
展望下一代AI算力,是講堂新書【對話時代】的上海場研討講座,第二天為北京場
【導讀】10月19日上午,由文匯講堂和北大博雅講壇聯合承辦,上海市算力網絡協會、北京大學出版社、上海圖書館聯合主辦的「展望下一代算力暨【對話時代】新書研討講座上海場」在上圖東館成功舉辦,近10萬人次觀看直播。現經整理,分主講和對話予以刊發。此為主講篇。

李根國現場演講,分析和展望下一代算力 李念拍攝
進入資訊時代,作為數碼經濟底座的算力小則影響個人套用體驗,中則影響城市數碼經濟的發展,大則關乎國家之間的競爭和人類文明行程,因此是一個大家頗為關註的話題,也是我們上海超級計算中心一個重要的科普內容。今天從三方面和大家一起探討:一是當前對算力的巨大需求;二是算力面臨的挑戰;三是下一代算力展望。
AI熱點對算力的需求
自從ChatGPT問世後,人工智能界的熱點話題已經成為全社會的關註。我們先來看看最近的AI界三大熱點,從個案來了解算力的需求側。
*熱點一:
物理諾獎給神經網絡研究者,全社會對AI高度認可
2024年諾貝爾物理學獎授予霍普菲爾德(Hopfield)和辛頓(Hinton),以表彰他們「推動利用人工神經網絡進行機器學習做出的基礎性發現和發明」。霍普菲爾德建立了一種可以儲存和重建資訊的結構,辛頓發明了一種可以獨立發現數據內容的方法,這種方法對於目前使用的大型人工神經網絡至關重要。這表明,人工智能得到了人類社會的高度認可。

霍普菲爾德(Hopfield)和辛頓(Hinton)獲諾貝爾物理獎
霍普菲爾德和辛頓所做的貢獻跨越了科學和電腦界,特別是辛頓,此前已獲得「圖靈獎」,此次因人工智能領域的貢獻而獲諾貝爾獎,是各行各業對其成就的高度認可,同時也表明,人工智能就是人類未來各個領域發展的一個方向。
眾所周知,人類與其他動物的區別是,人類會制造工具、利用工具。電腦剛被發明時就認為是人類大腦的延伸,是人類智力的體現。
1946年出現了真正意義上的現代電腦。現代電腦是基於圖靈計算理論和馮諾伊曼體系結構,當時圖靈就預測20世紀末電腦會產生智能,提出了「圖靈測試」,實際上直到2014年,美國才做出第一台透過了「圖靈測試」的電腦。何為「圖靈測試」?就是將一個人和機器放到兩個黑屋子中,由另一人對他們進行一些問題測試,如果分不出人和電腦,就認為電腦透過了測試。GPT和ChatGPT都透過了圖靈測試。問題是,早在電腦誕生時就預測它會產生智能,但為何花費了近70年才得到實作?

2015年,「Alpha狗」戰勝柯潔,標誌著大規模算力才能發展人工智能 圖源【新民周刊】
人工智能自1950年代發展起來就特別熱門,提出了用神經網絡的方法來研究。後來發現算力太差無法開展,當時電腦速度只有每秒幾千次、上萬次。1980年代提出了神經網絡新演算法,但算力仍然不夠。直至2015年谷歌開發出會下圍棋的「Alpha狗」(AlphaGo),才標誌著新一輪的人工智能的發展。從這個方面來看,計算速度對人工智能的發展是最重要的決定性因素。只有大規模的算力才能發展人工智能,比如目前最新的GPT-4o1,之後的發展都需要大規模的算力支持。
*熱點二:
蛋白質結構預測表明科學範式變化,AI廣泛滲透
今年的諾貝爾化學獎授予了大衛·貝克(David Baker)、戴米斯·哈薩比斯(Demis Hassabis)和約翰·江珀(John Jumper),以表彰他們在蛋白質設計和蛋白質結構預測領域做出的貢獻。在蛋白質結構預測領域,三位引領者成果顯著。大衛·貝克建立出精確的AI預測工具RoseTTAFold,預測了約80%的蛋白質-配體復合物。戴米斯·哈薩比斯和約翰·江珀發明了預測蛋白質三維結構的革命性技術——Alpha折疊(AlphaFold)。

諾貝爾化學獎垂青Alpha折疊發明者
傳統研究方式是物理實驗結合超級計算。國內兩位海歸科學家施一公和顏寧就是運用物理實驗方法研究蛋白質結構,利用冷凍電鏡觀察蛋白質結構,並在美國和中國都發表了許多高質素的文章,成果顯著,很快就評上了院士。谷歌公司最新釋出的AlphaFold是用AI做蛋白質結構預測的。
這些科學家都在做同一件事,但能看出一些明顯區別,用人工智能的AlphaFold會做得很快,一次性就能預測出幾十種蛋白質的結構,這叫概率計算——大致是這樣的情況,但不能準確得出結果。真正的科學計算基於超級電腦,能預測出蛋白質結構,但這需要精確計算。這是兩種不同的方法。人工智能計算和超算的區別就在於,一個是概率計算,另一個是精確計算。當然,最終的科學研究還是要落實到實驗,真正物理上能夠實作,才能確認有蛋白質結構。例如醫藥研究方面,許多病理的研究都基於蛋白質結構的研究。
因此,今年的諾貝爾化學獎授予蛋白質結構的發現,標誌著整個科學界的認可,也意味著當前科學研究的範式發生了變化。之前的科學研究基於大量的實驗觀察,後來是實驗觀察與計算相結合,現在是以大數據和人工智能相結合的科學研究,這是一個非常重要的研究方法前進演化。
諾貝爾獎的頒發,更多的是喚醒人們對AI超預期發展和廣泛滲透性的重視,增加人們對AI推動人類社會跨越式發展的期望。
*熱點三:
「馬斯克周」:無人駕駛車、機器與人互動、筷子夾火箭
馬斯克創新不斷,其推特釋出星艦的「筷子夾火箭」獲得成功
10月7日-13日被稱為「馬斯克周」,為什麽呢?
(1)10月11日,馬斯克釋出了無人駕駛出租車CyberCab(無監督FSD),顛覆了人類對車的概念的理解。
(2)10月11日,馬斯克釋出能跟人互動的Optimus機器人。
(3)10月13日,馬斯克麾下的太空探索技術公司(SpaceX)新一代重型運載火箭「星艦」第五次試飛成功,並在這一過程中實作了技術上的重大突破——首次嘗試用發射塔的機械臂(形象地被稱為「筷子」)在半空中捕獲助推器以實作回收並取得成功。從成本、效率等各方面都可以看到,馬斯克對AI的套用是超前的。
*新藥研發AI設計周期可從5-6年提至1-2年
正是因為有這些工作展現,在社會各行業,無論是商業、金融、制造業、社會治理,還是醫療、教育、科研、服務等領域都在訓練AI大模型,基於大模型展開套用。舉例來說,在藥物研究領域,原來釋出一款新藥一般需要5至10年,現在新藥周期大規模縮減,方法就是基於數據預測。
具體做法是,第一步,先用計算預測蛋白質的結構,無論人的功能細胞還是病體的病毒結構,都要透過這個實驗或者計算來預測。這個工作目前已與人工智能結合起來,如AlphaFold已經釋出到第六版了,它是一個開源的軟件來預測正常細胞或是病體。然後,再去找新研究的藥物或已有的基藥,透過實驗和電腦測試這些藥對這個結構(靶體)是否有用。依靠人工智能收集的大量數據,可以在較短的時間內觀察小分子藥對病體的反應,以得出是否有用的結論。過去做這項實驗可能需要5-6年時間,但現在利用AI可能在一年或更短時間內就能完成第一步工作。
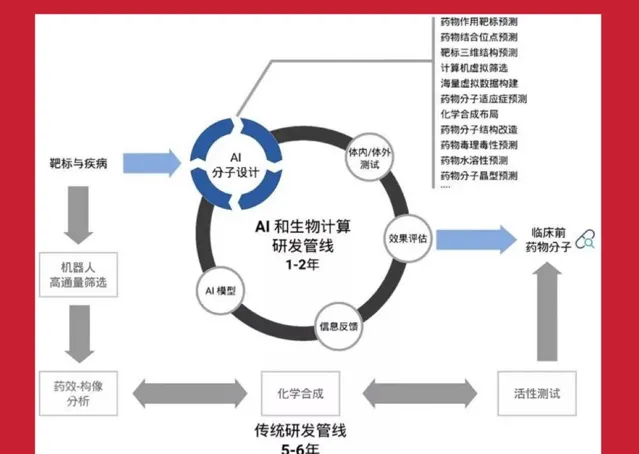
新藥研發由於AI介入大大縮短時間
第二步要進入臨床測試。所有的新藥必須經過臨床一期、二期確定安全後才能投放使用。人工智能在臨床測試過程中也有許多幫助,主要是透過人工智能進行大量數據的對比和大批次數據處理。特別是前三年的疫情期間,美國與中國都在快速研究一些應對新冠的特效藥,出藥的時間比過去快多了。可以說,人工智能發展之後,極大提升了生物醫藥研發速度。
*大模型對算力需求為何增長很快?
人工智能的三要素包括算力、數據、演算法。其中演算法相對固定,數據也比較清晰,有大規模的數據才能訓練數據,然後產生智能。
現在已經總結出三者的關系,所謂的規模定律(Scaling Law),意思是我們做每一個訓練的數據、大模型參數和所需的算力,按照算力等於6倍的數據量,再乘以參數量這樣一個關系。例如,GPT-4是一個萬億參數的大模型,它的數據量也是萬億token(token是一個很小的單位把數據都分割開),那麽2個萬億級乘起來再乘以6,大概是一個10的25次方的量級。這個量級是什麽概念呢?現在所謂的E級機,也就是目前最快的超級電腦,它的算力是10的18次方,稱作「E級」,那麽從E級到10的25次方還差7個數量級,所以計算量就是靠大規模的機器長時間的計算來實作。例如,GPT-4執行的是2萬張A100 GPU卡,在上面訓練了90天。所以說關鍵是算力。大模型對算力的需求增長得非常快。
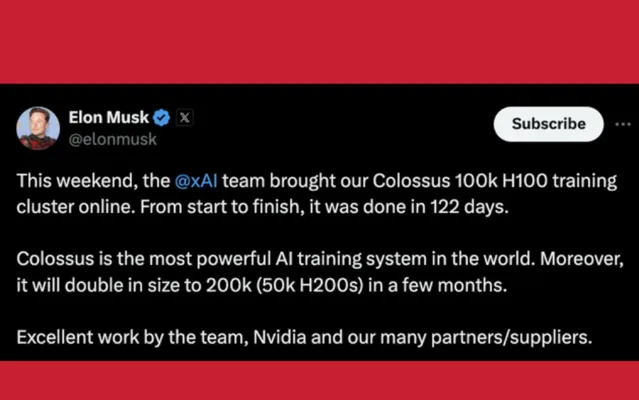
馬斯克推特釋出有關最快AI算力集群新聞
馬斯克在今年上半年構建了一個基於GPU的最快算力系統,用10萬張p00 GPU卡構成的AI集群系統來支撐他的自動駕駛和機器人。構建這樣規模的機器,造價約40億美元,每年功耗150兆瓦,電費高達1.2億美元。如果國內要構建一個10萬張規模能力的卡,假設美元與人民幣等值,基本上也要花人民幣40億元,每年耗電約1.2億元。
*10萬卡集群規模建設即超算建設決定著各國算力實力
從超級電腦的角度來看,GPT就是一個典型的分布式和平行計算的套用。因為H系列、A系列的GPU卡是一個全能卡,超算、智算都可以做。受到美國的限制,國內許多常見的算力卡受到很大的限制,只能有16位元或32位元,這種情況下的GPU就只能做人工智能的大數據處理。所謂「智能算力」是國內的一種說法,國際上通常的說法是「AI超級電腦」,因為它本來做的就是一個超級電腦的套用。從整個機器來看,AI超級電腦原本就由10萬張卡堆在一起,那麽怎麽把它們堆到一起?真正核心的其實是互聯技術,能把上萬張卡放到一起,做同一個題目,能夠穩定計算至少幾個小時。
因此,超級電腦的難度不在於GPU卡本身,而在於這個系統,所以各國都特別重視超級電腦的發展。特別是美國。例如,美國國家計劃5年內投資2800億美元以保持美國在芯片和計算技術領域的領先地位;歐盟計劃提供12億歐元資金用於「歐洲共同利益重要計劃——下一代雲基礎設施和服務」;日本經濟產業省擬為5家日本企業提供總額725億日元的補貼,用於打造人工智能超級電腦。
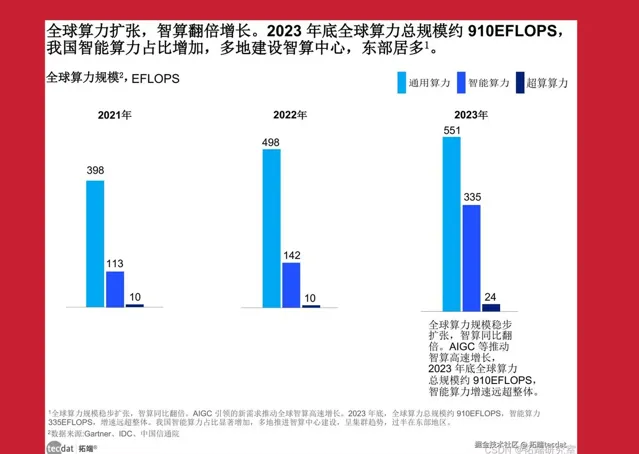
智算規模在2023年增速達136%
從國際上看,美國和中國在人工智能領域有大規模發力的建設。一方面,美國是由政府引導,頭部公司發力。例如,Meta、微軟&OpenAI、馬斯克的xAI等多家AI巨頭公司陸續宣布或者完成10萬卡集群規模建設。據IDC統計,預計2022年至2032年全球人工智能產業規模的復合增長率高達42%,2032年將達到1.3萬億美元。至2023年底,全球算力總規模約為910EFlops,增長40%,智能算力規模達到335EFlops,增長達136%。
算力的發展與國家的實力密切相關,與GDP走勢呈正相關。例如,算力發展較為迅速的美國和中國,GDP的體量也處於領先地位,屬於第一梯隊。日本、德國、法國、意大利等GDP在世界上占比較高的已開發國家,屬於第二梯隊。其他發展中國家,以及規模較小的國家則屬於第三梯隊。
*中國算力建設加速,從「東數西算」到全國一體化算力網
算力代表新質生產力。2022年12月,國務院印發的【「十四五」數碼經濟發展規劃】提出,到2025年,數碼經濟核心產業增加值占GDP比重達到10%的重要發展目標。2023年,中共中央、國務院印發了【數碼中國建設整體布局規劃】,其中明確提出,數碼中國建設按照「2522」的整體框架進行布局。
數碼戰略的實施標誌著中國從工業社會進入資訊化社會。目前上海走在數碼城市發展的前列,全國各地的發展差距較大。2021年5月,國家發展改革委、中央網信辦、工業和資訊化部、國家能源局聯合印發了【全國一體化大數據中心協同創新體系算力樞紐實施方案】。2022年1月,國家發展改革委提出,中國布局八大算力網絡國家樞紐節點,實施「東數西算」工程,支撐大規模算力排程,構建形成以數據流為導向的新型算力網絡格局。2023年12月25日,又釋出了【深入實施「東數西算」工程,加快構建全國一體化算力網的實施意見】,提出了加快構建全國一體化算力網。
國家發展改革委等多部門釋出構建全國一體化算力網的實施意見
「東數西算」工程部署了8個樞紐節點,京津冀、長三角、粵港澳和成渝地區等4個資訊化發達地區,主要負責套用算力。內蒙古、甘肅、寧夏、貴州等4個欠發達地區作為供給方,提供綠電並轉化成算力。自2023年起至2024年6月底,八大國家樞紐節點直接投資超過435億元,拉動投資超過2000億元。各級地方政府把數碼產業作為支柱產業發展,投入巨大。當然也給許多地區的經濟帶來了特別的發展。
國內三大電訊供應商、互聯網公司三巨頭BAT(百度、阿裏巴巴、騰訊),以及其他算力公司,都建設了萬卡以上規模的算力來支撐中國的人工智能發展。
AI算力面臨的挑戰
大模型等人工智能的快速發展對算力有著強大的需求,資本和社會力量投入也日益增長,那麽,大眾期盼的算力為何不能如願匹配呢?
*效率低下:集成電路自身限制和生態體系不完整
一方面,現代電腦受結構體系限制,存在「記憶體墻」「功耗墻」「IO墻」等集成電路固有瓶頸,導致計算效率整體水平低。國內問題更加突出,涉及AI超級電腦配置、系統架構、演算法最佳化等諸多問題,導致GPU算力利用率低於50%。另一方面,許多AI計算方法是通用的,從需求來看,希望能用最好的人工智能器材來保障大模型訓練執行暢通。但由於美國方面的限制,中國許多自主算力的相容性較差,生態體系不夠完整,許多演算法叠代的速度較慢,某些方面還不夠先進,使得整個計算效率又打了一個折扣。

主講之後,上海市算力網絡協會專家們展開討論,專家會員沈巍(中)主持,商湯科技大裝置事業群生態執行總監劉遠輝(右)和上海超算中心高效能計算部部長王濤參與
*能耗浪費:散熱成本、數據搬運功耗、數據中心折舊
一方面,集成電路本身的特性使得其自身發熱,這就是電力浪費,還要給其配置制冷器材,把它的熱量帶出去,這就是二次浪費。電腦中數據的傳輸成本非常高,例如,想從北京拷個數據到上海,可以透過網絡傳輸,但是一旦達到P級(1PB=1024TB)或者再大規模的數據,網絡傳輸的成本和速度就遠遠不如直接派人去北京把數據拷到硬碟裏帶回上海的速度和成本。事實上,微觀的數據傳輸成本,即從一個CPU傳到另一個CPU的成本也是最高的。有一個預測,當半導體工藝達到7納米時,數據搬運功耗占總功耗的63.7%。也就是說,電腦裏真正耗能的主要是數據的傳遞,在超級電腦裏數據的同步和傳輸也是最花時間和電力的。
演算法設計也是最重要的工作。例如平行計算。其實人類所有的工作都適合序列計算。到目前為止,電腦也無法自動實作平行計算,還需要人工介入把任務分配好。所以,真正的計算難度在於把電腦裏這些成千上萬個核同步調動起來,讓它們幹一件事情,這也需要耗能。
另一方面,宏觀上可能要建立許多數據中心。一個器材至少使用5至8年才會更新或淘汰,老舊器材對能耗消耗也相當大。據國內統計,近5年中國算力中心的耗電量基本達到15%的增長速度,高於中國的GDP增速。整個數據中心的耗能占總耗電量的5%至6%。2023年全國數據中心總耗電量已經達到1500億度。

對電腦的散熱,液冷是目前的解決方案
對於電腦的能耗,我們現在還只能做一些外圍工作。對於如何降低電腦本身的電耗,目前還無解,就看下一代電腦是否有革命性的突破。目前算力中心采取了最先進的液冷,將整個電腦放到一種特殊的液體中進行制冷,但建設成本很高,初期的一次性投入非常大。如果把制冷液也計入成本,那從投資的角度來說,根本就沒有節省。另一種方法是用所謂的綠電,如太陽能、水利發電,這種方法的汙染相對較少。此外,最近也有觀點提出把機器建到月球上。小規模的機器可以操作,但大規模的機器難以實作,因為機器本身十幾兆、百兆瓦的耗電量,在月球上難以解決。所以,能耗問題是電腦非常頭疼的一個問題。
*多樣性需求提升和計算架構單一矛盾
人類需要電腦解決各種各樣的問題,不論是場景環境還是種類需求都日益增多,但是電腦結構單一,解決方案就是一個單一結構或固定結構,電腦很難有一個動態的變化來適應人類的問題。對此,電腦科學家也在努力探索。
新一代AI算力展望
雖然挑戰很大,但諸多方面都在展開攻關。我們可以展望下一代算力的前景。
*硬件創新:NPU、TPU、FPGA芯片、ASIC芯片

5月15日,谷歌釋出了第六代TPU芯片Trillium
從電腦硬件來看,在提高演算法在機器裏的效率上已釋出一些新架構,如華為釋出的人工智能專用處理單元NPU(Neural-network Processing Unit),即嵌入式神經網絡處理器,就是針對人工智能升級網絡設計的效能更優的芯片。谷歌向量計算也在做自己的TPU(Tensor Processing Unit,張量處理單元)芯片,還有使用場景更加靈活的FPGA(Field-Programmable Gate Array,現場可編程門陣列)芯片,以及針對特定套用領域的ASIC(Application-Specific Integrated Circuit,套用型專用集成電路)芯片。這些芯片結構可以提高我們解決問題的效率,但是通用性會差一些。幸好針對人工智能的演算法是一個特定的演算法,可以提高效率。
*軟件創新:演算法改變較難,軟硬件結合為佳
從軟件的角度出發,現在的計算方法與硬件的匹配關系較差,所以現在也在改變演算法,但是演算法也不容易改變。辛頓從1980年代就開始研究人工智能的摺積神經網絡演算法,盡管人工智能有許多演算法的設計,但本質上不可能在短期內有更大突破,所以要將軟硬件兩者結合起來,盡可能提高效率。
*新型顛覆式電腦:存算一體、量子計算、生物儲存、腦機介面
我們暢想、展望下一代顛覆式新型電腦。
生物儲存是模仿人體的蛋白質結構原理展開
一是模擬人腦進行數據傳輸和運算的存算一體機。人腦本身就儲存了許多資訊,運算時只需要把兩個神經元連線到一起。存算一體是打破馮·諾依曼結構的一個全新發展方向,目前也有一些成果。
二是量子計算。從電腦的角度看,我們期望量子計算的誕生,為電腦帶來革命性的巨大發展。量子計算也有許多方法,如超導計算,在環境溫度冷卻到負273度的情況下產生超導,然後建立電腦基礎。還有光子、微中子陷阱等方式。該領域目前國內也在積極研究,希望能夠創造出顛覆性的成果。
三是生物儲存。現在的儲存還是集成電路,未來希望電腦能夠模擬人類進行蛋白質結構儲存。這方面目前也在進行一些實驗,但距離投入使用還很遙遠。
四是腦機介面。這也是一個新的發展方向。一般來說,將一個小學生培養到博士,至少需要20年時間。一旦腦機介面研究成功,可能幾小時之內就把小學到博士階段的知識一下子灌輸到人腦中了。腦機介面距離臨床使用還有很遠的距離,目前更多的研究是針對癱瘓病人,用一個芯片與人腦的神經直接對接上,然後把訊號傳遞出來,或者將外部的訊號輸入到人腦中。但是人腦結構特別復雜,其中的血管不能觸碰,容易造成損傷。所以這也是一個極具想象力,能夠從根本上解決我們的知識學習和套用的一個方向。

上圖中心聽眾濟濟一堂,對新話題充滿探索熱情,近10萬人次觀看直播 孫科拍攝
不論是量子計算、生物儲存還是腦機介面,現在美國的研究是走在我們前面的,但中國也在各個方面積極布局,希望在新一代科學技術和工業等方面的發展中,能夠走在世界前列。
整理:金夢 李念
作者:李根國(上海超算中心主任)
文:李根國圖:嘉賓PPT及網絡 朱梅全整理編輯:李念責任編輯:李念
轉載此文請註明出處。











