
概述
這篇論文提出了一種名為視覺模組外掛程式多模態檢索模型(MARVEL),它學習了一個嵌入空間,用於對查詢和多模態文件進行檢索。MARVEL使用統一的編碼器模型對查詢和多模態文件進行編碼,這有助於減少影像和文本之間的模態差異。具體來說,我們透過將視覺模組編碼的影像特征作為輸入,增強了訓練有素的密集檢索器T5-ANCE的影像理解能力。為了促進多模態檢索任務,我們基於ClueWeb22數據集構建了ClueWeb22-MM數據集,該數據集將錨文本視為查詢,並從錨連結的網頁中提取相關的文本和影像文件。我們的實驗表明,MARVEL在多模態檢索數據集WebQA和ClueWeb22-MM上顯著優於最先進的方法。MARVEL提供了一個機會,將文本檢索的優勢擴充套件到多模態場景。此外,我們還展示了語言模型具有提取影像語意的能力,並能將部份影像特征對映到輸入詞嵌入空間。
論文地址:
https://arxiv.org/pdf/2310.14037
程式碼地址:
https://github. com/OpenMatch/MARVEL
01
Multi-Modal Retrival
隨著互聯網和多模態內容的增長,越來越多的瀏覽器或應用程式能夠更輕松地返回相關內容給使用者。
多模態檢索任務的目標是根據使用者查詢從多模態源(如影像和文本)中檢索文件。它側重於查詢和多模態文件之間的相關性建模,而不是文本-影像匹配。在某些場景中,使用影像來回答查詢可能更為合適,如左圖所示。
例如,對於「誰是圖靈」的查詢,它不僅返回文本,還可能提供影像。主要檢索方法有兩種:第一種是「分而治之」,就是分別進行圖片和文本檢索,然後采用某種方式如視覺語言模型合並檢索結果;第二種是使用統一的視覺-語言模型進行綜合檢索。

現有的通用視覺-語言密集檢索模型學習了一個用於多模態文件的通用嵌入空間,允許它在不同模態之間搜尋候選項。然而,在編碼過程中,文本和影像使用不同的編碼器。為了縮小模態差異,UNIVL-DR將影像特征轉化為文本,以增強原始文本空間中的影像文件。
本文中,作者旨在解決這樣一個問題:能否建立一個統一的多模態的編碼模型,將多模態資訊對映到統一的三維空間中,以緩解不同編碼器帶來的模態差異。

02
Multi-modAl Retrieval model with MARVEL
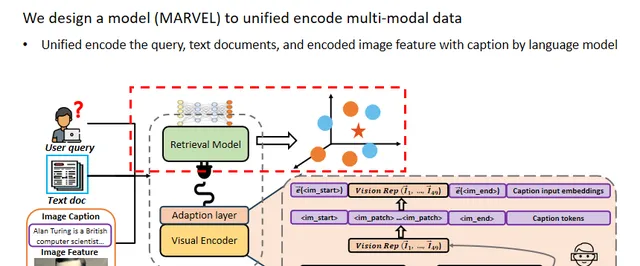
在這篇工作中,作者設計了一個多模態檢索模型MARVEL,透過視覺模組外掛程式,統一編碼影像和文本文件以及查詢,以減輕影像和文本之間的模態差異。
文中使用外掛程式視覺模組對影像特征進行編碼並對映到語言模型空間。具體來說,使用CLIP的視覺編碼器來編碼影像特征,並使用一個適配層將視覺表示投影到密集檢索模型的詞嵌入空間,然後將視覺表示和影像標題詞嵌入進行拼接。
此外,本文使用兩個特殊標記和來指示影像特征的開始和結束。
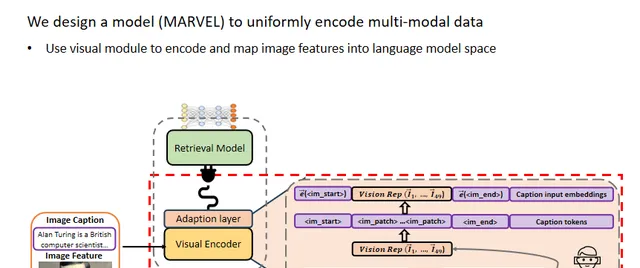
隨後,將影像特征和標題的聯合嵌入輸入到語言模型中,以獲得影像文件的表示。
對於查詢和文本文件,作者直接使用語言模型對它們進行編碼。最終,查詢、影像文件和文本文件都被對映到一個通用的嵌入空間中,以進行多模態密集檢索。
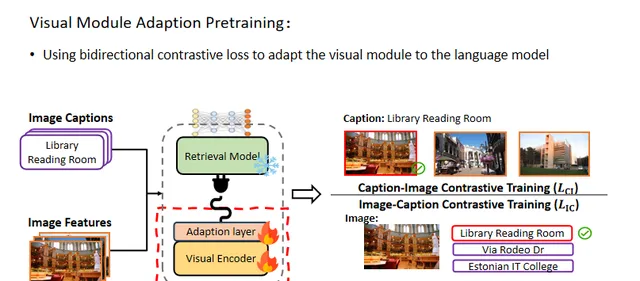
在預訓練階段,本文遵循先前的工作,將影像和標題都視為查詢,以計算雙向對比學習損失,這有助於透過聯合損失對齊影像和文本的模態。在整個過程中,僅更新視覺編碼器和適配層的參數,以使視覺模組適應語言模型。
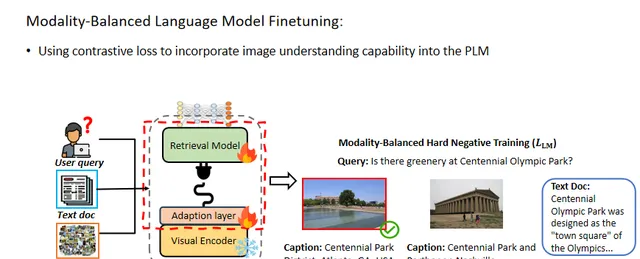
在微調階段,作者凍結視覺編碼器的參數並更新其他參數。為了減輕模態歧視問題並將影像理解能力整合到語言模型中,本文采用了模態平衡的硬負樣本訓練方法,以對齊查詢與正樣本候選項,並引導模型選擇正確的模態,並保證嵌入空間的統一。
03
ClueWeb22-MM Dataset
此外,為了促進多模態檢索任務,作者基於ClueWeb22構建了ClueWeb22-MM數據集,其規模與現有的開源數據集WebQA相匹配。
文中將錨文本視為查詢,並將連結網頁中的相應影像或文本文件視為其最佳的相關文件。
本文使用ClueWeb22-MM和WebQA數據集進行微調和推理,並使用從ClueWeb22數據集中提取的影像-標題對進行預訓練。相應的統計數據在右側的表格中展示。

04
Overall Performance
本文首先評估了MARVEL和現有模型的整體檢索效能。
與主要基線UniVL-DR相比,MARVEL在兩個數據集上的檢索效率都有顯著提高,證明了使用通用模型緩解模態差異的有效性。
此外,如圖中所示,當使用者詢問「在‘和平與繁榮’中可以找到哪兩種動物?」時,MARVEL可以直接提供一幅名為「和平與繁榮」的畫作,幫助使用者回答這個問題。

05
Effectiveness of Fusion Strategies
關於視覺-語言模型的融合方法,作者測試了三種不同的模態融合策略:外掛程式式(plugin)、拼接(concatenation)和求和(sum)。
拼接和求和方法分別對影像和標題進行編碼,然後將嵌入向量進行拼接或求和,以獲得最終的表示。
本文實驗表明,外掛程式式方法可以透過聯合建模文本和影像來緩解模態差異,並透過語言模型的註意力頭促進影像和文本之間的更深層次互動,從而實作最佳的檢索結果。
06
Effectiveness of Visual Module Adaption Pretraining
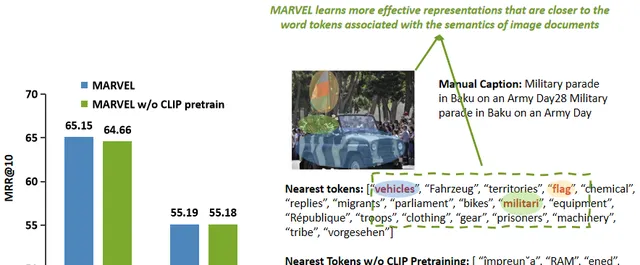
為了驗證視覺模組適配預訓練的有效性,本文在兩個數據集上測試了模型的檢索效能。
透過視覺模組預訓練,MARVEL的檢索能力得到了顯著增強,這為將視覺模組適配到語言模型提供了一些機會。

然後,取視覺模組編碼的影像向量,並使用余弦相似度來找到它們最接近的詞元。
如圖中所示,透過視覺模組預訓練,MARVEL學習了更有效的表示,這些表示更接近影像的語意。它從影像中捕獲了更細粒度的語意資訊,例如車輛、旗幟和軍事。
相比之下,未經預訓練的模型只能捕獲影像中描繪的國家的資訊。
07
Effectiveness of Finetuning Strategies
然後,作者在文本/影像/多模態檢索任務上進行了實驗,以展示四種不同微調策略的有效性。在這四種策略中,適配層始終會被更新。
當僅微調T5的參數時,MARVEL在影像和多模態檢索任務上取得了顯著的改進,特別是與其他模型相比,這證明了MARVEL在將視覺模組適配到密集檢索模型上的強能力。

01
Conclusion
本文提出了一個多模態檢索模型MARVEL。透過使用視覺模組外掛程式,作者透過通用建模減輕了影像和文本之間的模態差異,將文本檢索模型的優勢引入到了多模態檢索任務,並在兩個數據集ClueWeb22-MM和WebQA上都達到了最佳水平
本文的預訓練和微調方法使語言模型能夠有效地提取影像語意,並將影像特征部份對映到語言詞嵌入空間。
此外,作者構建了一個多模態檢索基準ClueWeb22-MM,以進一步推進多模態檢索領域的發展。











