哈嘍~,大家好,我是東哥,寶爸一枚,正努力探索AI,創富人生,目標幫助1000名誌同道合的朋友一起提前退休!
你們記不記得EMO?
就是前兩天阿裏剛放出來那個,透過音訊驅動圖片唱歌的模型,到現在還沒有開源使用,但已經有不少人透過這個噱頭,讓「親人復活了」
這不,以抄xi。呃~不對,以研發著稱的騰訊直接開源了全新大模型
,鬼畜評論區快要坐不住了啊
來看看坤坤這段說唱:
不得不說啊,不論從肌肉運動還是肢體的協調上,效果都是相當驚艷的,這以後生成口播影片是不是就......
其實早在2月份時候,阿裏就公布出自己的圖生影片大模型EMO,當時的效果也是相當炸裂。
一張照片,一段音訊,就可以生成一段會說話或者唱歌的AI影片,表情,語速都可以一一對應。
還不知道的可以再來回顧一下:
時隔一個多月了,現在EMO的「開源」倉庫依舊「整潔如初」
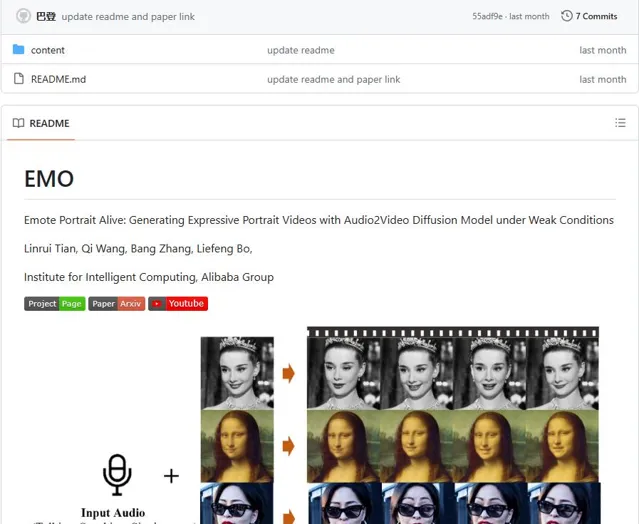
不禁感慨這波開源屬實開了個寂寞,本來靠EMO賺足了噱頭的阿裏,這回真的要emo了
應了那句話,行動早,就是優勢。
根據騰訊放出來的模型來看,有三種合成模式
1、自我驅動
意思就是可以指定頭部姿勢,或者選擇預設的姿勢配置,來控制生成動畫中的頭部動作,使動畫效果更加自然和多樣化,比如坤坤RAP和下面這個:
2、臉部再現
這個意思就是,咱們提供一段影片,AI透過分析和參考影片中的面部表情和動作,實作在圖片上復刻,這個技術好
3、音訊驅動
透過提供一段音訊和一張頭像圖片,AI根據語音和節奏來控制人物的表情生成動畫
這場AI領域的較量中,TX明顯快一步,不虧是小馬哥啊
但整體看下來,效能應該相差不大,畢竟哪哪都是EMO的味道
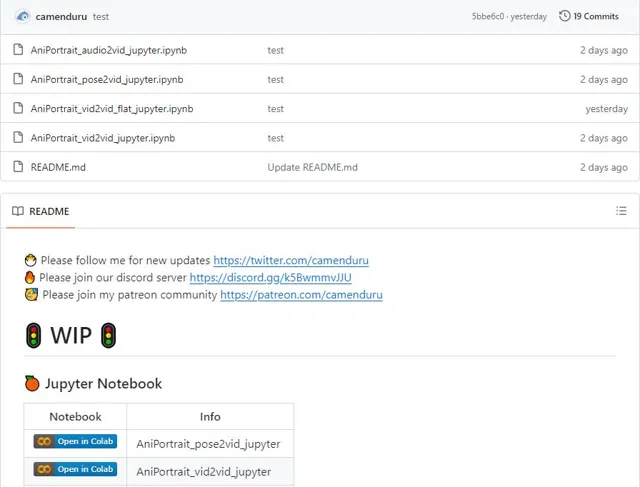
目前該專案的模型權重已經開放下載,感興趣的夥伴趕緊去試試吧
老鐵們如果覺得內容對你有幫助,就給東哥點個「關註」吧,據我所知點「贊」的老鐵都好運纏身了
下載的地址我都整理好了,如果你懶得找可以找我領取











