICLR頒發的第一個時間檢驗獎(Test of Time Award)的論文,可以說是經典中的經典——變分自編碼器(VAE)。
正是這篇11年前的論文,給後續包括擴散模型在內的生成模型帶來重要思想啟發,也才有了現如今大家所熟知的DALL·E 3、Stable Diffusion等等。
也正因如此,在獎項公布之際便得到了眾多網友的認可,紛紛表示「Well deserved」。

論文一作Diederik Kingma現任DeepMind研究科學家,也曾是OpenAI創始成員、演算法負責人,還是Adam最佳化器發明者。
VAE采用了一個關鍵策略:使用一個較簡單的分布(如高斯分布)來近似復雜的真實後驗分布。模型的訓練透過最大化一個稱為證據下界(ELBO)的量來實作。
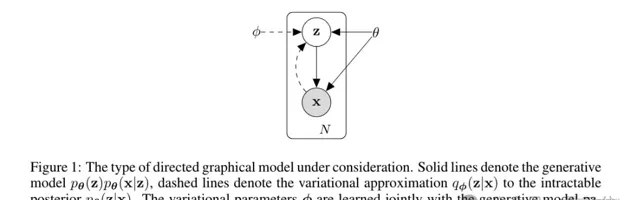
這種方法可以被看作是在影像重建的同時,對潛在變量的分布施加了一種「規範化」約束。
與傳統自編碼器相比,VAE所學習的潛在表示通常具有更強的解釋性和更好的泛化能力。
在論文的實驗部份,作者展示了VAE在MNIST數據集上生成手寫數碼影像的能力。

ICLR 2024的首個時間檢驗獎還設定了亞軍(Runner Up)獎項。
同樣也是非常經典的一項研究,作者包括OpenAI首席科學家的Ilya、GAN的發明者Ian Goodfellow。

這項研究名為Intriguing properties of neural networks,官方對其的評價是:
研究強調了神經網絡容易受到輸入的微小變化的影響。這個想法催生了對抗性攻擊(試圖愚弄神經網絡)和對抗性防禦(訓練神經網絡不被愚弄)領域。
除了時間檢驗獎之外,每年的傑出論文獎(Outstanding Paper Awards)也是必看點之一。
本屆ICLR共有五篇論文榮登傑出論文獎。

第一篇:
Generalization in diffusion models arises from geometry-adaptive harmonic representations
這篇來自紐約大學、法蘭西學院的研究,從實驗和理論研究了擴散模型中的記憶和泛化特性。作者根據經驗研究了影像生成模型何時從記憶輸入轉換到泛化機制,並透過 「幾何自適應諧波表征 」與諧波分析的思想建立聯系,進一步從建築歸納偏差的角度解釋了這一現象。

第二篇:
Learning Interactive Real-World Simulators
研究機構來自UC柏克萊、Google DeepMind、MIT、阿爾伯塔大學。匯集多個來源的數據來訓練機器人基礎模型是一個長期的宏偉目標。這項名為 「UniSim 」的工作使用基於視覺感知和控制文字描述的統一界面來聚合數據,並利用視覺和語言領域的最新發展,從數據中訓練機器人模擬器。

第三篇:
Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors
來自特拉維夫大學、IBM的研究深入探討了最近提出的狀態空間模型和Transformer架構對長期順序依賴關系的建模能力。作者發現從頭開始訓練Transformer模型會導致對其效能的低估,並證明透過預訓練和微調設定可以獲得巨大的收益。

第四篇:
Protein Discovery with Discrete Walk-Jump Sampling
基因泰克、紐約大學的研究解決了基於序列的抗體設計問題,這是蛋白質序列生成模型的一個重要套用。作者引入了一種創新而有效的新建模方法,專門用於處理離散蛋白質序列數據的問題。

第五篇:
Vision Transformers Need Registers
來自Meta等機構的研究,辨識了vision transformer網絡特征圖中的偽影,其特點是低資訊量背景區域中的高規範Tokens。作者對出現這種情況的原因提出了關鍵假設,利用額外的register tokens來解決這些偽影問題,從而提高模型在各種任務中的效能。

而在五篇傑出論文獎中,與大模型相關的研究就占了四篇,可以說是贏麻了。
除此之外,還有11篇論文獲得了獲得榮譽提名(Honorable mentions),其中三篇論文是全華人陣容。
整體來看,本屆會議共收到了7262 篇送出論文,接收2260篇,整體接收率約為 31%。此外Spotlights論文比例為 5%,Oral論文比例為 1.2%。
One More Thing
ICLR的創立者之一Yann LeCun(另一位是Yoshua Bengio),在會議期間的「出鏡率」可以說是比較高了,頻頻出現在網友的照片中。
而他本人也開心地分享了自己的一張自拍合影:

不過也有網友指出:「拍得不錯,就是可憐手機後邊的兄弟了。」

以及會場的展廳也是有點意思:

嗯,是有種全球大模型玩家線下battle的既視感了。
時間檢驗獎論文地址:[1]https://arxiv.org/abs/1312.6114[2]https://arxiv.org/abs/1312.6199
傑出論文獎論文地址:[1]https://openreview.net/forum?id=ANvmVS2Yr0[2]https://openreview.net/forum?id=sFyTZEqmUY[3]https://openreview.net/forum?id=PdaPky8MUn[4]https://openreview.net/forum?id=zMPHKOmQNb[5]https://openreview.net/forum?id=2dnO3LLiJ1
參考連結:[1]https://iclr.cc/virtual/2024/calendar?filter_events=Invited+Talk&filter_rooms=[2]https://twitter.com/ylecun/status/1788560248988373170[3]https://arxiv.org/abs/2311.03079











