大家好,今天要給大家推薦一款堪稱全能的開源Markdown格式檔提取器— MinerU 。

這款開源工具不僅在GitHub上收獲了6.9k的星星,還憑借其強大的數據提取功能俘獲了大量開發者和內容創作者的青睞。
MinerU專案介紹

MinerU 是一款一站式的高質素數據提取工具,主要功能包括從PDF、網頁和電子書中提取數據,並將其轉換為Markdown格式。
它包含兩個核心模組: Magic-PDF和 Magic-Doc 。
無論是處理繁瑣的PDF文件,還是從網頁和電子書中提取有價值的資訊,MinerU都能夠輕松應對。
該專案采用PyMuPDF以實作高級功能。

Magic-PDF:PDF文件的神奇轉換
Magic-PDF 是專為將PDF文件轉換為Markdown格式而設計的工具。它不僅支持本地文件的轉換,還能處理儲存在支持S3協定的物件儲存上的檔。主要功能包括:
Magic-Doc:網頁與電子書的全能提取
Magic-Doc 則主要負責將網頁或多格式電子書轉換為Markdown格式,其功能同樣令人印象深刻:
作為一個程式設計師,Markdown格式文件使用的比較多,對於md格式的閱讀習慣很深,而MinerU可以輕松實作從各種PDF文件、網頁和電子書中提取數據並整理成Markdown格式。
這對於我來說,簡直是一大福音,省了不少事情和精力。
精準辨識版面元素,自動刪除頁首頁尾資訊,保留正文圖表

精準解析數學復雜公式
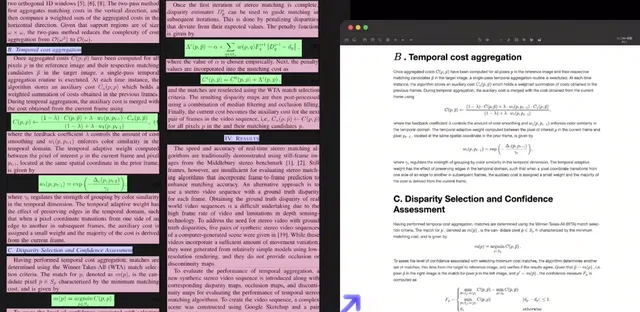
跨模態解析CSDN網頁文章
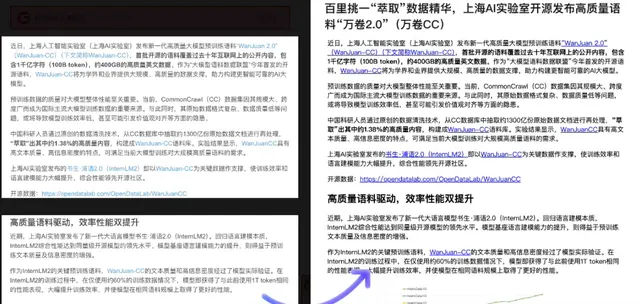
更加支持多種格式文獻轉Markdown

至於使用的方式,最方便的當然是官方線上Demo:
https://opendatalab.com/OpenSourceTools/Extractor/PDF
也可以自己依據專案說明進行本地或線上部署,畢竟人家是開源的(不過部署起來有些許麻煩,涉及許多配置及模型)
具體的需存取GitHub專案主頁(https://github.com/opendatalab/MinerU),根據文件進行安裝配置,即可開始使用。
總結
總的來說,MinerU是一款非常實用且強大的數據提取工具。無論你是開發者、互聯網從業者,還是有具體需求的新人小白,MinerU都能極大地提升你的工作效率,讓你專註於更有價值的工作。
最後,如果你對MinerU感興趣,不妨親自嘗試一下,相信你會愛上這款全能的Markdown格式檔提取器。











