【引言】
在語音通訊、辨識以及合成這些領域,語音增強技術那可是相當重要。不過呢,因為有環境雜訊,語音訊號常常會被幹擾,使得語音質素變差,資訊也失真失。所以,研究怎樣有效地把語音訊號增強,這就特別關鍵。傳統的語音增強辦法一般是依據訊號處理的技術,像濾波、譜減法,可這些辦法通常很難精確地把原始語音訊號的質素給恢復過來。
【相關工作】
傳統的語音增強辦法大多是依靠訊號處理的技術,像濾波和譜減法。在這當中,濾波的方式是設計一連串的濾波器,把雜訊成分給減弱掉,從而讓語音訊號的質素得到提升。譜減法是在頻域裏對語音訊號展開分析,用減去估算出的雜訊譜的辦法來獲取幹凈的語音譜。但是,這些傳統的法子常常沒辦法精準地把原始語音訊號的質素恢復好,特別是在復雜的雜訊環境當中。
近些年來,深度學習技術於語音增強這一領域有了很突出的進步。深度神經網絡(DNN)作為特厲害的機器學習手段,能夠憑借大量的訓練數據學到語音增強的特征呈現。常見的一個做法是運用摺積神經網絡(CNN)或者迴圈神經網絡(RNN)去學習語音訊號的時頻特點,再透過反向傳播演算法加以訓練。這類深度學習的辦法可以更精準地提取出語音訊號裏有用的資訊,還能壓制雜訊成分,以此達成有效的語音增強。
精確比率掩碼(ARM)屬於在理想比率掩模基礎上改進而來的一種辦法,用在語音增強方面。ARM透過振幅譜之間的歸一化互相關系數去設計比率掩碼,這樣能更精準地估算出幹凈語音譜跟雜訊譜之間的比率關系。這種方式可以有效地讓語音增強的準確性和穩定性提升,進而讓增強後的語音質素變好。ARM常常和其他像 DNN 這樣的語音增強方法一塊用,來進一步把增強效果提上去。
雖說 ARM 在語音增強方面顯示出了不小的潛力,不過當下針對它在單聲道語音增強裏的研究還比較少。所以,這次研究打算把 ARM 和 DNN 結合起來,給出一種新的單聲道語音增強辦法,用來提升語音訊號的質素,滿足實際運用的需要。在後面的章節中,咱們會仔細講講這個辦法的設計原理、實驗安排還有結果分析。
【方法介紹】
精確比率掩碼(ARM)屬於一種對理想比率掩模加以改進的辦法,用在語音增強方面。ARM 的設計思路是憑借振幅譜相互間的歸一化互相關系數,去明確幹凈語音譜跟雜訊譜的比率關系。具體來講,ARM 先算出幹凈語音振幅譜與帶噪語音振幅譜的互相關系數。接著,把互相關系數控制在特定範圍裏,再做歸一化處理,就能得到一個精確的比率掩碼。這個比率掩碼可以精準地體現幹凈語音譜和雜訊譜的比率關系,還能用來增強帶噪語音訊號。
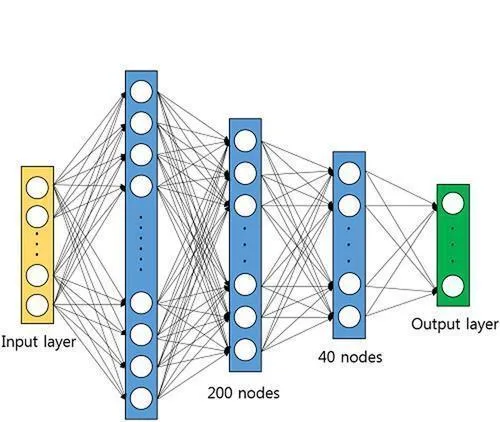
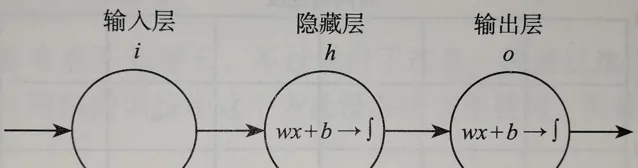
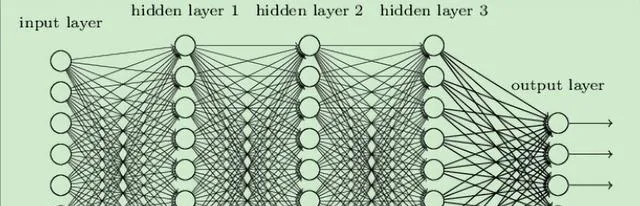
在這個方法裏,咱們用深度神經網絡(DNN)去學著搞語音增強的特征表示。DNN 是多層的神經網絡結構,能靠反向傳播演算法訓練。咱設計了適合語音增強的 DNN 架構,這裏面有好多隱藏層和輸出層。每個隱藏層拿啟用函數做非線性的變換,借權重參數來傳遞資訊和提取特征。輸出層一般用線性啟用函數,然後輸出增強後的語音訊號。
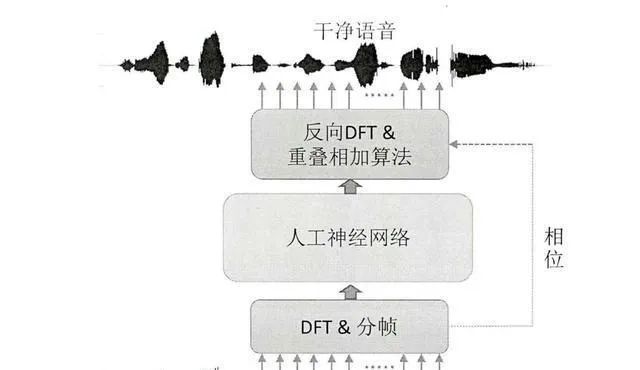
ARM 和 DNN 基礎上的語音增強演算法流程是這樣的:
步驟 1:預先處理
首先,把帶噪語音訊號分成幀,再用傅立葉變換把它轉到時頻域。這樣就能得到帶噪語音的振幅譜和相位譜。
步驟 2:ARM 進行計算
依照 ARM 的設計原理,算出帶噪語音振幅譜跟幹凈語音振幅譜之間的歸一化互相關系數,再加以限制與歸一化操作,就能獲取精確比率掩碼。
步驟 3 :進行 DNN 訓練
把帶噪語音振幅譜和精確比率掩碼當作輸入,放進 DNN 裏去訓練。依靠反向傳播演算法,把 DNN 的權重參數最佳化好,讓它可以學會語音增強的特征表達。
步驟 4:讓預測變得更強
把帶噪語音的振幅譜以及精確比率掩碼放進訓練過的 DNN 裏做預測。DNN 會給出增強之後的語音振幅譜。
步驟 5 :重新構建語音訊號
把增強後的語音振幅譜跟帶噪語音相位譜結合起來,透過逆傅立葉變換給它變回時域,這樣就得到增強後的語音訊號啦。
借助上述的演算法流程,咱們可以把 ARM 和 DNN 整合起來,達成對單聲道語音訊號的增強。隨後,在實驗環節咱們會驗證這個方法的成效,還會做定量和定性的評估。
【實驗設定】
在這次實驗裏,咱們用了一個有著幹凈語音、雜訊以及帶噪語音的數據集。這個數據集涵蓋了各種類別的雜訊,像白雜訊、咖啡店環境裏的雜訊還有汽車雜訊。幹凈語音就是原本沒有雜訊的語音樣本,雜訊是從對應的雜訊環境裏采集來的樣本,帶噪語音是把雜訊跟幹凈語音混一塊弄出來的樣本。數據集得有足夠多和多樣的語音片段,這樣才能保證實驗靠得住和夠穩固。
要評估所提方法的增強成效,咱們透過下面這些指標來做定量評估:
訊噪比的改善(SNR improvement):是看增強後的語音訊號的訊噪比,對比帶噪語音訊號,所提高的程度。
語音失真度(Speech distortion):用來評判增強後的語音訊號跟幹凈語音訊號之間的失真狀況。
語音清晰度(Speech intelligibility):就是用來評判增強後的語音訊號能讓人明白和清楚的程度。
另外,咱們還會開展主觀的評估,依靠人工聽覺來評判增強後的語音在質素和可理解性方面的情況。
在這次實驗裏,咱們把數據集給分成了訓練集和測試集。訓練集是給 DNN 做訓練用的,測試集則用來評估提出的方法表現咋樣。為讓模型的泛化能力更強,咱們用交叉驗證的辦法做實驗,把數據集劃分成好些個子集,還做了多次實驗。
訓練 DNN 的時候,咱得設定網絡的架構以及超參數,像隱藏層的數量、神經元的個數還有學習率啥的。這些參數咋選,得依照經驗還有實驗結果來做調整。咱們會用上一種常見的最佳化演算法,比如隨機梯度下降(SGD)或者自適應矩估計(Adam),去訓練 DNN 並且把參數給最佳化好。
不光DNN的參數得調整,ARM的參數也得調。ARM的設計包含互相關系數的計算還有限制範圍的選定。咱們會依據實驗結果來做恰當的參數調整,從而獲得最好的增強效果。
經過上述的實驗安排和參數變動,咱們要驗證所提出來的方法的表現,還要跟傳統方法做對比,來證實它的出色之處和有效程度。實驗結果會在下一部份展開細致的分析與探討。
【討論與展望】
在這一節,咱們來聊聊實驗結果。依據定量評估跟定性評估的成果,能給咱們提出的基於 ARM 和 DNN 的語音增強辦法的成效做個分析跟探討。能比較一下這個辦法和傳統辦法的不同,也研究研究增強效果的變化走向。另外,實驗裏的一些特殊狀況和不正常結果也能拿來討論,這樣能更明白這個辦法的效能咋樣。
在這一節,咱們仔細聊聊所提方法的好處和不足。根據實驗結果還有分析,能搞清楚這個方法相比傳統辦法的長處和改進的地方。就好比,能說出來這個方法在提升語音清晰度、降低語音失真上的優點。與此同時,咱們還得認清這個方法的局限和可能有的缺點,像對特定類別雜訊適應能力不行,或者對參數設定太敏感之類的。

在未來工作展望這塊兒,咱們能聊聊對提出來的方法進行改進以及擴充套件的方向。就比如說,咱們能琢磨更復雜的神經網絡架構,或者引入別的深度學習模型,以此來進一步提升增強的效果。另外呢,咱們可以研究把這個方法用到多通道語音增強或者即時語音增強這類場景裏。咱們還能探尋在其他相關領域的運用,像語音辨識、語音合成啥的。透過對未來工作的展望,能給後續的研究帶來有價值的指導和啟發。
在這一節,咱們要好好分析和探討一下實驗結果,也展望一下未來工作的走向。全面評估實驗結果和方法後,就能清楚知道這個研究的貢獻和不足。這能給後續的研究和套用打下基礎,推動語音增強領域向前發展。
【結論】
本研究就是要給出一種把精確比率掩碼(ARM)和深度神經網絡(DNN)結合起來的單聲道語音增強辦法。靠設計基於理想比率掩模的精確比率掩碼,憑借振幅譜之間的歸一化互相關系數,就能精準地估摸出幹凈語音跟雜訊的比率關系。並且,用深度神經網絡做語音增強,能夠學會復雜的語音特點和非線性對映,讓增強效果變好。
咱們在實驗裏用了有幹凈語音、雜訊以及帶噪語音的數據集來做評估。透過定量還有定性的評估,把所提出方法的增強效果做了個全面的評估。另外,咱們還剖析了 ARM 和 DNN 對增強效果產生的影響,也探討了這個方法的優點和局限之處。
首先,把精確比率掩碼跟深度神經網絡相結合,咱們提出了一種管用的單聲道語音增強辦法。這辦法能在時頻域裏精準估量幹凈語音和雜訊的比率關系,再借助深度神經網絡來增強語音,進而提升語音的質素和可理解性。
其次,咱們經過實驗進行評估和分析,證實了所提出來的方法是有效的,還很優越。和傳統方法一對比,這提出來的方法在訊噪比變好、語音失真的程度以及語音清晰度這些指標方面,有了很明顯的進步。
最後,這項研究給單聲道語音增強這方面的研究帶來了新的想法和辦法。借助 ARM 與 DNN 的結合,咱們展示了怎麽依靠振幅譜相似性以及深度學習模型去提升語音增強的效果,給有關研究做了個借鑒和參考。
總的來講,本研究的主要工作與成果在提升語音增強的效果和效能方面相當重要,給後續的研究和套用給予了強大支撐,也推動了語音增強這個領域的進步。











