電氣化之後智能化,汽車的智能化怎麽也脫不開人工智能AI,無 AI 不智能這是大家所有人的共識了。
但,到底AI是什麽?它在汽車行業套用的發展是怎麽樣的?大家競相宣傳和討論的端到端到底什麽?它和之前其他AI演算法有什麽區別?此類問題卻常讓大家競相莫名圍觀吃瓜。
所以,本文將結合AI在汽車行業的套用和發展,總結下
人工智能
機器學習
深度學習
端到端
等 AI 人工智能 101概念內容,幫助大家了解AI,以及它在智能汽車中的套用和發展,也方便理解前熱門的各類概念和事件。
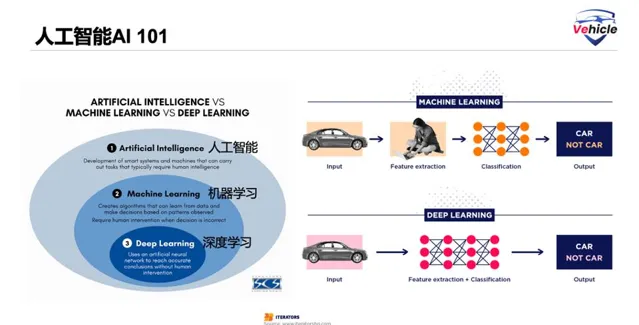
人工智能(Artificial Intelligence, AI)
人工智能是一門在電腦中模擬智能行為的科學。它使電腦能夠展現出類似人類的行為特征,包括知識、推理、常識、學習和決策能力。
他們的核心就是多層的神經網絡(Neural Networks),神經網絡是一種電腦架構,它模擬了人腦的結構,AI/機器學習程式可以在此基礎上構建。
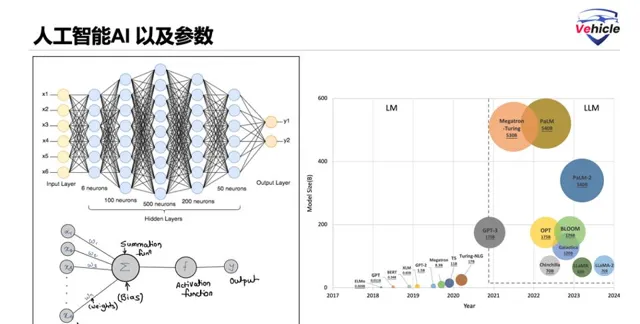
神經網絡由相互連線的節點組成,這些節點可以解決更復雜的問題並進行學習,類似於人腦中的神經元,每個節點用權重,偏差等參數去計算傳導到下一步,產生結果。
所以,參數等成了當前模型的一個重要參考指標,理論上參數越多代表模型學習更完善,產生結果更真實,在今年輝達的 GTC 上,Jensen 透露了一條關於當今最大模型的看似有趣的訊息,稱「當今最大的模型是 1.8T 參數「。
機器學習(Machine Learning)
機器學習是人工智能的一個分支,它使電腦能夠在沒有明確編程的情況下從數據中學習。例如,電腦可以透過數據學習辨識狗或貓等物件。
所以智能駕駛最開始的Mobileye就是采用視覺機器學習,讓車輛辨識前方車輛,行人單車等VRU,前方道路線,交通標誌等,這樣實作了AEB,LCC車道保持等功能。
傳統的機器學習方法需要大量的人力來訓練軟件。例如,在自動駕駛施工道路的障礙物辨識中,需要做以下操作:
手動標記數十萬張施工道路以及相關標誌的影像。
讓機器學習演算法處理這些影像。
用一組未知或者叫泛化的影像上測試這些演算法。
找出某些結果不準確的原因。
透過標註新影像來改進數據集,以提高結果準確性。
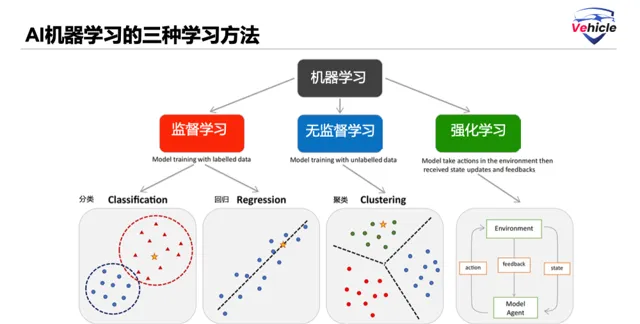
這個過程稱為有監督學習。在有監督學習中,只有廣泛且充分多樣化的數據是準確率的前提。例如,該演算法可能可以準確辨識放置非常正面的施工道路牌,但不能準確辨識斜向放置的施工道路牌,因為訓練數據集包含更多正面施工道路影像。在這種情況下,那麽就需要標記更多的斜向放置的施工道路牌影像並再次訓練機器學習模型。
國內汽車智能駕駛大概在2019年左右,都在透過大量的人工數據采集和標註的方式,瘋狂透過這種方式訓練學習模型,最後在2019年特斯拉推出其演算法之後,所有訓練數據和演算法推倒重來。
深度學習(Deep Learning):
深度學習是機器學習的一個子集,深度學習擁有更多的分層的層級結構。例如,在辨識施工道路牌的例子中,不同的層可能對應於給定施工道路牌的關鍵特征。
所以,深度學習能夠高效處理非結構化數據,發現數據之間隱藏的關系和模式,它能夠做到無監督學習Unsupervised learning,強化學習Reinforcement learning (RL)。例如施工道路牌,它能夠辨識逆光,殘缺甚至倒地的施工道路牌。
強化學習(RL),可以訓練軟件做出決策,以實作最佳結果。它模仿了人類為實作目標所采取的反復試驗的學習過程。有助於實作目標的軟件操作會得到加強,而偏離目標的操作將被忽略。
ChatGPT剛推出那會兒,Open AI就對使用RL做了簡單介紹,RL 演算法在處理數據時使用獎懲模式。這些演算法從每個操作的反饋中學習,並自行發現實作最終結果的最佳處理路徑。此類演算法還能夠實作延遲滿足。最好的整體策略可能需要短期的犧牲,因此其發現的最佳方法可能包括一些懲罰,或在過程中有一些迂回。RL 是一種強大的方法,可以幫助人工智能(AI)系統在看不見的環境中實作最佳結果。
當人工智能演算法可以無監督和自我強化學習,對於人工智能最重要的事情就剩下:
大量高質素的數據 ,在大量高質素數據上訓練深度學習演算法時,可以獲得更好的效果。輸入數據集中的異常值或錯誤會顯著影響深度學習過程。例如,在我們的動物影像範例中,如果數據集中意外引入了非動物影像,深度學習模型可能會將飛機歸類為海龜。為避免此類錯誤,必須先清理和處理大量數據,然後再訓練深度學習模型。輸入數據預處理需要大量的數據儲存容量。
強大的算力芯片中心 ,深度學習演算法是計算密集型的,需要具有足夠計算能力的基礎設施才能正常執行。否則,它們需要很長的時間來處理結果。
能源 ,數據儲存處理以及計算消耗的能源成為繼物理做功之後又一重要消耗,這也是為什麽最近Open AI Sam柯曼多次不同場合表示對核電感興趣。

在此類人工智能演算法的背景下,理想條件下,只需要餵養高質素數據,在強大算力,和豐富能源供給的條件下 AI 可以給人類帶來無窮的套用。
端到端方法( End-to-End Approach)
在2023年,特斯拉開始宣布端到端的智能駕駛演算法,他所謂的端到端方法是一個單一模型,它直接從視覺輸入到輸出駕駛策略,如轉向和制動。這種方法減少了人工編碼的需求,並可能有助於解決迄今為止限制自動駕駛進展的邊緣情況。
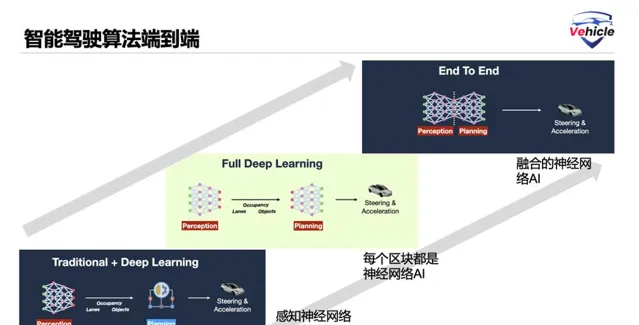
熟悉智能駕駛應該大概都了解,智能駕駛幾要素,感知,定位,規劃,控制等流程。目前智能駕駛演算法組合大概有三種方式:
感知采用AI神經網絡+規則控制
各個區塊都采用神經網絡
端到端融合神經網絡
特斯拉算是從第一個走到了第三步。
其實目前大都在第一步和第二步此類的復合解決方案,它可以使用AI處理不同的子系統或輸入。然後,這個解決方案可以與組合不同的程式碼一起使用,或者覆蓋其他規則/因素(例如,確保遵守某些交通法規)。
盡管有爭議,這種復合方法是否會限制AI在難以理解的長尾邊緣情況場景中所能達到的程度,但它:
很有效率 (例如,ChatGPT不需要使用AI訓練來解決基本數學問題,它可以直接查詢小算盤模組),
可能更容易理解/驗證(這在駕駛中尤其重要,因為AI的錯誤可能是致命的)。
仍然使用高級AI技術,如Transformer,Occupancy等等。
這些概念為理解AI在自動駕駛汽車中的套用提供了基礎,並解釋了不同AI方法如何影響技術的開發和實施,目前很難說誰好誰不好。
其他汽車人工智能套用
其實,語音算是在智能汽車上套用最廣和最快的,畢竟人工智能發展最快的就是語音和文本模型,例如ChatGPT 此類LLM大語言模型激發了智能駕駛端到端,基本 AI 原理雷同,目前沒有說主機廠自研語音演算法的,主要是這個產業已經發展完備,集中頭部供應商提供解決方案。
當然,智能駕駛也應該快速走向這個過程,頭部供應商提供解決方案,畢竟最終路徑和技術趨同統一,大家都沒有必要重復造輪子了。
*未經準許嚴禁轉載和摘錄-參考資料:
-
Can new AI technology help accelerate AV deployment?- 高盛











