文 | 追問nextquestion
追 問快讀:
1. 當下流行的神經網絡都將神經元的傳遞簡化為開關操作,但這是不正確的。脈沖神經網絡試圖透過脈沖序列和時間編碼的方式,模擬生物神經元的動態活動和時間依賴性。
2. 新的訓練脈沖神經網絡的演算法——基於資訊瓶頸的學習模型,透過模擬人類和生物的學習方式,允許系統在接收即時反饋的同時進行學習,並首次將工作記憶和突觸權重聯系起來,這可能為下一代人工智能的發展提供啟發。
神經元不僅僅是一個開關
1876年,意大利物理學家Luigi Galvani在一次偶然實驗中發現,靜電可以讓死青蛙的腿動起來。這一發現不僅揭示了神經系統對電訊號的反應,也無意中探索到了控制青蛙肢體的「開關」。但實際上,生物體中神經元不只是開與關的關系,它們的相互作用要復雜得多。如這涉及膜電位變化、軸突傳遞等更復雜的過程*。
當神經元接收到足夠的刺激時,細胞膜上的離子通道會開啟,允許特定的離子(如鈉離子Na+和鉀離子K+)透過。這個過程導致細胞內外的電位發生變化,形成動作電位。動作電位的產生是一個全或無的現象,一旦達到閾值,電訊號就會沿著神經元的軸突傳遞,最終透過突觸將訊號傳遞給下一個神經元。之後這個神經元需要休息一段時間(不應期,此時神經元對新的刺激不敏感,無法產生新的動作電位),才能夠再次傳遞訊號。
當下流行的神經網絡, 不論是影像辨識的摺積神經網絡(CNN),還是處理自然語言的Transformer,神經元的傳遞都被簡化為一個開關操作。 人工神經元的訊號傳遞,是純數學的,理論上可以立即完成(實際受限於電腦的處理速度)。然而,與忽略訊號傳播時間的主流人工神經網絡不同,近年來備受關註的第三代神經網絡——脈沖神經網絡(SNN),則試圖以更加仿真的方式,去模擬神經元的活動。
在SNN中,神經元的啟用是透過脈沖序列來表示的,這些脈沖在時間上是有間隔的,而不是像傳統的人工神經網絡那樣立即完成。這種時間編碼方式使得SNN能夠捕捉到輸入訊號的時間動態特性,這在處理時間序列數據或需要考慮時間依賴性的任務中尤為重要。
在SNN中,神經元的啟用不是簡單的開關行為,而是考慮了神經元膜電位的動態變化以及離子通道的開閉對電位的影響。 當膜電位達到某個閾值時,神經元會發射一個脈沖,然後迅速復位到靜息電位,這個過程稱為「脈沖發放」。
然而,在當下的人工神經元中,決定神經元是否啟用的函數,如sigmod或tanh,都是連續可微分的,而 脈沖神經網絡中的神經元則是階躍函數 , 即當膜電位達到閾值時,神經元立即發射脈沖,否則不發放。 這個階躍函數在脈沖發射點是不可微的,因為它的導數在這一點上是未定義的。這使得訓練脈沖神經網絡變得不那麽簡單。
而最近的一項研究, 來自NeuroAI的研究者不僅提出了一種能夠訓練脈沖神經網絡的演算法,還指出該方法在生物學上和大腦的神經活動遵循著同樣的約束——即資訊瓶頸。

▷ Daruwalla, Kyle, and Mikko Lipasti. "Information bottleneck-based Hebbian learning rule naturally ties working memory and synaptic updates." Frontiers in Computational Neuroscience 18 (2024): 1240348.
https://doi.org/10.3389/fncom.2024.1240348
資訊瓶頸—— 學到真知需要先忘記
資訊瓶頸理論起源於消息理論中的互資訊概念(Mutual Information,衡量了兩個隨機變量之間的共享資訊量),最早由Tishby提出*,後被用於解釋人工神經網絡的執行機制。現在,我們就用一個關於食品的雙關比喻來說明資訊瓶頸是如何揭開神經網絡中神秘的面紗的。
Tishby, Naftali, and Noga Zaslavsky. "Deep learning and the information bottleneck principle." 2015 ieee information theory workshop (itw). IEEE, 2015.
假如我們要制作一種特殊的壓縮曲奇,需要從各種面點中提取出最關鍵的成分來決定曲奇的配方。這就像是 我們需要透過一個特殊的「篩選器」來找出最重要的資訊,這個過程就是資訊瓶頸理論的核心。
在這個理論中,我們把所有面點的成分看作是輸入(X),壓縮曲奇的成分是輸出(Y)。首先,我們需要一個「編碼器」來處理輸入的面點成分,把它轉換成一個中間的形式(T),這個過程就像是從各種面點中提取共性,去除不需要的差異,正如物理上的壓縮一樣。然後,一個「解碼器」再把這個中間形式轉換成最終的輸出,也就是曲奇的成分。
在這個過程中,有一個參數β,它決定了我們在篩選資訊時,保留多少原始面點的資訊。這就像是我們在做題時,決定在草稿紙上保留多少關鍵步驟一樣。
透過這樣的模型,研究者可以找到模型中的關鍵特征,最佳化決策過程,提升學習效率。在更復雜的多層神經網絡中,每一層的處理也可以看作是一個小的資訊篩選過程,其資訊瓶頸問題可以透過Hilbert-Schmidt Independence Criterion(HSIC,如下圖)來分析。
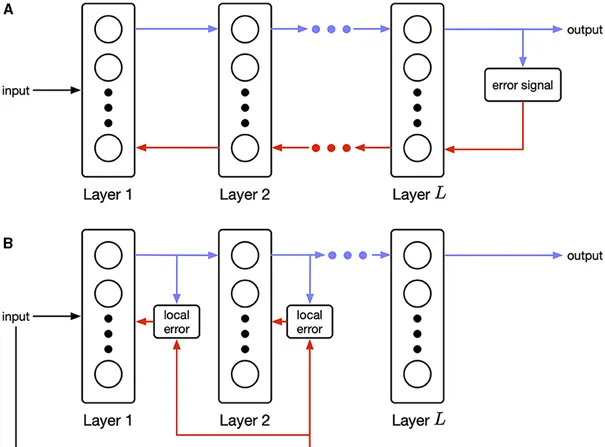
▷ 圖1:(A) 順序錯誤傳播(傳統的反向傳播)要求層與層之間進行精確的資訊逆向傳遞。(B) 並列錯誤傳播則僅依賴局部資訊,並結合全域調節訊號。這種類別的生物學規則被稱為三因素學習規則。
而要構建一個好的人工智能模型,我們需要給每一層網絡足夠的「臨時儲存空間」,就像我們做不同數學題時需要草稿紙一樣。這可以透過一種叫做「儲備池計算」(Reservoir Computing)的方法來實作。
儲備池裏面充滿了隨機稀疏連線的人工神經元。它們可以是傳統的連續可微的,也可以是脈沖式的。而這個儲備池中有多少個人工神經元,則可視為工作記憶的大小。我們透過調整這些神經元的連線強度,改善模型的學習效果。由此,一個生物學上符合類腦的脈沖神經網絡如圖2所示,而其中的學習規則是局部基於赫布法則和資訊瓶頸來設定的。

▷ 圖2:整體網絡架構如上圖所示。每個層都配有一個輔助的儲備網絡。突觸更新參數β受到一個層級的錯誤訊號ξ的調節,這個錯誤訊號是從儲備網絡中獲取的。
我們再回到壓縮曲奇的比喻,假設我們有一個機器,它的任務是區分不同類別的壓縮曲奇。每種曲奇都由不同比例的成分(如碳水化合物、蛋白質等)組成。我們註意到,某些成分經常會一起出現,比如碳水化合物和蛋白質。基於資訊瓶頸原理,如果兩種成分經常一起出現,我們就可以用更少的資訊來記錄它們。
而前面提到的「儲備池」就像是我們在決定成分比例時用的草稿紙,幫助我們記錄和計算資訊。透過這樣的學習和調整,我們的模型學會了一種辨識壓縮曲奇的規則,多個規則組合後,就形成了辨識壓縮曲奇的模型。
有待提升的學習規則
資訊瓶頸的理念在用於影像分類的小數據集Minst已經展示出其效力,達到了91%的準確度,而在包含更多圖片和類別的大數據CIFAR-10上,該模型也取得了大約61%的準確率,如圖3所示。 盡管與傳統方法存在差異,但這一成果驗證了資訊瓶頸原則在處理復雜數據中的套用潛力。

▷ 圖3:在MNIST和CIFAR-10數據集上,研究者對反向傳播和資訊瓶頸方法進行了多次測試,並計算了平均測試準確度。MNIST網絡是一個具有128和64隱藏神經元的全連線感知機。CIFAR-10網絡是一個具有128和256特征的摺積,之後是一個單一的完全連線的輸出層。
工作記憶是我們認知系統中至關重要的一部份,它使我們能在回憶儲存的知識和經驗的同時,繼續進行其他任務。在實驗中,當模型的工作記憶容量從最初的僅能處理2幅圖片資訊增加到能處理32幅圖片時,模型的預測準確度有所提升,且學習率也有提升——即所需的訓練輪次減少。然而,記憶容量的增長和效能提升之間存在對數關系,暗示著收益遞減的效應。這一現象為工作記憶的容量與學習效率之間的關系提供了實證支持。
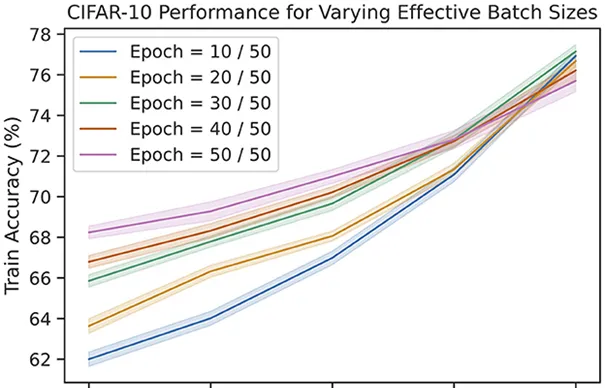
▷ 圖4:CIFAR-10數據集上,使用資訊瓶頸的規則時,不同的有效批次大小時模型再不同訓練批次的準確度。
雖然相比傳統的反向傳播,基於資訊瓶頸的模型在準確度上仍有差距,但這種模型能夠讓學習系統即時接收反饋,更貼近生物學上的學習機制。 在我們的大腦中,神經元間的連線一直在變化和調整,這並不是說你可以暫停一切,調整,然後繼續做你自己。
反向傳播的訓練和實際套用是分開的,仿佛是學生在一個學期內集中學習,然後在考試中檢驗所學,而在學習階段,我們無法對它的水平進行即時判斷。而基於資訊瓶頸的新模型則類似於人類的學習方式,就像小孩在看到一個新影像時詢問父母這是什麽,即使父母未能回答,孩子也能依據以往的經驗和反饋進行推斷。這種‘隨插即用’的過程,更適應生物透過自然選擇的方式,對於需要快速反應的任務尤其有效。
盡管還沒有證據說明類似圖2的網絡結構在腦中真實存在,但該研究提出的基於資訊瓶頸和局部可塑性(赫布法則)的模型,已被證明可以在復雜的大數據上進行學習,以及在執行簡單非線性函數的分類任務上達到近乎完美的準確性。由此,可說明 該模型提供了一種新的,不依賴反向傳播的學習方法,並首次將工作記憶和突觸權重聯系起來,這可能為下一代人工智能的發展提供啟發。











