 智東西
智東西
作者 | GenAICon 2024
2024中國生成式AI大會於4月18-19日在北京舉行,在大會第二天的主會場AIGC套用專場上,DeepMusic CEO劉曉光以【AIGC如何賦能音樂創作與制作】為題發表演講。
劉曉光系統性復盤了當前音樂商業格局,包括不同音樂使用者群體的特征與主要使用產品、相關音樂公司的商業獲利模式。
他提到當前音樂商業格局主要面向 泛音樂愛好者的聽歌 及 淺 度實踐使用者的唱歌消費體驗 ,中間有 1億以上 活躍音樂人、音樂實踐者群體的需求尚未得到好的產品滿足;同時音樂制作流程長、門檻高,這使得音樂AIGC技術有用武之地。
音樂創作與制作本身具備一定的專業性門檻,非專業人士很難借助音樂來表達自我,AIGC的發展為音樂創作帶來了另一種可能性。劉曉光不僅詳細回顧了音樂生產工具的40年演變歷程以及其中 三個關鍵階段 ,並對近期多個爆款AI音樂生成產品進行推演,解讀其背後采用的 技術方案 。
劉曉光深入講解了 音訊模型、符號模型 兩類AI音樂模型所涉及的工作原理、訓練數據及演算法技術,並就跨平台一站式AI音樂工作站「 和弦派 」的設計邏輯進行分享。「和弦派」以更直觀的功能譜呈現音樂創作部份資訊,解決音樂中歌詞、旋律、伴奏等不同模態之間溝通困難的問題,實作跨PC、手機平台的音樂創作、制作體驗。
他認為音樂產業 明年 就能實作自然語言生成高品質伴奏的功能, 只需上傳30秒人聲素材,就能生成用自己聲音演唱的歌曲 。未來,DeepMusic也會透過積累的精細化標註數據,實作對音訊模型的精細化控制。
以下為劉曉光的演講實錄:
我們公司專註於音樂AIGC技術,因此,基於在此領域的專業認知,我們將與大家探討以下幾個方面:行業現狀、AIGC對音樂行業的潛在影響、AIGC在音樂數據與技術方面的套用,以及未來發展趨勢。
一、音樂商業格局:泛音樂愛好者月活達8億,頭部企業極度集中
我們先來了解一下音樂行業的整體情況。
音樂行業最外圈的群體是 泛音樂愛好者 ,他們主要透過聽歌來體驗音樂,使用的主要產品包括酷狗音樂、QQ音樂和網易雲音樂等。根據上市公司的數據顯示,這一群體的月活躍使用者大約達到 8億人 。
泛音樂愛好者是音樂行業中最廣泛參與的群體之一。出於對音樂的興趣,部份聽歌人會參與一些與音樂相關的實踐活動,例如,最淺的音樂實踐就是唱K和觀看音樂演出,主要使用全民K歌等產品。
在 中度實踐 階段,我們通常會使用一些產品,例如蘋果系統預裝軟件酷樂隊和安卓市集中的完美鋼琴。完美鋼琴在安卓市集的下載量可能接近1億次,但其留存率卻相對較低。這表明, 中度實踐使用者開始對音樂產生需求,但目前市場上的產品並不能完全滿足他們的需求 。

接下來是 深度實踐 使用者,主要涵蓋15至30歲的年輕人和50歲以上的中老年人。其中,約15%的年輕人已經參與音樂類興趣社團,而約15%的中老年人參與了中老年合唱團等興趣社團。這些使用者逐漸表現出創作的意願,預計規模大約為2000萬人。我們將這些積極從事音樂實踐的人群統稱為 音樂實踐者 。
從音樂實踐者進一步升級,則為 音樂人 。國內音樂人總數約為 100萬 。這一群體主要來自騰訊、網易以及抖音等平台,主要從事創作和表演活動。作為音樂人,他們 至少釋出過1首原創作品 。大多數音樂人並非經過傳統的專業音樂教育培養而成,而是透過職業培訓學校獲得技能,傳統音樂教育並不為數碼音樂行業提供人才。
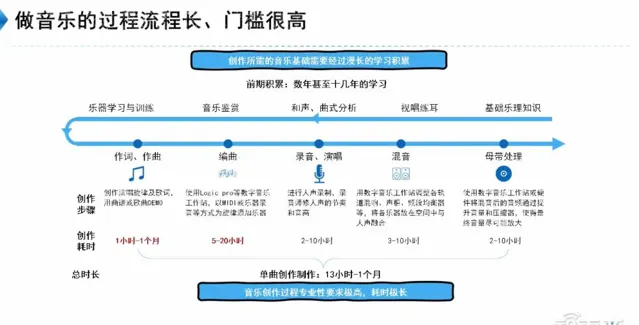
音樂人創作時使用的軟件很有意思,比如作詞用Word,作曲用錄音機,我們可能也覺得用這些軟件制作音樂有些奇怪,我們清楚不可能用錄音機做出咱們平時聽的高質素音樂作品。
還有一個群體被稱為 音樂制作人 。這些人通常是從音樂人逐漸晉升而來,他們需要經過多年的制作經驗才能勝任。他們的主要任務是將音樂人提供的音樂錄音Demo進行制作。在這個過程中,常見的音樂制作軟件包括雅馬哈公司的Cubase和蘋果公司的Logic Pro,它們是目前主流的音樂制作工具,通常執行在個人電腦上。然而,這些軟件上手門檻極其高。
音樂人群是這樣的,那商業是怎麽發展的呢?
在這個領域,我們可以看到唱片公司、經紀公司等行業參與者。他們的主要任務是簽約頭部音樂制作人,並從音樂人那裏獲取原創歌曲,然後將這些歌曲制作並釋出到主要的音樂平台,如騰訊音樂、網易雲音樂等。
這些平台是這個行業的甲方公司,其年收入約為500億人民幣。其中,約35%的收入來自會員費,即使用者每年支付的訂閱費用,已經超過億人;另外55%的收入則來自使用者產生的娛樂消費,還有10%來自廣告。
這500億的終端收入中,大約有100億會被分配給音樂創作者和唱片公司。而唱片公司則透過播放占比分成的方式來分配收入,即根據某首歌的播放量在中國整體音樂聽眾中的占比來確定分成比例。
音樂產業是一個 極度頭部集中 的行業,以周杰倫的播放占比為例,其歌曲在中國整體音樂市場中的占比為5.6%。這意味著大約每20個人中就有1個在聽周杰倫的歌曲。
我認為外圈的音樂商業是頭部集中的,商業模式已經相對成熟或者問題已經基本得到解決。
二、AIGC打破音樂制作高成本限制,音訊模型引領音樂生產工具3.0時代
AIGC的主要目標是解決音樂領域中的 中間環節 問題。
我們註意到, 在中級階段的音樂實踐者中,缺乏適合他們進行互動式學習和成長的優質產品。而對於深度實踐者,也缺乏能夠幫助他們提升技能的優秀軟件 。音樂人在創作音樂時使用Word和錄音機可能存在一些問題。即使他們用這些工具創作出作品,交給音樂制作人後,仍需要大量的重復工作才能進一步處理。
我們認為, AIGC音樂領域的目標,實際上是服務大約全球總人口的10%的音樂實踐者 。
可以發現,盡管中國可能有30%到40%的孩子在小學時學習音樂,但為什麽他們大後和音樂商業所需的人才不匹配呢?這是因為在我們的音樂教育中,更註重的是基礎樂理知識、唱和聲、曲式分析以及器樂培訓等,這些最終會讓學生變成演奏機器。
然而,在真正的音樂實踐、娛樂和商業環境中,所需的是作詞、作曲、編曲、錄音、演唱以及後期處理等音樂生產過程的技能。作詞和作曲相對容易理解,編曲稱作伴奏。
伴奏是指歌曲中的聲音,如鼓、吉他、貝斯等樂器。要想精通編曲,需要克服的門檻非常高。現在,如果我有音樂興趣,想要將其實作成一個成品,就會發現,這個過程既困難又昂貴,而且進展緩慢。
接下來,我將分享一下音樂生產工具在過去40年中的演變。

首先是2000年以前,即 音樂生產工具1.0時代 ,幾乎所有的音樂制作都依賴硬件錄音,那時的音樂作品很有情調,因為只有最專業的音樂人才有機會參與錄音過程。
第二個階段, 音樂生產工具2.0時代 。蘋果、雅馬哈、Avid幾家公司推出了一個軟件——數碼音樂工作站,這種軟件在電腦上執行,門檻極高,但功能卻十分強大,能夠模擬鋼琴、吉他等傳統樂器的聲音,在電腦上使用MIDI和采樣器。
MIDI是一種按時序記錄聲音高低的數碼協定,比如我在3分零626秒彈奏了一個音符,它會記錄這個音符的音高和時刻。透過記錄一系列這樣的數據,最終可以用電腦合成出完整的音樂作品。
進入 2.5時代 ,音樂產業經歷了一次重大變革。騰訊音樂娛樂集團推動了音樂娛樂的商業化,使得這個行業的收入達到了500億,並讓音樂人真正能夠賺到錢。
與此同時,音樂生產工具也逐漸實作了移動化。例如,有一種工具可以在電腦和手機上使用,並且功能也變得越來越強大。同時,可以利用AI生成數碼化的訊號。
正在到來的就是 音樂生產工具3.0 —— 音訊模型 ,這類工具類似於語音的TTS模型。
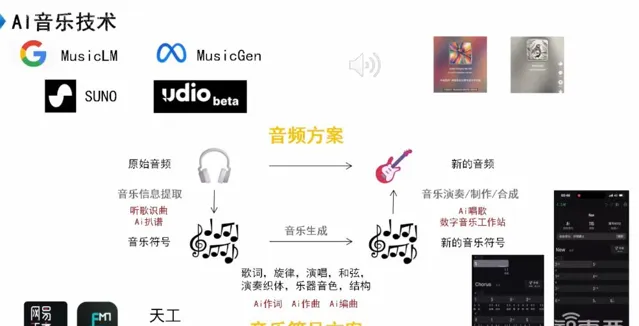
在音樂領域,AI的生產方向大致可以分為兩類: 音訊方案 和 音樂符號方案 。
在音訊方案中,我們公司於2018年開始專註於音樂AI。當時音訊模型尚未成熟,基本上是透過將數以百萬計的歌曲進行標記,並將自然語言模型與音訊模型對應起來,以便透過一些Prompt來生成音訊。
在那個時期,由於音訊模型尚未成熟,大多數AI公司致力於音樂符號方案。
音樂符號方案的核心思想是從我們平時聽到的歌曲中提取音樂資訊,包括歌詞、旋律、演唱方式、和弦行程、使用的樂器以及樂器的音色等,然後對這些資訊進行數碼化標註。透過對這些音樂符號進行訓練,可以生成新的音樂符號。最後,透過傳統的音樂制作流程,將這些音樂符號渲染成音訊。
這個過程涉及到三個主要技術領域:首先是音樂資訊提取技術,通常用於聽歌識曲等功能;其次是AI作詞、AI作曲、AI編曲等技術,用於生成音樂符號;最終,將符號轉化為音訊的過程,就是以往數碼音樂工作站所做的工作。
三、推演爆款音樂生成產品的技術方案,打造一站式音樂工作站
最近大家可能註意到Suno和Udio等產品頻繁出現在螢幕上,但實際上技術突破來自於 MusicLM 和 MusicGen 。
這兩者是最早能夠透過自然語言與音訊進行對位,並逐幀生成音訊的技術,這是一種顛覆性的進展,首次出現在前年年底到去年年初。而後出現的Suno和Udio則采用了音訊方案,如網易天音,還有例如天工SkyMusic,他們采用的是符號方案。
音訊方案和符號方案各有特點。音訊方案是端到端模型,使得生成的音樂聽起來更貼近真實、完整,融合度更高。而符號模型則能夠控制生成內容的各個方面。我們認為未來這兩種模型會融合發展。
MusicLM和MusicGen大致能夠生成的自然語言Prompt背景音樂作品,會有一個顯著的前景旋律,這對於推斷它們的技術實作方式將會非常有幫助,能判斷出這些作品都是基於音訊方案生成的結果。符號方案生成的音訊聽起來可能音質更高,但伴奏和人聲的融合程度沒那麽好,純BGM大概就是這種效果。
符號方案和音訊方案使用了 不同的技術棧 。
在我們的符號方案中,我們采用了領先的演算法。我們使用一個標註工具來處理數據。以大家耳熟能詳的【七裏香】為例,在我們的標註工具中,頂部的藍色波形代表音訊檔,我們需要標註其中的關鍵樂理資訊。

首先,自動辨識出這些藍色線,將它們與上方的11、12、13小節線對齊;接下來,標註旋律、歌詞、和弦、段落以及調式等音樂中重要的樂理資訊;一旦完成了這些標註,就可以使用單模態生成旋律,生成旋律和歌詞的對位,或者根據輸入的歌詞生成伴奏和旋律。有了大量這樣的數據,我們就可以開發出生成式AI模型。
由於音訊方案的火爆產品並未公開其具體實作方式,我們透過大量實驗進行推測,和大家分享我們對AI和音樂結合的認知。我們認為這種生產方式顛覆了我們對智能技術的認知。
最近,音訊模型產品火了起來。我們看到這些產品的體驗大致是這樣的:輸入一段歌詞和一些Prompt,就能生成完整音樂。
根據我們的推斷,它的演算法可能是這樣的:首先,有了一批音樂數據,同時標註了對應的歌詞。這種數據在QQ音樂等平台上都可以直接獲取。另外,現在已經有一項成熟的技術叫做人聲伴奏分離,可以將音訊中的人聲和伴奏分離開來。
現場演示的人聲裏帶有和聲。在訓練時,我現在只看到前三行,大概是將音訊進行切片,然後透過一個分離的BGM和其中標註的歌詞來生成最終完整的音樂。這是模型大概的工作原理。
因此,我們最終看到的是,輸入一個Prompt,它會從一個BGM庫中找到與之最匹配的音訊片段,然後根據輸入的歌詞或者想要的樂器,在原始音訊上疊加一個人聲模型。它們對音樂的理解與我們不太一樣,它們將音樂理解為一個人聽著伴奏,朗讀歌詞的TTS模型。整個過程是一個端到端的模型,所以在整個音樂中,伴奏和人聲的融合效果非常好。
四、一站式低門檻音樂創編軟件「和弦派」:解決可控性、相容性、跨平台三大挑戰
我剛剛分享了一下音樂行業的整體情況,以及音訊模型、符號模型等的大致工作原理。現在我想分享一下我們自己的產品,叫做「 和弦派 」。它是一個移動端一站式的低門檻音樂創編軟件,AI在其中發揮了很大的作用。我們希望透過這個產品解決幾個問題。
第一,我們希望AI是 可控的 。但是在音樂中,我們重新定義了控制的方式。例如,我們現在談論如何描述音樂知識,大多數人可能首先想到的是五線譜。然而,五線譜是兩百年前的產物,當時還沒有留聲機。五線譜的目的是記錄音樂應該如何演奏,而不是現在流行音樂中常見的記錄方式。我們希望音樂有一種更直觀的控制方式。
第二,過去我們在創作音樂時,可能會用Word來寫歌詞,用錄音機來錄制曲子。我們希望能夠將這些功能整合到一個平台上,實作 一站式的音樂創作體驗 。另外,在制作人和音樂人這個行業,每個人購買的音源可能不同,這就導致了互相之間的工程檔無法相容的問題。我們希望能夠解決這個問題,讓不同音源之間的工程檔能夠互相相容。
第三,我們希望能夠 在手機上完成創作音樂 這件事情,而不是開啟電腦。然而,在手機上進行音樂創作確實存在很大的困難。例如,在安卓系統下,實際上沒有一個很好的音訊引擎來支持這項開發工作。因此,我們花了很多時間去開發跨平台的音訊引擎,以解決這個問題。
我們的整體設計思路如下,這是音樂功能譜。首先,我們意識到這個產品並不是面向全人類的,而是針對人類中大約10%的使用者。功能譜基本上是音樂愛好者需要了解的內容,其中包括段落和和弦,告訴樂手如何演奏;還包括旋律和歌詞,告訴歌手如何演唱。
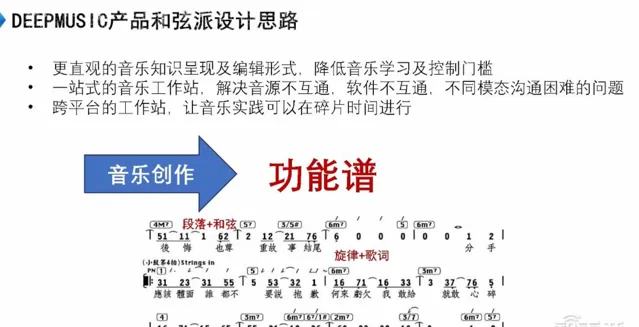
流行音樂並不那麽復雜,通常只包含一個伴奏和一個人聲。人聲部份由數碼表示,例如「Do、Re、Mi、Do、Re、Mi」,並附帶歌詞,以指導歌手的演唱。而剩下的段落和和弦則指導所有樂器如何演奏。簡而言之,就是這兩部份構成了音樂功能譜。
我們透過創作功能譜或者采用其他方法呈現,創造了音樂。將功能譜轉化為聲音,這是音樂創作;將功能譜變成我們能聽到的音樂,這是音樂制作。這個過程最終形成了我們的產品—— 和弦派 。
在和弦派中,我們提供了一個功能譜的編輯頁面。你可以隨意輸入和弦、旋律和歌詞。透過AI輔助編曲功能,你可以生成伴奏;透過AI的歌聲合成功能,你可以讓這些輸入內容被演唱出來。
借助大量的詞、曲和和弦對位數據,我們能實作旋律生成和弦、和弦生成旋律等功能。這意味著你可以輸入一段歌詞,我們就能為你生成一首完整的歌曲;或者,你哼唱一段旋律,我們能為你配上和弦和伴奏。這一切都可以在一個軟件中一站式完成。
針對不同的使用者,我們提供了各種互動式體驗。例如,對於中度實踐使用者,基於大型語言模型的理解能力,能生成歌詞,並根據這些歌詞生成音樂的其他資訊;對於深度實踐使用者,他們通常已經理解了和弦的概念,但可能對和弦的具體細節不夠了解;對於更深度的音樂人,他們可以編輯所有的和弦,調整音高,並修改歌詞,以快速建立所需的BGM。
我們可以關閉吉他軌域,換成電吉他,並調整演奏方式,即使不懂吉他也能自由創作。我們已經有許多使用者透過這種方式制作出了不錯的作品,其中有些甚至深深打動了我。
我們的整體產品都能在一個手機軟件裏一站式輸出。我們堅定地致力於移動端產品,因為我們相信許多00後和05後的孩子並不太習慣使用電腦。我們預見未來的音樂制作大部份流程都將在手機上完成。只有在最後需要進行精細調整時,才會轉移到電腦上進行。
五、2025或實作AI生成伴奏,上傳30秒人聲就能用自己聲音演唱歌曲
讓我們來談談我們對音樂產業未來發展的看法。
首先,我們認為 在音樂消費端,AI和大數據等技術的發展不會帶來太大的變化 。因為音樂行業本身就是一個供大於求的行業,AI的出現雖然提高了生產效率,但並不會對行業生態造成巨大的影響。然而,在音樂生產端,我們相信將會有越來越多的人參與其中,進行實踐,從中獲得樂趣。

新的音訊模型可以透過一個簡單的Prompt生成出完整的BGM,而TTS模型可以生成完整的歌曲。接下來,我們可以預見,人們將能夠自己制作個人化的BGM,並在其上填寫歌詞。每一句歌詞都可以重新編輯,例如,如果覺得第二句不夠理想,就可以重新編寫。
與此同時,音量調整也將變得更加靈活。我們相信,在今年年底,不止一家公司將推出這樣的產品。到那時,音樂制作過程將變得更加普及化。音樂人們可能會首先選擇一個自己喜歡的BGM,然後利用語言模型為歌詞尋找靈感,並逐句進行修改和嘗試。最終,他們可以按照傳統的錄音和音樂制作工作流程完成作品,並進行釋出。
明年大概就能實作自然語言生成伴奏的功能,而且音質應該也會相當不錯。你只需上傳大約30秒的人聲素材,就能夠用你自己的聲音來演唱歌曲。音質會達到基本可用的水平。
到那時,我們就可以摒棄傳統的錄音或者「MIDI+采樣器」的工作流程,轉而使用「BGM+歌詞」的輸入方式。我們只需要進行簡單的粗顆粒度修改,利用音訊模型調整音樂,直到滿意為止,然後就可以直接發行作品。
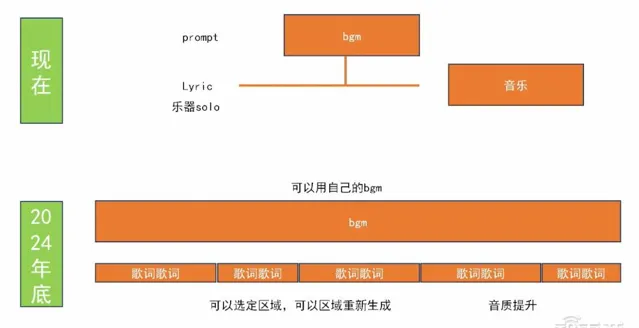
那時我們對於音樂制作工具的理解可能會回歸到我設定一首歌,包括前奏、間奏和副歌等部份,然後在其中輸入歌詞。我們可以將歌曲分割成不同的區域,並在每個區域選擇不同的樂器庫。使用者可以透過拖拽樂器到相應的區域,並指示該樂器的演奏方式,最終就能夠生成整首音樂。
最終實作這樣的體驗,必然需要結合錄音、MIDI、采樣器以及音訊模型等技術。國內在音訊模型方面可能會有一些差距,但我們堅信,對於未來面向音樂人和音樂愛好者的產品,我們所做的積累毫無疑問是有意義的。
以上是劉曉光演講內容的完整整理。











