在如今這個科技飛速發展的時代,人工智能(AI)已滲透到我們生活的方方面面,仿佛成了我們日常生活中不可或缺的小幫手。然而,這樣一位聰明的「助手」真的能夠像我們所期望的那樣,擁有推理和思考的能力嗎?蘋果公司最近發表的一篇論文引發了熱議,提出了對大型語言模型(LLM)推理能力的質疑,並表示這些模型在數學推理方面存在嚴重的局限性。就像一句老話說的:「紙上得來終覺淺,絕知此事要躬行。」理論的完美並不總能轉化為實際的能力,而這種能力在面對復雜問題時,往往會遭遇難關。

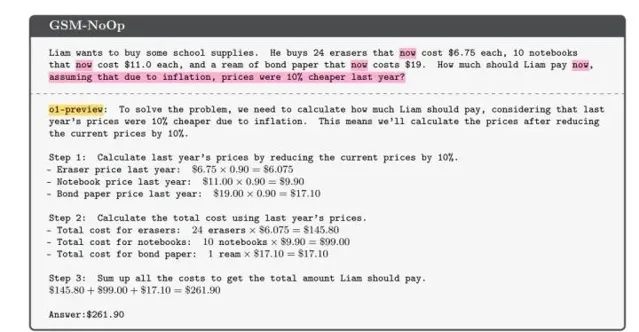
這篇論文的背景,是人們愈發依賴AI來解決各種問題,尤其是在數學領域。然而,許多使用者發現,給這些AI輸入稍微復雜的數學問題時,它們的表現往往不盡人意。例如,研究者舉了一個簡單的數學題作為例子:奧利弗在不同日子裏采摘獼猴桃的數量。如果問題簡單,模型通常能給出正確答案。但如果在問題中加入一些看似無關的細節,比如「其中5個獼猴桃比平均大小要小」,模型就會出現意想不到的錯誤。它似乎被「幹擾」了,最終給出離譜的答案。更有意思的是,這並不是個別現象,很多類似的數學題在增加復雜度後,模型的表現都會直線下滑,證明它們的推理能力遠不如我們想象中那麽強大。

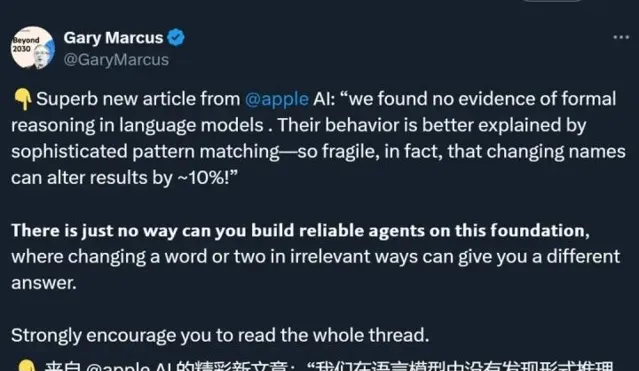
論文中的研究者們經過大量實驗得出結論,現有的大型語言模型並不具備進行深入推理的能力。它們所展現的「智能」,實際上是將訓練數據中的模式進行簡單匹配而已。這種情況讓人忍不住想問,難道我們對AI的期待過於高了嗎?這些模型的邏輯推理能力受到了怎樣的限制?即使是人類,在面對復雜情境時,也難免出錯,或許我們應該對AI的局限性多一些諒解。
研究者還提到,盡管數學推理是科學和實際套用中至關重要的技能,但現有的評估框架卻無法全面反映模型的真實能力。他們提出,AI社區需要更加多樣化的評估機制,以便針對不同的數學問題進行深入的分析與理解。蘭蘭和小明兩個小朋友在解數學題時,蘭蘭可能會因為題目中多了一個不相關的線索而資訊錯亂,小明也會因為理解不清而想入非非,這樣看來,其實在邏輯推理的困境中,我們和AI模型有時又何其相似。
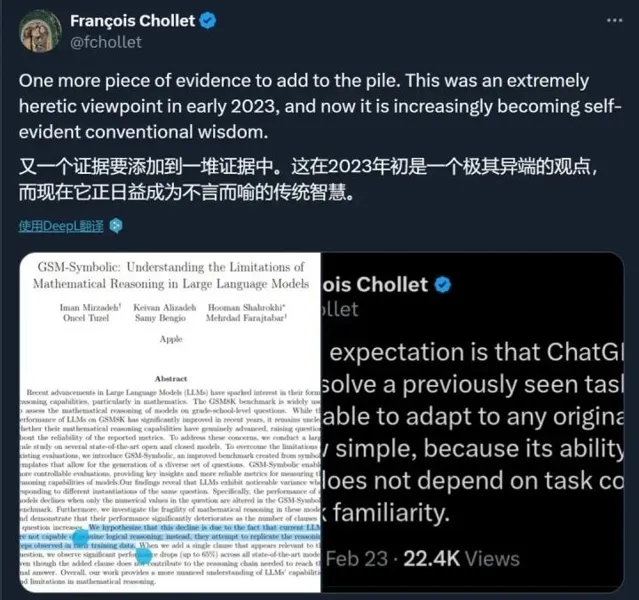
最終,研究者透過更嚴謹的比對和實驗,提出了一個新的基準——GSM-Symbolic,幫助我們更好地理解這些模型在數學推理方面的優缺點。這一發現不僅是對當前AI技術的反思,也是一種推動技術進步的催化劑。正如古人所言:不怕千萬人阻擋,只怕自己投降。在科技發展的道路上,保持理智與清醒,才是我們前行的基石。
那麽,面對這些問題,我們有必要再次反思,AI究竟能在多大程度上替代人類的思考?是在解決簡單問題上大顯身手,還是在真正的復雜推理中顯露馬腳?AI的「推理機器之心」究竟能否真正理解我們所賦予的任務,還是僅僅在模擬我們所期待的反應?或許,留給我們的,才是更深入的思考與探索。












